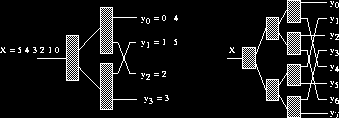
We are interested in developing highly robust shared data structures for ``multi-scale'' computation, the diverse set of distributed and concurrent computing environments that scale from tightly coupled multiprocessors, to farms of workstations and local area networks.
Traditionally, the design of concurrent data structures has centered around the notion of mutual exclusion: ensuring that only one process at a time is allowed to modify complex shared data objects, and that processes periodically wait for all others to complete a given part of code. A variety of techniques have been proposed for efficiently implementing mutual exclusion, ranging from low-level machine instructions to high-level language constructs. Nevertheless, we argue that mutual exclusion based coordination structures tend to be centralized and tightly synchronized, and are thus poorly suited for todays distributed and asynchronous networks and multiprocessor architectures. This drawback is amplified in applications requiring fault-tolerance and real-time performance.
For example, in a real-time system consisting of a pool of sensor and actuator processes, processes might communicate via a shared queue. When a sensor process detects a condition requiring a response, it records the condition and places the record in the queue. Whenever an actuator process becomes idle, it dequeues an item from the queue and takes appropriate action. Since there is only a single queue, we are guaranteed that idle processors will always find the next available record. The conventional way to prevent concurrent queue operations from interfering is to execute each operation as a critical section: only one process at a time is allowed to access the data structure. The resulting centralized and tightly synchronized coordination algorithm, although widely used, has several significant drawbacks.
As an example we breifly describe below our recent work on Diffracting Trees and Elimination Pools. Diffracting trees are a new distributed technique for shared counting and load-balancing, and elimination pools are a specialized variant of diffracting trees that give superior performance in structures such as shared queues. These structures have potential applications in both tightly-coupled multiprocessing and computer network environments.
It is easiest to think of a diffracting tree as a distributed way to implement a shared counter (see counting networks paper by J. Aspnes, M. P. Herlihy, and N. Shavit ). A diffracting tree is a balanced binary tree of simple one-input two-output computing elements called balancers that are connected to one another by wires. Tokens arrive on a balancer's input wire at arbitrary times, and are output on its two output wires. Intuitively one may think of a balancer as a toggle mechanism, that given a stream of input tokens, repeatedly sends one token to the left output wire and one to the right, effectively balancing the number of tokens that have been output. On a computer the balancer would require just a single bit directing the current passing token (``shepherded'' by a process) left or right, and complemented by each traversing token. To illustrate this ``counting'' property, consider an execution in which tokens traverse the tree sequentially, one completely after the other. The left-hand side of the figure below shows such an execution on a tree of width 4. As can be seen, the tree moves input tokens to output wires in increasing order modulo 4. Trees of balancers having this property can easily be adapted to count the total number of tokens that have entered the network. Counting is done by adding a ``local counter'' to each output wire i, so that tokens coming out of that wire are consecutively assigned numbers i, i+4, i+(4 * 2) ...
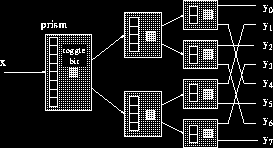
Though this structure is highly distributed, and tokens traverse it independently, it would seem that we are back to square one since the root balancer of the tree will be a a sequential bottleneck and source of contention that is no better than having a single centralized counter. This would indeed be true if the balancer were a bit toggled by each passing token. However, one can replace this construction with a more effective diffracting balancer implementation based on the following simple observation: if an even number of tokens pass through a balancer, once they leave the toggle bit's state is unchanged. That is, if it was 0 it will be 0 and if it was 1 it will be 1. Thus, by having pairs of tokens collide on independent locations in memory and then diffracted in a coordinated manner one to the left and one to the right, both tokens can leave the balancer without ever having to toggle the shared bit. The toggle will only be accessed by processors that did not diffract. As depicted in the figure below, diffracting trees implement this approach by adding a ``prism'' array in front of the toggle bit of every balancer. The prism is an inherently distributed data structure that allows many diffractions to occur in parallel. The tree structure guarantees correctness of the output values, and a logarithmic time termination guarantee. It is also highly fault tolerant, and the delay or failure of any subset of processors will not prevent others from successfully shepherding tokens through the tree.
One can use a pair of diffracting trees to implement a highly concurrent shared queue. An even more effective concurrent queue is created using an elimination tree, a diffracting data structure that allows pairs of enqueue and dequeue requests that collide and be ``eliminated'' on the tree's prisms, exchanging values in almost constant time.
Our empirical performance data, shows that diffracting trees and elimination pools substantially outperform all known techniques: they scale better, giving higher throughput over a large number of processors, and are more robust in terms of their ability to handle unexpected latencies and differing loads.
Through the use of combinatorial constructions, the distributed-coordinated approach offers a way to replace tight synchronization with much looser forms of coordination, distributing work loads over multiple locations, eliminating sequential bottlenecks, and lowering the levels of memory and interconnect contention. Our planned research will couple novel theoretical results together with practical considerations, in order to develop a library of concurrent data structures that (1) have detailed formal specifications, (2) have mathematically provable complexity, and resiliency properties, and (3) exhibit scalable and robust performance on actual and simulated multiprocessor machines. We plan to publish our developed data structures in a collection of research papers and provide a package of resulting implementation codes.
The distributed-coordinated approach has already yielded a variety of diffraction based data structures which experimentally outperform known solutions; we expect it will have important consequences for real-time and fault-tolerant application development and network protocol design.
 | |
|
TOC /
LCS /
MIT Last modified: Fri Nov 7 16:08:03 1997 |
Comments? |