The current master-worker programming model implementation employs
a simple form of adaptive parallelism sometimes called
eager scheduling [4].
As shown in Fig. 4, each work object has a done
flag which is set when a worker returns the result for that object.
The work objects are stored in a circular list, with
a pointer keeping track of the next available uncompleted work.
In Figure 4(a), for example, the nextUnDoneWork pointer is pointing to work 3 after works 1 and 2 have been assigned to engines A and B respectively. Thus, when engine C calls getWork(), it receives work 3.
Since workers call getWork() as soon as they finish their current work,
faster workers will tend to call getWork() more often,
and will thus get a bigger share of the total work. In this way, we get a simple form of dynamic load balancing.
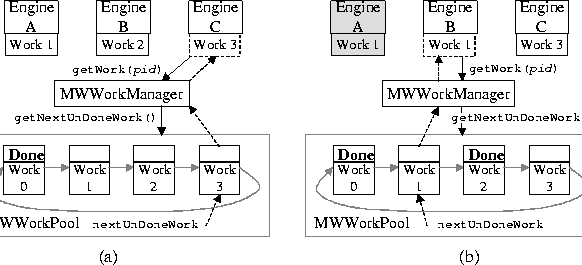 |
Moreover, since the list is circular, nextUnDoneWork can eventually wrap around and point to previously assigned but uncompleted work, allowing a piece of work to be reassigned to other workers. This ``eager'' behavior guarantees that slow workers do not cause bottlenecks - fast workers with nothing left to do will simply bypass slow ones, redoing work themselves if necessary. It also provides a basic form of crash-tolerance. In Fig. 4(b), for example, we see that when B finishes work 2 and calls getWork(), it receives work 1, which has not been marked done because A has crashed (or is simply slow). In this way, computation can go on as long as at least one processor is still alive. In fact, even if all the processors crash, the computation can continue as soon as a new processor becomes available.
Currently, we are also examining other forms of adaptive parallelism that can be used with the master-worker programming model. For example, we have written MultiWorkEngine and MultiWorkManager subclasses that implement a getMultiWork() function for prefetching multiple packets of work, and have used them in our distributed web-crawler application to improve performance by hiding communication latency [14]. We are also using them to study the effects of changing work sizes depending on worker speeds.