Antonio Torralba
Delta Electronics Professor of Electrical Engineering and Computer Science.
Head AI+D faculty, EECS dept. (link)
Computer Science and Artificial Intelligence Laboratory
- Dept. of Electrical Engineering and Computer Science
Massachusetts Institute of Technology
Office: 32-386G
32 Vassar Street,
Cambridge, MA 02139
Email: torralba@mit.edu
Assistant: Fern DeOliveira Keniston
My research is in the areas of computer vision, machine learning and human visual perception. I am interested in building
systems that can perceive the world like humans do. Although my work focuses on computer vision I am also interested in other modalities such as audition and touch. A system able to perceive the world through multiple senses might be able to learn without requiring massive curated datasets. Other interests include understanding neural networks, common-sense reasoning, computational photography, building image databases, ..., and the intersections between visual art and computation.
Book
 Foundations of Computer Vision
Foundations of Computer Vision
with Phillip Isola and Bill Freeman
MIT press
Our book is finished!
Lots of things have happened since we started thinking about this book in November 2010; yes, it has taken us more than 10 years to write this book.
Our initial goal was to write a large book that provided a good coverage of the field. Unfortunately, the field of computer vision is just too large for that. So, we decided to write a small book instead, limiting each chapter to no more than five pages. Writing a short book was perfect because we did not have time to write a long book and you did not have time to read it. Unfortunately, we have failed at that goal, too.
This book covers foundational topics within computer vision, with an image processing and machine learning perspective. The audience is undergraduate and graduate students who are entering the field, but we hope experienced practitioners will find the book valuable as well.
News
 2020 - Named the head of the faculty of artificial intelligence and decision-making (AI+D). AI+D is a new unit within EECS, which brings together machine learning, AI and decision making, while keeping strong connections with its roots in EE and CS. This unit focuses on faculty recruiting, mentoring, promotion, academic programs, and community building.
2020 - Named the head of the faculty of artificial intelligence and decision-making (AI+D). AI+D is a new unit within EECS, which brings together machine learning, AI and decision making, while keeping strong connections with its roots in EE and CS. This unit focuses on faculty recruiting, mentoring, promotion, academic programs, and community building.
 2018 - 2020 MIT Quest for intelligence: I have been named inaugural director of the MIT Quest for Intelligence. The Quest is a campus-wide initiative to discover the foundations of intelligence and to drive the development of technological tools that can positively influence virtually every aspect of society.
2018 - 2020 MIT Quest for intelligence: I have been named inaugural director of the MIT Quest for Intelligence. The Quest is a campus-wide initiative to discover the foundations of intelligence and to drive the development of technological tools that can positively influence virtually every aspect of society.
 2017 - 2020 MIT IBM Watson AI lab: named the MIT director of the MIT IBM Watson AI lab.
2017 - 2020 MIT IBM Watson AI lab: named the MIT director of the MIT IBM Watson AI lab.
Gallery
Here there are some art projects I like expending time on. Most of them are inspired by some of our research projects.
