|
|
Low-level Visual Features
Kismet's low-level visual perception system extracts a number of
features that human infants seem to be particularly responsive
toward. These low-level features were selected for their ability to
help Kismet distinguish social stimuli (i.e. people, that is based on
skin tone, eye detection, and motion) from non-social stimuli
(i.e. toys, that is based on saturated color and motion), and to
interact with these stimuli in interesting ways (often modulated by the
distance of the target stimulus to the robot). There are a few
perceptual abilities that serve self-protection responses. These
include detecting looming stimuli as well as potentially dangerous
stimuli (characterized by excessive motion close to the robot).
Kismet's low-level visual features are as follows:
- Highly saturated color: red, blue, green, yellow.
- Colors representative of skin tone.
- Motion detection.
- Eye detection.
- Distance to target.
- Looming.
- Threatening, very close, excessive motion.
One of the most basic and widely recognized visual features is color.
Our models of color saliency are drawn from the complementary work on
visual search and attention from (itti-saliency). The incoming video
stream contains three 8-bit color channels (r, g, and b) which are
transformed into four color-opponency channels (r', g', b', and y').
Each input color channel is first normalized by the luminance l (a
weighted average of the three input color channels). These normalized
color channels are then used to produce four opponent-color channels.
The result is a 2-D map where pixels containing a bright, saturated
color component (red, green, blue, and yellow) increases the intensity
value of that pixel. We have found the robot to be particularly
sensitive to bright red, green, yellow, blue, and even orange.
Motion Saliency Map
In parallel with the color saliency computations, another processor
receives input images from the frame grabber and computes temporal
differences to detect motion. Motion detection is performed on the
wide field of view, which is often at rest since it does not move with
the eyes. This raw motion map is then smoothed. The result is a
binary 2-D map where regions corresponding to motion have a high
intensity value.
Skin tone map


The skin tone filter responds to 4.7% of possible (R,G,B)
values. Each grid element in the figure to the left shows the
response of the filter to all values of red and green for a fixed
value of blue. Within a cell, the x-axis corresponds to red and the
y-axis corresponds to green. The image to the right shows the filter
in operation. Typical indoor objects that may also be consistent with
skin tone include wooden doors, cream walls, etc.
|
Colors consistent with skin are also filtered for. This is a
computationally inexpensive means to rule out regions which are
unlikely to contain faces or hands. A large fraction of pixels on
faces will pass these tests over a wide range of lighting conditions
and skin color. Pixels that pass these tests are weighted according
to a function learned from instances of skin tone from images taken by
Kismet's cameras.
Eye Detection
Developed by Aaron Edsinger
(edsinger@ai.mit.edu).

Caption: Performance of eye detection. Sequence of foveal images with
eye detection. The eye detector actually looks for the region between
the eyes. It has decent performance over a limited range of distances
and face orientations. The box indicates a possible face has been
detected (being both skin toned and oval in shape). The small cross
locates the region between the eyes.
|
Eye-detection in a real-time robotic domain is computationally
expensive and prone to error due to the large variance in head
posture, lighting conditions and feature scales. Our methodology
assumes that the lighting conditions allow the eyes to be
distinguished as dark regions surrounded by highlights of the temples
and the bridge of the nose, that human eyes are largely surrounded by
regions of skin color, that the head is only moderately rotated, that
the eyes are reasonably horizontal, and that people are within
interaction distance from the robot (3 to 7 feet).
Proximity
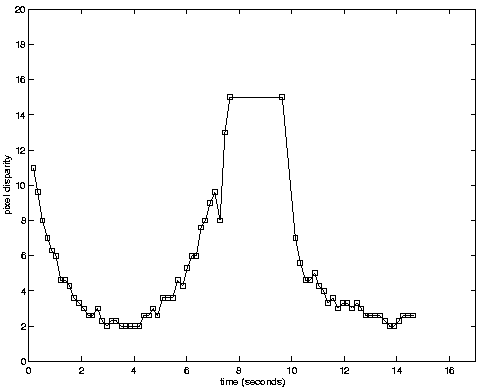
Caption: Distance metric.
|
Given a target in the visual field, proximity is computed from a stereo match
between the two wide cameras. The target in the central wide camera is
located within the lower wide camera by searching along epipolar lines for
a sufficiently similar patch of pixels, where similarity is measured using
normalized cross-correlation. This matching process is repeated for a
collection of points around the target to confirm that the correspondences
have the right topology. This allows many spurious matches to be
rejected.
Loom Detection
The loom calculation makes use of the two cameras with wide fields of
view. These cameras are parallel to each other, so when there is nothing
in view that is close to the cameras (relative to the distance between
them), their output tends to be very similar. A close object, on the
other hand, projects very differently on to the two cameras, leading to a
large difference between the two views.
By simply summing the pixel-by-pixel differences between the images
from the two cameras, we extract a measure which becomes large in the
presence of a close object. Since Kismet's wide cameras are quite far
from each other, much of the room and furniture is close enough to
introduce a component into the measure which will change as Kismet
looks around. To compensate for this, the measure is subject to rapid
habituation. This has the side-effect that a slowly approaching
object will not be detected - which is perfectly acceptable for a loom
response.
Threat Detection
A nearby object (as computed above) along with large but concentrated
movement in the wide fov is treated as a threat by Kismet. The amount
of motion corresponds to the amount of activation of the motion map.
Since the motion map may also become very active during ego-motion, this
response is disabled for the brief intervals during which Kismet's
head is in motion. As an additional filtering stage, the ratio of
activation in the peripheral part of the image versus the central part
is computed to help reduce the number of spurious threat responses due
to ego-motion. This filter thus looks for concentrated activation in a
localized region of the motion map, whereas self induced motion causes
activation to smear evenly over
Low Level Auditory Features
Kismet's low-level auditory perception system extracts a number of
features that are also useful for distinguishing people from other
sound emitting objects such as rattles, bells, and so forth. The
software runs in real-time and was developed at MIT by the Spoken
Language Systems Group (www.sls.lcs.mit.edu/sls). Jim Glass and
Lee Hetherington were tremendously helpful in tailoring the code for
our specific needs and in assisting us to port this sophisticated
speech recognition system to Kismet. The software delivers a variety
of information that is used to distinguish speech-like sounds from
non-speech sounds, to recognize vocal affect, and to regulate vocal
turn-taking behavior. The phonemic information may ultimately be used
to shape the robot's own vocalizations during imitative vocal games,
and to enable the robot to acquire a proto-language from long term
interactions with human caregivers. Kismet's low level auditory
features are as follows:
- sound present
- speech present
- time stamped pitch tracking
- time stamped energy tracking
- time stamped phonemes
|