
This work is licensed under a Creative Commons License.
Netwatcher: A Design of an Internet Filter Based on an Adaptive
Version of Naïve Bayes
Jean Almonord
Daniel Yoon
Massachusetts Institute of Technology
Fall Semester 2003
MIT 6.805/6.806/STS085: Ethics and Law on the Electronic
Frontier
Advisors
Hal Abelson
Danny Weitzner
Abstract
We design an internet content filter named netwatcher based
on an adaptive version of Naïve Bayes. Upon interviewing librarians, we found
out that overblocking was a major problem with current filters. Netwatcher is
designed to reduce overblocking, to place more control in the hands of
librarians, and to be more adaptive in terms of retraining the learning algorithm.
The filter is divided into three parts: the learning algorithm, a list of
pre-defined block sites, and an online community of clients that can update
each other.
Thesis
This paper shows that a filter design based on an adaptive
version of Naive Bayes, a learning algorithm, is an effective solution for
libraries wishing to receive E-rate and LSTA funding. The filter will serve as a text classifier
differentiating between material that is either patently offensive, harmful to
minors, or both, and material that is not.
Librarians will benefit from using this design because it reduces the
over blocking of sites that are not patently offensive, grants librarians more
control over the process of blocking sites, and takes the input of librarians
into account for improving the filter
Table of Contents
1. Introduction 4
1.1 Overview
1.2 History and
Legal Implications
1.3 Current
Solutions
2 Design Solution 8
2.1 Design Overview
2.2 Design Decisions
2.3 Simulations
3 System Evaluation 15
3.1 Law
3.2 Architecture
3.3 Market
3.4 Norms
4 Feasibility 17
4.1. Alternative Designs
4.2 Future Recommendations
5 Conclusion 17
6 References 17
7 Appendix 18
.
1.0 Introduction
1.1 Overview
With the
advent of the internet, ordinary people have gained the ability to access a
wealth of material very easily. Such a wealth of material forms the content of
the internet, and is as diverse as human thought [1]. It ranges from
educational material to purely pornographic material. Parents seeking to
protect their children from objectionable material have generally opted for
internet filters. Internet Filters uses certain algorithms to detect certain
material online and prevent computer users from accessing such material. No filter is as good as human judgment; as a
result, there is still a lot of work to be done in improving current filters.
This paper
aims at proposing the design of a viable internet filter that specifically
meets the needs of librarians seeking E-rate and LSTA funding. In designing an
effective filter tailored to the need of librarians, there are several
requirements that the filter must meet:
·
The
filter must never remove control from librarians. Instead, it must place more
control in the hands of librarians
·
The filter must reduce overblocking
·
The filter must be adaptive through the use o
fits responsiveness to librarians.
The design
seeks to meet all three criteria. The
design does not seek to create a filter that prevents access to all sorts of
user communication. It does not behave similar to a firewall; it does not seek
to filter incoming nor outgoing telnet and ftp connections.
1.2
Legal Background
In response to mounting concerns that children would be
exposed to objectionable material, Congress passed a series of legislation that
placed restrictions on internet use in order to protect minors, including the
Communication Decency Act (CDA) [2], the Child Online Protection Act
(COPA) [3], and Child Internet Protection Act (CIPA) [4]. However while relevant portions of both the
CDA and COPA were struck down by the U.S. Courts in Reno v. ACLU [5] and in ACLU v. Ashcroft [6], CIPA was upheld as constitutional by the
Supreme Court in the in United States v.
American Library Association [7]. Applying
a rational basis review, Chief Justice Rehnquist and three other justices
pointed out that the government had a legitimate interest in protecting minors
from inappropriate material, public libraries had broad discretion to decide
what material to provide to their patrons, and that patrons who are adults could
ask the librarian to unblock erroneously blocked sites or disable the filter
completely.
The provisions of CIPA state that public libraries or schools
wishing to receive federal assistance must install and use technologies for
filtering or blocking material on the Internet for all computers with Internet
access. The two types federal assistance
which are adversely affected by CIPA is the E-rate program [8], which allows libraries to buy Internet
access at a discount and Library Services and Technology Act [9] , LSTA,
which assists libraries in acquiring computer systems and
telecommunication technologies. The three types of material CIPA seeks to
protect minors from are visual depictions that are obscene, that contains child
pornography, or that are harmful to minors.
