In a full system, there are many classifiers. How are the classifiers learned?
Initially the learner has no classifiers. The learner must acquire the classifiers from example words presented to it. We assume a sequence of words is presented to the learner. Each presentation of a word triggers an event that fills the data registers with the appropriate sound, grammar, and meaning information. If the learner can fill in the details of the word without error, then it proceeds to the next word. The learner might fail either because there are not any applicable classifiers or because competing classifiers fight to assert inconsistent values in the registers. In the first failure situation, a new rote-classifier is created to remember the bit patterns in the data registers. In the second failure situation, the fighting classifiers are incrementally refined.
We decompose the learning problem into two subproblems: (1) the classification of rote-classifiers into correlation types, and (2) the summarization of rote-classifiers to produce rule-classifiers. Summarization becomes much easier when it only needs to account for relevant classes of correlations instead of all possible correlations (which might include exceptions). The flowchart in Figure 5 depicts the top-level actions of the learning procedure.
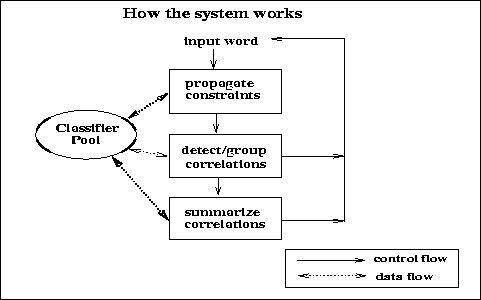
Figure 5: Top-level flowchart for learning classifiers
Let us consider a simple example to illustrate the basic operations of
the learning procedure.![]() (See Figure 6.)
Suppose that to begin with the learner has no classifiers and is
presented four noun pairs and one verb pair in random order: cat/cats
(See Figure 6.)
Suppose that to begin with the learner has no classifiers and is
presented four noun pairs and one verb pair in random order: cat/cats
[k.ae.t.s], dog/dogs [d.).g.z], duck/ducks
[d.^.k.s], gun/guns [g.^.n.z], and go/went
[w. ![]() .n.t]. A rote-classifier is created for each of the
words.
.n.t]. A rote-classifier is created for each of the
words.

Figure 6: Learning of classifiers consists of two steps: (1) Grouping
of rote-classifiers into correlation types (middle column), and (2)
Generalizing rote-classifiers belonging to the same correlation type
(right column). In this example, the initial classifier pool has 10
rote-classifiers (shown in an abbreviated form in the left column).
The rote-classifiers are divided into two
correlation types. The first correlation type (relating a common noun and its
plural) has 8 rote-classifiers. Each rote-classifier is labeled
with a plus to indicate that it is the plural form or a minus to
indicate the singular form. The learner finds a rule-classifier whose
sound pattern (right column) covers all positive examples and avoids
the negative ones. The second correlation type (relating a verb stem
and its past) has two rote-classifiers. The learner will not
generalize this group of classifiers until more such examples have
been accumulated.
The learner notices correlations among pairs of rote-classifiers. For example, the pair of rote-classifiers cat and cats correlates the change in the plural bit with the left-shift of the rote-classifier-cat phoneme bits and the appending of a terminal [s]. The 10 rote-classifiers are divided into two groups: the first one is related to changes in the plural bit, and the second to changes in the past-tense bit.
The learner then attempts to summarize the rote-classifiers in the first correlation group. It looks for a general description of the phoneme bit pattern that covers all the rote-classifiers with the [+plural] feature (the positive example) and avoids all the ones with [-plural] feature (the negative examples). A description is said to cover an example if the example is consistent with all the conditions in the description.
Starting with the phoneme bits of a rote-classifier as the initial
description, the generalization algorithm performs a specific-to-general
search in the space of possible descriptions.![]() For example, an initial
description, the seed, might be the phoneme bits for ``cats.'' The
seed is a bit vector of 56 bits (14 bits for each of the 4 phonemes
[k.ae.t.s]), which can be thought of as a logical conjunction of
boolean features:
For example, an initial
description, the seed, might be the phoneme bits for ``cats.'' The
seed is a bit vector of 56 bits (14 bits for each of the 4 phonemes
[k.ae.t.s]), which can be thought of as a logical conjunction of
boolean features:
01011001000000101001000011000100000111000001000001110101 <------ k ---><----- ae --><----- t ----><----- s ---->
The generalization space of possible phoneme bits for a classifier is
![]() , where n is the number of phoneme bits. (See
Figure 7.) For example the
generalization space for classifiers with four phonemes
contains
, where n is the number of phoneme bits. (See
Figure 7.) For example the
generalization space for classifiers with four phonemes
contains ![]() instances. To explore this huge space, the
generalization process relies on three search biases:
instances. To explore this huge space, the
generalization process relies on three search biases:
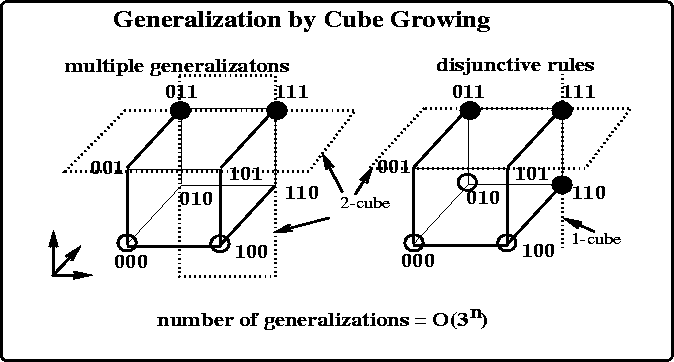
Figure 7: Classifier generalization as cube growing. A relation with
n boolean variables defines an n-dimensional instance space with
![]() possible instances. The positive examples (solid dots) and
negative examples (circles) occupy the vertices of an n-dimensional
cube. Generalization can be thought of as finding a collection of
m-cubes (
possible instances. The positive examples (solid dots) and
negative examples (circles) occupy the vertices of an n-dimensional
cube. Generalization can be thought of as finding a collection of
m-cubes ( ![]() ) covering the positive ones without
overlapping the negative ones. A 0-cube is a point, 1-cube is a
line, and so on. There may be multiple m-cubes that cover the same
positive examples (as shown by the two 2-cubes in the left diagram).
