|
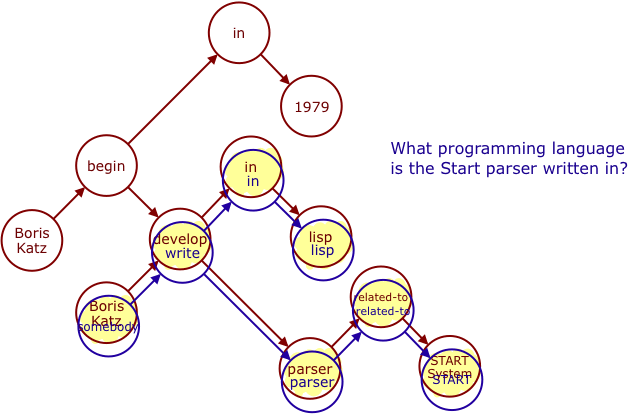
Human agents are known for having "Theory of Mind (ToM)" ability to infer others’ mental states, e.g. intention and belief. Some early studies suggest language development help ToM reasoning.In this project, we aim to build a vision and language system, which learns and understands the world like a child. The way it understands other agents’ intent is from its interpretation of visual perceptions. Here, the interpretation is the other agent’s plan to achieve her goal (i.e. ground perception in planning) and the system can describe and evaluate this interpretation in natural language.We know humans formulate complex goals and we know those goals are influenced by language. So, this project is both an effort to shed light on the fundamentals of human planning and how we conceive about plans and at the same time an effort to understand videos at a higher, more human-like, level.
|