Obscenity as defined by three prong test established in
Miller v.
·
Whether
the average person, applying contemporary community standards, would find that
the material, taken as a whole, appeals to the prurient interest;
·
Whether
the work depicts or describes, in a patently offensive way, sexual conduct specifically
defined by the applicable state or federal law to be obscene; and
·
Whether
the work, taken as a whole, lacks serious literary, artistic, political, or scientific
value.
The definition of child pornography is stated in 18 U.S.C.
2256 (2003) [12] as any visual
depiction of a minor under 18 years old engaging in sexually explicit conduct,
which includes actual or simulated sexual intercourse, bestiality,
masturbation, sadistic or masochistic abuse, or "lascivious exhibition of
the genitals or pubic area. In Ashcroft
v. Free Speech Coalition [13], the U.S.
Supreme Court ruled that any activity not actually involving a minor cannot be
child pornography. The definition harmful to minors is stated in CIPA as:
·
Any picture, image, graphic image file, or other visual
depiction that taken as a whole and with respect to minors, appeals to a
prurient interest in nudity, sex, or excretion;
·
Any picture, image, graphic image file, or other visual
depiction that depicts, describes, or represents, in a patently offensive way
with respect to what is suitable for minors, an actual or simulated sexual act
or sexual contact, actual or simulated normal or perverted sexual acts, or a
lewd exhibition of the genitals; and
·
Any picture, image, graphic image file, or other visual
depiction that taken as a whole lacks serious literary, artistic, political, or
scientific value as to minors.
1.3
Current Solutions
Even though CIPA states that only material that is obscene, that
contains child pornography or that is harmful to minors should be blocked,
companies that build internet filters often block other material that does fit
into the criteria. This
"overblocking" occurs because filtering software manufacturers often
inject their subjective biases in determining which site is objectionable. Whereas a filtering software manufacturer
might not block material by the Ku Klux Klan because it sees it as primary
source material in the context of a research report about the history of the
American south, another filtering software manufacturer may see the material as
hate speech. Similarly, many currently
available filters block materials pertaining to internet chat rooms, criminal
skills, drugs, alcohol, tobacco, electronic commerce, free pages, gambling,
hacking, hate speech, violence, weapons, web-based email, and more. These
categories are not included under the legal definition of CIPA [14].
Another factor causing overblocking is that filtering
software manufacturers use simple and relatively non-effective algorithms to
determine which sites should be blocked.
Most commercially available filters ‘remember’ the web page Uniform
Resource Locators (URL) of sites deemed inappropriate, however many times they
block all the available pages of a site when those pages do not contain any
objectionable material. PICS [define the acronym], a voluntary self-rating
system of evaluating websites, has eased the job of filtering internet content,
however it still remains voluntary their use is limited to a certain number of
the websites out on the Internet.[15] . Table One contains the details of the
filtering techniques employed by eleven of the most commonly available
filters.
|
|
A+ Inernet Filtering |
Bess |
ChiBrow |
Child Safe |
Cyber Patrol |
CYBER- sitter |
ADL |
The Internet Filter |
IPrism |
Net-nanny |
Safe Access |
|
Web page URL |
Y |
N |
Y |
Y |
Y |
Y |
N |
Y |
Y |
Y |
Y |
|
List of keywords |
Y |
Y |
Y |
N |
Y |
Y |
N |
Y |
N |
Y |
N |
|
Analysis of context in which keywords appears |
N |
Y |
Y |
N |
N |
Y |
N |
Y |
N |
Y |
Y |
|
PICS rating |
N |
N |
Y |
N |
Y |
Y |
N |
N |
N |
Y |
N |
|
Human review of websites |
Y |
Y |
Y |
N |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Table 1: Current Filtering Techniques: This is table
detailing the techniques employed by eleven of the most commonly used filters
in order to determine whether should be blocked or whether a site should be
allowed. Each of these techniques has their
own strengths and weaknesses [16].
