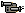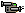|
|
Visual attention
To benefit communication and social learning, it is important that
both robot and human find the same sorts of perceptual features
interesting. Otherwise there will be a mismatch between the sorts of
stimuli and cues that humans use to direct the robot's attention
versus those that attract the robot's attention. For instance, if
designed improperly it could prove to be very difficult to achieve
joint reference with the robot. Even if the human could learn what
attracts the robot's attention, this defeats the goal of allowing the
person to use natural and intuitive cues. Designing for the set of
perceptual cues that human infants find salient allows us to implement
an initial set that are evolutionary significant for humans.
Kismet's attention system acts to direct computational and behavioral
resources toward salient stimuli and to organize subsequent behavior
around them. In an environment suitably complex for interesting
learning, perceptual processing will invariably result in many
potential target stimuli. Its critical that this be accomplished in
real-time. In order to determine where to
assign resources, the attention system must incorporate raw sensory
saliency with task-driven influences.
The attention system is shown below and is
heavily inspired by the Guided Search v2.0 system of Wolfe.
Wolfe proposed this work as a model for
human visual search behavior. We have extended it to account for
moving cameras, dynamically changing task-driven influences, and
habituation effects.

The robot's attention is determined by a combination of
low-level perceptual stimuli. The relative weightings of the stimuli
are modulated by high-level behavior and motivational influences. A
sufficiently salient stimulus in any modality can pre-empt attention,
similar to the human response to sudden motion. All else being equal,
larger objects are considered more salient than smaller ones. The
design is intended to keep the robot responsive to unexpected events,
while avoiding making it a slave to every whim of its environment.
With this model, people intuitively provide the right cues to direct
the robot's attention (shake object, move closer, wave hand,
etc.). Displayed images were captured during a behavioral trial
session.
|
The attention system is a two stage system. The first stage is a
pre-attentive, massively parallel stage that processes information
about basic visual features (i.e., color, motion, depth cues, etc.)
across the entire visual field. For Kismet,
these bottom-up features include highly saturated color, motion, and
colors representative of skin tone.
The second stage is a limited
capacity stage which performs other more complex operations, such as
facial expression recognition, eye detection, or object
identification, over a localized region of the visual field. These
limited capacity processes are deployed serially from location to
location under attentional control. This is guided by the properties
of the visual stimuli processed by the first stage (an exogenous
contribution), by task-driven influences, and by habituation
effects (both are endogenous contributions). The habituation influence
provides Kismet with a primitive attention span. For Kismet, the
second stage includes an eye-detector that operates over the foveal
image, and a target proximity estimator that operates on the stereo
images of the two central wide field of view cameras.
All four factors influence the direction of Kismet's gaze. This in
turn determines the robot's subsequent perception, which ultimately feeds
back to behavior. Hence the robot is in a continuous cycle of behavior
influencing what is perceived and perception influencing subsequent
behavior.

Manipulating the robot's attention. Images on the top row
are from Kismet's upper wide camera. Images on the bottom summarize
the contemporaneous state of the robot's attention system. Brightness
in the lower image corresponds to salience; rectangles correspond to
regions of interest. The thickest rectangles correspond to the
robot's locus of attention. The robot's motivation here is such that
stimuli associated with faces and stimuli associated with toys are
equally weighted. In the first pair of images, the robot is attending
to a face and engaging in mutual regard. By shaking the colored
block, its salience increases enough to cause a switch in the robot's
attention. The third pair shows that the head tracks the toy as it
moves, giving feedback to the human as to the robot's locus of
attention. The eyes are also continually tracking the target more
tightly than the neck does. In the fourth pair, the robot's attention
switches back to the human's face, which is tracked as it moves.
|


The effect of gain adjustment on looking preference: Circles
correspond to fixation points, sampled at one second intervals. On
the left, the gain of the skin tone filter is higher. The robot
spends more time looking at the face in the scene (86% face, 14%
block). This bias occurs despite the fact that the face is dwarfed by
the block in the visual scene. On the right, the gain of the color
saliency filter is higher. The robot now spends more time looking at
the brightly colored block (28% face, 72% block).
|
|