 |
|
|
Latent-Dynamic
Discriminative Models for Continuous Gesture Recognition
| |
| Principal
Investigators: |
|
|
| Goal: |
| Many problems in vision involve the
prediction of a class label for each frame in an
unsegmented sequence. In this paper we develop a
discriminative framework for simultaneous sequence
segmentation and labeling which can capture both
intrinsic and extrinsic class dynamics. Our approach
incorporates hidden state variables which model the
sub-structure of a class sequence and learn the
dynamics between class labels. Each class label has
a disjoint set of associated hidden states, which
enables efficient training and inference in our
model. We evaluated our method on the task of
recognizing human gestures from unsegmented video
streams and performed experiments on three different
datasets of head and eye gestures. Our results
demonstrate that our model for visual gesture
recognition outperform models based on Support
Vector Machines, Hidden Markov Models, and
Conditional Random Fields. |
|
|
| Our
Approach: |
Visual gesture sequences tend to have
distinct internal sub-structure and exhibit
predictable dynamics between individual gestures.
For example, head-nod gestures have an internal
sub-structure that consists of moving the head up,
down then back to its starting position. Further,
the head-nod to head-shake transition is usually
less likely than a transition between a head-nod and
neutral gesture.
In this project, we introduce a new visual gesture
recognition algorithm which can capture both
sub-gesture patterns and dynamics between gestures.
Our Latent-Dynamic Conditional Random Field (LDCRF)
model is a discriminative approach for gesture
recognition. Instead of modeling each gesture
generatively (e.g., Hidden Markov Models), our LDCRF
model discovers latent structure that best
differentiates visual gestures. Our results show
that this approach can accurately recognize subtle
gestures such as head nods or eye gaze aversion.
Our approach offers several advantages over previous
discriminative models. In contrast to Conditional
Random Fields (CRFs), our method incorporates hidden
state variables which model the sub-structure of
gesture sequences. The CRF approach models the
transitions between gestures, thus capturing
extrinsic dynamics, but lacks the ability to learn
the internal sub-structure. In contrast to
Hidden-state Conditional Random Fields (HCRFs), our
method can learn the dynamics between gesture labels
and can be directly applied to label unsegmented
sequences.
Our LDCRF model combines the strengths of CRFs and
HCRFs by capturing both extrinsic dynamics and
intrinsic sub-structure. It learns the extrinsic
dynamics by modeling a continuous stream of class
labels, and it learns internal sub-structure by
utilizing intermediate hidden states. Since LDCRF
models include a class label per observation (see
Figure 1), they can be naturally used for
recognition on un-segmented sequences, overcoming
one of the main weaknesses of the HCRF model. By
associating a disjoint set of hidden states to each
class label, inference on LDCRF models can be
efficiently computed using belief propagation during
training and testing. Our results on visual gesture
recognition demonstrate that LDCRF outperforms
models based on Support Vector Machines (SVMs), HMMs,
CRFs and HCRFs.
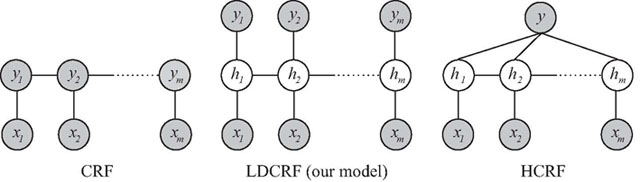
Figure 1: Comparison of our LDCRF model with two
previously published models: CRF and HCRF. In these
graphical models, xj represents the jth
observation (corresponding to the jth
frame of the video sequence), hj is a
hidden state assigned to xj, and yj
the class label of xj (i.e. head-nod or
other-gesture). Gray circles are observed variables.
The LDCRF model combines the strengths of CRFs and
HCRFs in that it captures both extrinsic dynamics
and intrinsic structure and can be naturally applied
to predict labels over unsegmented sequences. Note
that only the link with the current observation xj
is shown, but for all three models, long range
dependencies are possible. |
|
|
| Related
Publications: |
-
Louis-Philippe Morency, Ariadna Quattoni, and Trevor Darrell,
Latent-Dynamic
Discriminative Models for Continuous Gesture
Recognition,
Submitted to CVPR 2007.
- Louis-Philippe Morency,
Context-based Visual Feedback Recognition, PhD thesis, CSAIL
Technical report MIT-CSAIL-TR-2006-075, October 2006
- Ariadna Quattoni, Sybor Wang, Louis-Philippe Morency, Michael
Collins, and Trevor Darrell, Hidden-state Conditional Random Fields, IEEE
Transactions on Pattern Analysis and Machine Intelligence, accepted for
publication, 2006
- Sybor Wang. Ariadna Quattoni, Louis-Philippe Morency,
David Demirdjian, and Trevor Darrell,
Hidden
Conditional Random Fields for Gesture Recognition, Proceedings IEEE
Conference on Computer Vision and Pattern Recognition, June 2006
|
|
|
|
|
|
|
|
|