Although it is difficult to accurately discern the number of
sites that are overblocked either due to subjective decisions or technological
failures, the Electronics Frontier Foundation estimates that for every web page
blocked as advertised, filters blocks one or more web pages incorrectly [17]. In
terms of numbers, this is close to 10,000 sites minimum when the filters are placed
in the least restrictive [18]. In another
independent expert report, Ben Edelman of
More important than
the number of sites that are blocked, are the types of sites that are blocked. The
Electronics Frontier Foundation reported that N2H2’s Bess, one of the most
popular filters available, blocked a page describing community partners of the
To address the problem of overblocking, filter software
manufacturers have incorporated a variety of features. While many commercially available filters do
not allow users to review the list of URLs that are blocked, they generally
allow users to review the list of keywords or the company’s criteria for
filtering a webpage. Some also allow
users to edit the categories which are blocked, permanently edit or completely
override the filtering software’s list of material to be blocked, or create
their own block list either from scratch or by starting with the manufacturer’s
list. Table Two describes the available
customization features in commonly used filters.
|
|
A+ Inernet Filtering |
N2H2 Bess |
ChiBrow |
Child Safe |
Cyber Patrol |
CYBER- sitter |
ADL |
The Internet Filter |
IPrism |
Net-nanny |
Safe Access |
|
Filter software manufacturer alone decides what
material will be filtered |
Y |
N |
N |
N |
N |
N |
N |
Y |
N |
N |
Y |
|
Users can review the list of keywords |
Y |
N |
Y |
N |
Y |
N |
N |
Y |
N |
Y |
N |
|
Users can review the list of filtered web page
addresses |
N |
N |
Y |
N |
N |
N |
N |
Y |
N |
Y |
N |
|
Users can review the company’s criteria for
filtering a web page |
Y |
Y |
Y |
N |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
|
Users are able to chose from pre-set categories what
material they want to filter |
N |
Y |
Y |
Y |
Y |
Y |
N |
Y |
Y |
N |
Y |
|
Users are able to permanently edit the company’s
list of material to be filtered |
N |
N |
Y |
Y |
Y |
N |
N |
Y |
Y |
Y |
N |
|
Users are able to completely override the company’s
list of material to be filtered |
N |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
N |
|
Users are able to develop their own list of
information to be filtered, using the manufacturer’s list as starters |
N |
N |
Y |
Y |
N |
N |
N |
Y |
N |
Y |
N |
|
Users are able to develop their own list of
materials to be filtered, starting from scratch |
N |
N |
Y |
Y |
N |
N |
N |
Y |
Y |
Y |
N |
Table 2: Customization Tools: This is table detailing
the customization tools that are available on eleven of the most popular
filters. They allow users to
individually tailor the filter to suit their needs, however many of the features
take a considerable amount of time and are not so easy to use [22].
Instead of engaging in these relatively time-consuming and
not-so-easy customization tactics, many libraries have sought to avoid filters
completely. At Lynn Public Library, for
instance, librarians have adopted an informal tap-on-the shoulder policy
whereby if someone is looking at inappropriate material, a librarian will
usually approach that person [23]. In Nahant,
librarians are only able to conduct the search one computer that is connected to the internet and staff
patrons are not allowed to access the web [24]. Clearly however, these ‘alternative’
measures are not in compliance with CIPA, and come at the cost of losing E-rate
and LSTA funding, which many libraries could desperately use [25].
2.0 Design Solution
2.1 Design Overview
Internet content
filtering is very similar to email spam filtering in many respects. Currently,
most email spam filters are employing machine learning algorithms to learn
about the attributes of email that can be categorized as spam. After learning
about the attributes, the algorithms will classify future email as spam or not
based upon the learned attributes. Internet content filtering should be a very
similar process. In essence, internet filters should aim at being able to
classify text --- in this case content of sites – as filterable or not. Filterable in this case refers to material
that is either harmful to minors, obscene, or contains child pornography [26].
As a result, a similar exploitation of machine learning algorithms would
greatly enhance the capability of internet content filters.
