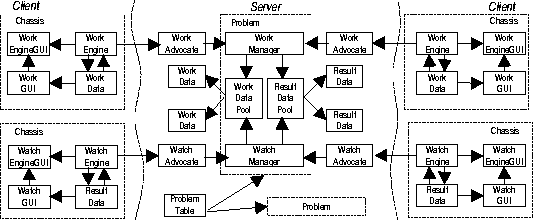
On the client side, an engine runs in its own thread, and takes care of receiving and processing data objects from its corresponding manager on the server. A work engine, for example, would take care of getting work data from the work manager, executing the work, and requesting more work when it's done. Data objects are generally polymorphic and know how to process themselves. To execute the work, a work engine passes the work data a pointer to itself, and calls the work data's process() method. The work data will compute itself, using the work engine to communicate with the work manager, if desired. Both the engine and the data have associated GUI objects which can be used for user interface. The engine and the GUIs are all contained in a chassis object, which can be an applet or application.
On the server side, an advocate object![]() serves as the engine's
representative and forwards the engine's calls to the manager.
The manager has access to several data pools. These pools
may be shared by other managers serving other purposes. In
Fig.1,
for example, the work and result pools are shared by the work and watch
managers, allowing the watch manager to watch the progress of the
computation and inform watch engines of such things as
new results and statistics. The whole set of associated managers
and data pools compose a problem. There may be many
independent problems existing in a server at the same time.
A problem table keeps track of these, and can be used
by volunteers to choose the problem they want to participate in.
serves as the engine's
representative and forwards the engine's calls to the manager.
The manager has access to several data pools. These pools
may be shared by other managers serving other purposes. In
Fig.1,
for example, the work and result pools are shared by the work and watch
managers, allowing the watch manager to watch the progress of the
computation and inform watch engines of such things as
new results and statistics. The whole set of associated managers
and data pools compose a problem. There may be many
independent problems existing in a server at the same time.
A problem table keeps track of these, and can be used
by volunteers to choose the problem they want to participate in.