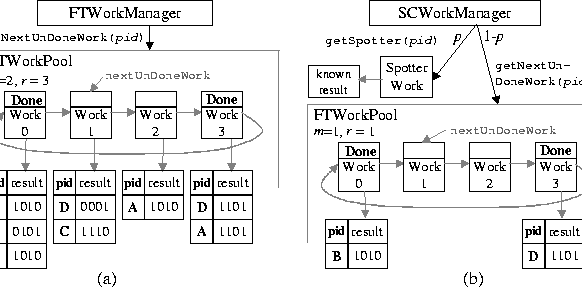
By extending the eager scheduling work manager and work pool objects
as shown in Fig. 5, we have implemented two approaches
to protecting against faults and sabotage: majority voting and
spot-checking.
Majority voting works by requiring that at least a majority m of up to r results from different workers for the same work object have the same value. We implement it by using a new subclass of MWWorkPool, FTWorkPool, where the done flag of a work object remains unset as long as a majority agreement has not been reached and less than r results from different PIDs have been received. If r results are received without reaching a majority agreement, all the r results are invalidated, and the work object is redone. In Fig. 5(a), for example, works 0 and 3 have reached a majority agreement and are marked done, while works 1 and 2 are still considered undone.
Spot-checking, shown in Fig. 5(b), works as follows: at the beginning of each new batch of work, the SCWorkManager (a subclass of FTWorkManager) randomly selects a work object from the work pool and precomputes its result. Then, whenever a work engine calls getWork(), the work manager returns this spotter work with probability p. In this way, the work manager can check the trustworthiness of a worker by comparing the result it returns with the known result. If the results do not match, the offending worker is blacklisted as untrustable, and the work manager backtracks through all the current results, invalidating any results dependent on results from the offending worker.
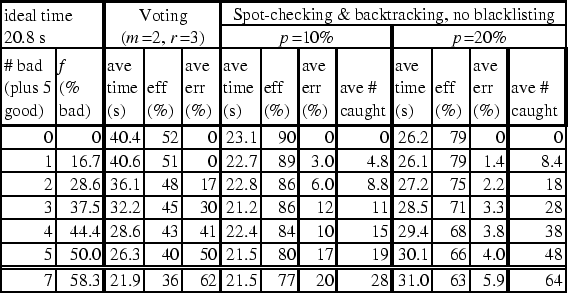
Table 1 shows results from using these two fault-tolerance mechanisms. In this experiment, we created a saboteur work engine that always corrupts results in a fixed way. We then ran the Mandelbrot application on the spiral range (see Sect. 5.3.1), with 5 good workers and a varying number of saboteurs. To keep the pool of saboteurs from being completely eliminated in spot-checking, we disabled blacklisting, and allowed caught nodes to reconnect after a 1 second delay. For each configuration, we ran 10 rounds, measuring the average running time and the average error rate (![]() ). From these, we computed the efficiency of each configuration by first multiplying the ideal time (measured with 5 good workers, no saboteurs and no fault-tolerance) by the fraction of correct answers
). From these, we computed the efficiency of each configuration by first multiplying the ideal time (measured with 5 good workers, no saboteurs and no fault-tolerance) by the fraction of correct answers ![]() , and then dividing the result by the actual running time. This estimates how efficiently the good workers are being utilized towards producing correct final answers.
, and then dividing the result by the actual running time. This estimates how efficiently the good workers are being utilized towards producing correct final answers.
Majority voting performed as expected, having an error rate close to the theoretical expected value of f2(3-2f) for 2-out-of-3 voting (where f is the fraction of workers who are saboteurs, and where we assume that saboteurs agree on their answers). Although this error rate is large for the values of f shown, it should improve significantly in more realistic situations where f is small, since it is proportional to f2. The bigger problem with voting is its efficiency, which, as shown, is at best only about 50% since all the work has to be done at least twice even when there are no saboteurs. In this respect, spot-checking performed more promisingly. As shown, its efficiency loss was only about p when the number of saboteurs was small, and, thanks to backtracking, its error rates remained relatively low - even when there were more saboteurs than good workers. In a real system where blacklisting is enabled, we can expect even lower error rates. As shown, saboteurs were being caught at a high rate - as many as 64 saboteurs every 31s in one case. This means that unless saboteurs can somehow assume a very large number of false identities (e.g., by faking IP addresses or digital certificates) and switch between them dynamically and quickly - a highly unlikely scenario - they would quickly get eliminated, and the error rate would decrease rapidly in time.
Although very encouraging, these results are clearly just the beginning of much theoretical, experimental, and developmental research that can be done in this area. Some research questions include how well spot-checking would work in cases where saboteurs do not always give bad answers, and how we can avoid unnecessarily blacklisting ``innocent'' nodes that just suffer temporary glitches. The most important challenge, however, is that of applying these mechanisms in real applications. Spot-checking may be sufficient for some classes of applications where a small percentage of bad answers may be acceptable, or can be screened out. These include image rendering, where a few scattered bad pixels would be acceptable, some statistical computations, where outliers can be detected and either ignored or double-checked, and genetic algorithms, where bad results are naturally screened out by the system. Most scientific applications, however, assume 100% reliability. For these, it maybe useful to combine voting, spot-checking, backtracking, and blacklisting to shrink the error rate as much as possible. In the future, we also plan to explore the use of traditional and novel security mechanisms such as checksums, digital signatures, encrypted computation, and dynamic obfuscation [13] to reduce the error rate further by making it difficult for saboteurs to falsify results in the first place.