It may also require more than one m-cube to cover the positive
examples (as shown by the 1-cube and 2-cube in the right diagram).
The generalization algorithm uses a beam search with inductive biases
to find disjunctive generalizations.
) covering the positive ones without
overlapping the negative ones. A 0-cube is a point, 1-cube is a
line, and so on. There may be multiple m-cubes that cover the same
positive examples (as shown by the two 2-cubes in the left diagram).
It may also require more than one m-cube to cover the positive
examples (as shown by the 1-cube and 2-cube in the right diagram).
The generalization algorithm uses a beam search with inductive biases
to find disjunctive generalizations.
The generalization procedure is a beam search with a simple goodness function. A beam search is just like a best-first search except that it does not backtrack. The best k candidate generalizations are retained for further generalizations. The goodness of a cube is equal to the sum of Pc and Nc, where Pc is the number of positive examples the cube covers, and Nc is the number of negative examples it does not cover. To break ties in the goodness score, the search prefers larger cubes with higher Pc.
At each iteration the algorithm generates new candidate
generalizations by raising the phoneme bits (i.e. changing 0's and 1's
to don't cares), one or two bits at a time. The phonemes are ordered
by recency. The bits of the least recently heard phoneme are raised
first. The search terminates when either all positive examples are
covered or a negative example is covered.![]()
The search (with beam width k = 2) eventually produces a description G that covers all four positive examples and avoids all four negative examples. The description says that all positive examples end with either the [s] or [z] phoneme.
G: [dc.dc.dc.{s,z}]
The next step in the summarization process is to verify the
covering description.
The description G is overly general because applying it to the
negative examples gives not only the correct plural forms (such as
[k.ae.t.s]) but also incorrect ones (such as *[k.ae.t.z]). The
incorrect ones are treated as near misses (i.e., negative examples
that are slightly different from the positive ones). Basically the
learner assumes there is only one plural form for each noun. Since it
already knows [k.ae.t.s] is the correct one, [k.ae.t.z] must be wrong.
Near misses greatly speed up the discovery of
correct generalizations.![]()
The generalization algorithm is re-invoked with the addition of these new negative examples:
Seed : [k.ae.t.s]
Positive examples: [k.ae.t.s] [d.).g.z] [d.^.k.s] [g.^.n.z]
Negative examples: *[k.ae.t.z] *[d.).g.s] *[d.^.k.z] *[g.^.n.s]
[k.ae.t] [d.).g] [d.^.k] [g.^.n]
This time the search results in a disjunction of three generalizations G1, G2, and G3:
G1: [dc.dc.[-voice].s] G2: [dc.dc.[+voice,-strident].z] G3: [dc.dc.[+voice,-continuant].z]
The generalization G1 covers two positive examples: ``cats'' and
``ducks.'' G1 describes a correlation between the penultimate
voiceless phoneme and a terminal [s] phoneme. The generalizations G2
and G3 overlap in their coverings. They both cover the remaining two
positive examples: ``dogs'' and ``guns.'' The learner keeps both
generalizations because they have the same number of don't cares and
cover the same number of positive examples. G2 says that a terminal
[z] phoneme is preceded by a phoneme that has the [+voice] and
[-strident] features.![]() G3 correlates a terminal [z] phoneme with a
preceding voiced non-continuant.
G3 correlates a terminal [z] phoneme with a
preceding voiced non-continuant.![]() The three generalizations are verified
as before. However, this time the generalizations are consistent:
there are not any new exceptions or near misses. Note that after
seeing only 4 positive examples, the learner is able to acquire
constraints on the plural formation that closely resemble those found
in linguistics books[1].
The three generalizations are verified
as before. However, this time the generalizations are consistent:
there are not any new exceptions or near misses. Note that after
seeing only 4 positive examples, the learner is able to acquire
constraints on the plural formation that closely resemble those found
in linguistics books[1].
The summarization process then creates a rule-classifier to represent each consistent generalization. These rule-classifiers are now available for constraint propagation, and are subject to further refinement when new examples appear.