Although the
law, CIPA, is mainly concerned with filtering visual depictions and images,
most pornographic sites usually contain erotic stories and certain “linguistic
description” of images [27] . In fact in the paper, Marketing Pornography on
the Information Superhighway, the classification scheme that was used to
classify images relied heavily on the verbal descriptions. The study concluded
that the verbal descriptions of sexually-explicit images are carefully worded
to entice consumers.
Netwatcher seeks to build on the concept of
utilizing machine learning algorithms. The design consists of three basic
parts: (1) a Naïve Bayes learning algorithm specifically trained to classify
text as filterable and not, (2) a list of pre-defined blocked sites that has
priority over the learning algorithm, (3) and an online community of clients
that can intercommunicate and whose actions of blocking and unblocking of sites
are recorded as data to further train the learning algorithm. The paper delves
a bit more into each part in the next three sections.
As designed, the
filter will serve as an intermediary between web browsers and the internet. It
will effectively listen for both incoming and outgoing messages. It will screen
out both the messages that originate from sites that are blocked and user
request for information that is available on the blocked sites. It will run the
algorithm on the incoming messages before forwarding them to the web browsers.
Figure One contains a diagram of where the filter is situated.
outgoing messages
![]()

Each library
will have a list of predefined blocked sites. This list is determined by each
librarian. If upon reviewing a site, a librarian has deemed the site
filterable, then the librarian can choose to add the site to the list of
blocked sites. If upon further review, the librarian felt mistaken about her
judgment, she can remove the site from the list of blocked sites. The list of
predefined blocked sites is given priority over the learning algorithms. Before
classifying a site, the filter will explicitly check to see whether or not the
site is not already in the list of predefined blocked sites. If it is, it will
be blocked. If it is not, then algorithm will classify it and filter it based
upon the classification.
The online
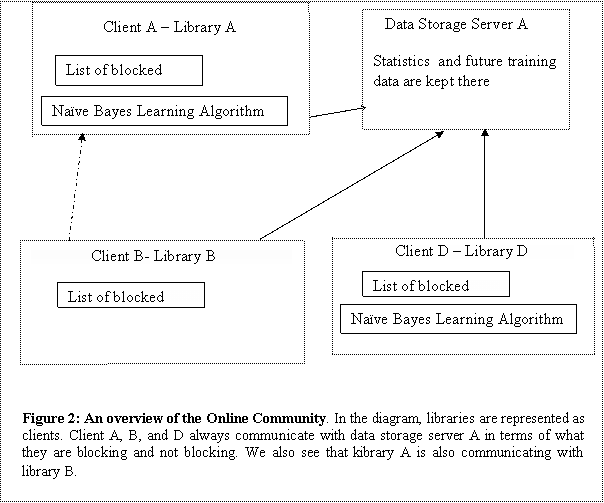
community will consist primarily of filtering clients and data storage servers.
Each individual library will represent a client. The clients will communicate
with each other. The clients may choose to be updated whenever a library has
chosen to block or unblock a site. The client may even choose to be updated
when fifty percent of all clients have chosen of block a site, or simply never
to be updated. The client must however update the servers will all of the
information that it is blocking or unblocking.
2.2 Design Descriptions
2.2.1 Naïve Bayes as the algorithm
of choice
Naïve Bayes is
the algorithm of choice because of its simplicity and efficiency in terms of
working with large amounts of data. Many email spam filter are using Naïve
Bayes and it has proven to be a successful tool in learning the attributes of
spam. As we have mentioned earlier, internet content filtering is similar to
email spam filtering. It applies even in our case, where the government is
concerned with mainly filtering out visual depictions of pornography because
most pornographic websites usually contain many written depictions along erotic
stories. In fact in the paper, Marketing Pornography on the Information
Superhighway, the classification scheme that was used to classify images relied
heavily on the verbal descriptions [27].
