As a second application, we decided to test the novel idea of using volunteer computing for communications-intensive applications by multiplying communication resources, rather than just computational power.
Consider a web crawler - i.e., an application that, given a web page, would follow links in the page, follow links in those links, etc., compiling a list of all pages and links found as it goes along, and possibly searching for particular information in these pages. Such an application is very communications-intensive since most of its time is spent downloading web pages from the network. Thus, even on a fast processor, crawling can take a long time if network bandwidth is limited. This gives us an idea: what if we can use volunteer computing to get other machines, with their own (possibly faster) network connections, to do the crawling for us?
To test this idea, we implemented a distributed web-crawling
application using the Bayanihan framework, and used it in the
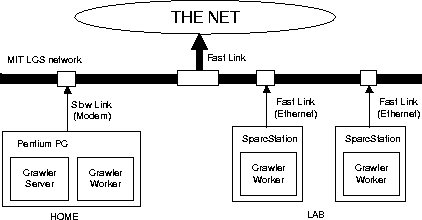
setup shown in Fig.8.
We simulated a slow network link by placing the user who wants
to do web crawling on a Pentium PC connected to the network
through a 28.8Kbps modem connection. Then, we compared the
results of having the user crawl the web directly through the modem,
and having another computer with a faster network link do the web
crawling as a worker client to the Bayanihan server on the PC.