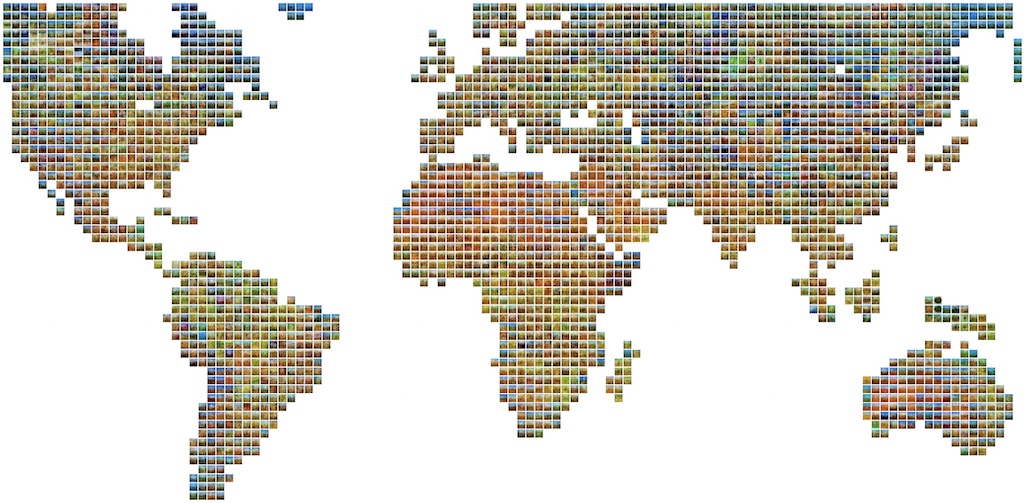
 Average World - 2014 - 2020
Average World - 2014 - 2020
2 panels clay 60 x 121 cm each, images mounted on wooden cubes 1.9cm
Images are averaged according to GPS locations. Each cell contains the average of 150 images taken at that location. Images come from Flickr. Each average shows the colors typical of that region of the world. We can appreciate the green regions in south america, red in the Sahara, ...
Each average image is mounted on a wooden cube 1.9cm and attached to a clay panel. The final map will have 4 pannels and more than 3000 cubes. I am working on the third pannel ...


 Periodic Table - 2018
Periodic Table - 2018
Images mounted on wooden cubes 1.9cm
Each image shows the average of the images download from a Google query with the name of each element in the periodic table. The name of the element appears in the average because some of the returned images contain the element symbols. Many of the colors are close to the actual color of the element. Some of the heaviest elements have never been photographied, so this is a fun Google-prediction of how they might look. Each image is mounted on a wooden cube 1.9cm.
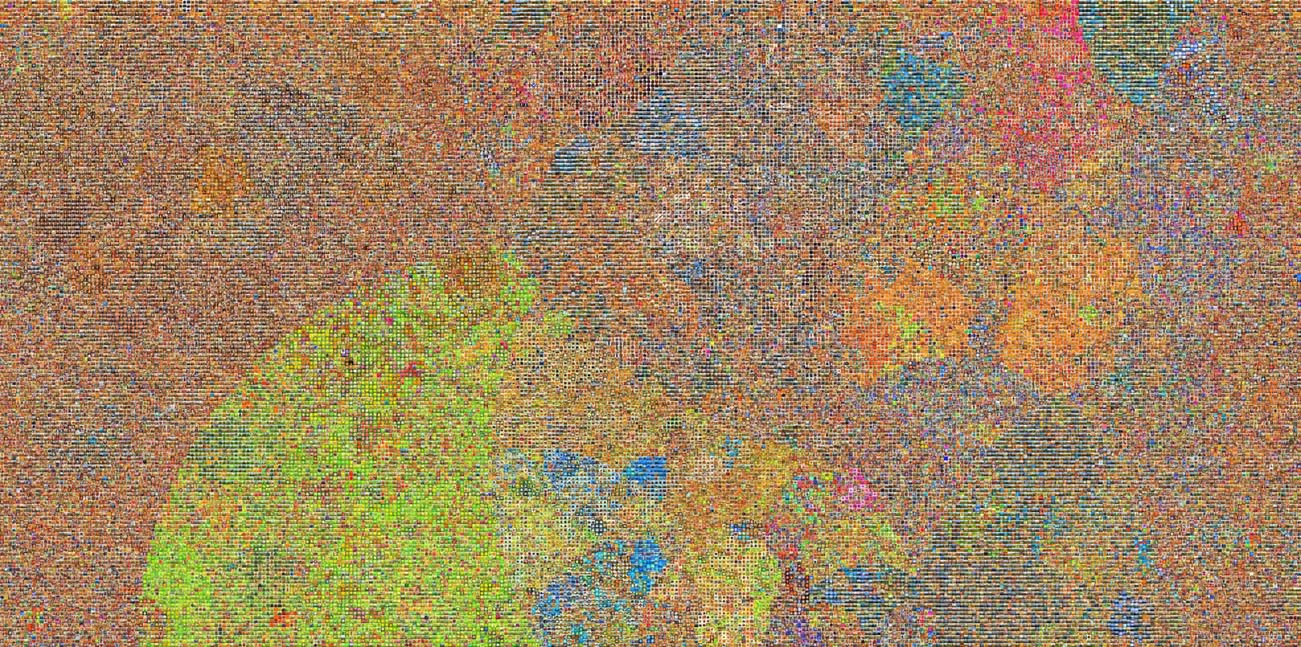 Visual Dictionary - 2008
Visual Dictionary - 2008
Each of the tiles in the mosaic is an arithmetic average of images relating to one of 53,464 nouns. Words are placed in the array using the wordnet hierarchy (nearby tiles correspond to similar concepts). The images for each word were obtained using Google’s Image Search and other engines. Each tile is the average of 140 images. The average reveals the dominant visual characteristics of each word. For some, the average turns out to be a recognizable image; for others the average is a colored blob.
