|

The Hardware DesignKismet is an expressive robotic creature with perceptual and motor modalities tailored to natural human communication channels. To facilitate a natural infant-caretaker interaction, the robot is equipped with visual, auditory, and proprioceptive sensory inputs. The motor outputs include vocalizations, facial expressions, and motor capabilities to adjust the gaze direction of the eyes and the orientation of the head. Note that these motor systems serve to steer the visual and auditory sensors to the source of the stimulus and can also be used to display communicative cues.
Our hardware and software control architectures have been designed to meet the challenge of real-time processing of visual signals (approaching 30 Hz) and auditory signals (8 kHz sample rate and frame windows of 10 ms) with minimal latencies (less than 500 ms). The high-level perception system, the motivation system, the behavior system, the motor skill system, and the face motor system execute on four Motorola 68332 microprocessors running L, a multi-threaded Lisp developed in our lab. Vision processing, visual attention and eye/neck control is performed by nine networked 400 MHz PCs running QNX (a real-time Unix operating system). Expressive speech synthesis and vocal affective intent recognition runs on a dual 450 MHz PC running NT, and the speech recognition system runs on a 500 MHz PC running Linux.
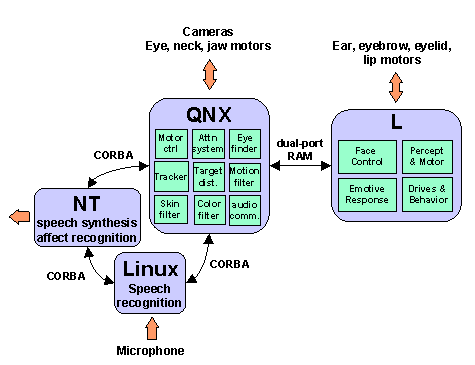
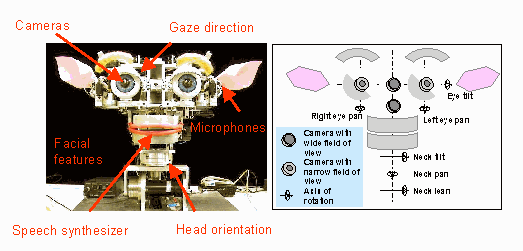
Vision SystemThe robot's vision system consists of four color CCD cameras mounted on a stereo active vision head. Two wide field of view (fov) cameras are mounted centrally and move with respect to the head. These are 0.25 inch CCD lipstick cameras with 2.2 mm lenses manufactured by Elmo Corporation. They are used to decide what the robot should pay attention to, and to compute a distance estimate. There is also a camera mounted within the pupil of each eye. These are 0.5 inch CCD foveal cameras with an 8 mm focal length lenses, and are used for higher resolution post-attentional processing, such as eye detection.Kismet has three degrees of freedom to control gaze direction and three degrees of freedom to control its neck. The degrees of freedom are driven by Maxon DC servo motors with high resolution optical encoders for accurate position control. This gives the robot the ability to move and orient its eyes like a human, engaging in a variety of human visual behaviors. This is not only advantageous from a visual processing perspective, but humans attribute a communicative value to these eye movements as well.
Auditory SystemThe caregiver can influence the robot's behavior through speech by wearing a small unobtrusive wireless microphone. This auditory signal is fed into a 500 MHz PC running Linux. The real-time, low-level speech processing and recognition software was developed at MIT by the Spoken Language Systems Group. These auditory features are sent to a dual 450 mHz PC running NT. The NT machine processes these features in real-time to recognize the spoken affective intent of the caregiver.
Expressive Motor SystemKismet has a 15 DoF face that displays a wide assortment of facial expressions to mirror its ``emotional'' state as well as to serve other communicative purposes. Each ear has two degrees of freedom that allows Kismet to perk its ears in an interested fashion, or fold them back in a manner reminiscent of an angry animal. Each eyebrow can lower and furrow in frustration, elevate upwards for surprise, or slant the inner corner of the brow upwards for sadness. Each eyelid can open and close independently, allowing the robot to wink an eye or blink both. The robot has four lip actuators, one at each corner of the mouth, that can be curled upwards for a smile or downwards for a frown. There is also a single degree of freedom jaw.Vocalization SystemThe robot's vocalization capabilities are generated through an articulatory synthesizer. The underlying software (DECtalk v4.5) is based on the Klatt synthesizer which models the physiological characteristics of the human articulatory tract. By adjusting the parameters of the synthesizer it is possible to convey speaker personality (Kismet sounds like a young child) as well as adding emotional qualities to synthesized speech (Cahn 1990).
|
||||||||||||||||||