 Accidental image in Pedraza, Spain - 2013
Accidental image in Pedraza, Spain - 2013
Picture of a bedroom processed by Retinex to enhance the illumination component. The enhanced illumination image has a strong chromatic component. The illumination image is produced by light entering by a window on the opposite wall (not visible in the photograph). Therefore, it is an upside-down image of the scene outside the window and it clearly shows the blue of the sky, and the green patch of the grass on the ground outside the window.



 Noise or Texture - 2013
Noise or Texture - 2013
Where is the noise, in the image or in the world? The left image is corrupted by additive noise. We do not perceive this scene as being composed by objects covered with a strange form of paint. Instead, we see that there is noise and it is not supposed to be there. In the second image, we do not perceive the random texture as being noise despite the strong similarities with the first image.
 Multiple blob personalities - 2008
Multiple blob personalities - 2008
In presence of image degradation (e.g. blur), object recognition is strongly influenced by contextual information. Recognition makes assumptions regarding object identities based on its size and location in the scene.
 Sailboat in Charles River (fall) - 2005
Sailboat in Charles River (fall) - 2005
Pictures are aligned on one sailboat. All the pictures contain the same sailboat taken within a few minutes apart.
 Sailboats in Charles river (spring) - 2005
Sailboats in Charles river (spring) - 2005
This superposition contains multiple sailboats. All the images are shifted and scaled so that the boats are roughly aligned.
 Average Caltech 101 - 2003
Average Caltech 101 - 2003
Average of 100 of the objects from the Caltech-101 dataset.
 Average of people in Cambridge -
2003
Average of people in Cambridge -
2003
Average images are created by adding together many pictures.
Image averaging has been used by artists such as Jason Savalon, Jim Campbell among several other artists. I used average images to motivate the study of context models in computer vision and to illustrate that the influence of an object in an image extends beyond its boundaries. Before averaging, each picture is translated and scaled so that a particular object is in the center of the picture. Average images aligned on a single object that occupies a small portion of the picture can reveal additional regions beyond the boundaries of the object that provide meaningful contextual structure for supporting it.

 Car and pedestrian - 2001
Car and pedestrian - 2001
In presence of image degradation (e.g. blur), object recognition is strongly influenced by contextual information. Recognition makes assumptions regarding object identities based on its size and location in the scene. In this picture subjects describe the scenes as (left) a car in the street, and (right) a pedestrian in the street. However, the pedestrian is in fact the same shape as the car except for a 90 degrees rotation. The non-typicality of this orientation for a car within the context defined by the street scene makes the car be perceived as a pedestrian. Without degradation, subjects can correctly recognize the rotated car due to the sufficiency of local features.















 March 2022, I was awarded the
March 2022, I was awarded the 
 The
The  German TV science show on
German TV science show on