Naïve Bayes
works by making predictions based upon the available information. The
predictions are called inferences. The inference of a category is an inverse
transition from evidence to hypothesis. [28]. Given a set of documents, in our
case web pages, one is aiming at classifying these documents. If one has a
predefined set of documents that have been classified, one can reduce the
classification problem to simply matching the similarities in documents. The
documents contain words and these words will serve as the evidence we need in
our feature space. The hypothesis will be to determine the proper
classification of the documents. In simple terms, Bayes algorithm states that
(1) one should update the probability of a hypotheses based on evidence, and
(2) one should choose the hypothesis with the maximum probability after the
evidence has been incorporated [6.034 lecture notes].See Appendix A, for a more
thorough description of Naïve Bayes.
Using a Naïve
Bayes approach, the classified documents can be screened for all the words
contained in them and the probably that these words occur in each category of
documents. For example, if we were to classify each document with a one or zero
with one denoting good and zero denoting bad. Then each word can take the value
of one in which case a one would indicate the presence and zero would the
absence of a word in given document. Supposing that there are only three words
in all the documents, then the document in the table below can represent a
possible set of classified documents.
|
Documents |
|
Second Word |
Third Word |
Document classification |
|
First Document |
0 |
1 |
1 |
0 |
|
Second Document |
1 |
1 |
0 |
0 |
|
Third Document |
1 |
0 |
1 |
0 |
|
Fourth Document |
1 |
0 |
1 |
1 |
|
Fifth Document |
0 |
0 |
1 |
1 |
Table 3: Classification Table : This is table
containing classifications for three documents containing only a possible of
three words. The document can be
classified as a zero (bad) or a one (good). A zero for word indicates that it
is nor present in the document, whereas a one implies that it is present.
According to the
table, two documents are classified as a one and three are classified as
zeroes. Out of the documents classified as ones, the first word has a
probability of one half of being present, and one half of being absence. For
the probability of being present for the documents classified as zero, let’s
call Pji the probability that word j is present in all documents specified as
i. Similarly, if Aji is the probability of a word being absent in all documents
classified as i. Then Aji is the equivalent of 1 – Pji. In our example, P11 is
½ and A11 is also ½. P10 is 2/3 and A10 = 1/3.
Suppose one
wanted to classify a document that contained word one but not word two nor word
three from the classification table. According to Naïve Bayes, in order to
determine the likelihood of the document being classified as category I, then
one needs to multiply the probabilities Pji or Aji for each word based upon
whether or not the words are present are absent in the document. In our given
document we would multiply P11 by A21 and A31, to determine the likelihood of
document falling into category one. To determine the likelihood of it falling
into a category zero, one would multiply P10 by A20 and A30. The algorithm
would classify the document by choosing that category containing the higher
likelihood. In classifying the first document, the inference probability of the
document being a one can be obtained throught the product of A11, P21 and P31, which result in a half
multiplied by zero and by 1. The result would be zero. The inference
probability of the document being a zero would be the product of A10 , P20, and
P30, which result in The result would be four thirds.
On a different
note, in order for Naïve Bayes to work properly we need to implement a
simplified version of a page rank algorithm. [explain what you mean by a page
rank algorithm, and how it solves the problem of multiple pages on the site]
One can not simply tell whether or not a website is harmful to minors based
upon the content of only the first page of the website. As a result, we have chosen
to also classify the links to other pages on the webpage to a depth of two. The
obvious scenario is the scenario in which there is an entrance page to a
pornographic site. The entrance page will not be the sole indicator in
determining whether or not the site should be filterable.
2.2.2 Applying Naïve Bayes
As explained
above, we implemented the algorithm in a similar fashion.
The goal was to
classify websites as either filterable or not filterable, where the category of
filterable meets the criteria of being obscene, harmful to minors,
pornographic, or all three. Websites
that should be filtered were classified as ones and websites that should not be
filtered were classified as zeroes. The words contained in the websites were
used as the evidence.
In determining
the set of words that should be included in the word space, all two-letter
words were eliminated. Most two-letter words do not add much meaning to the
written descriptions and erotic stories posted by pornographic websites. As a
result the words on the feature space do not correspond to a one to one mapping
of words that are available in ordinary dictionary. Furthermore, many
pornographic websites contain words that do not form part of ordinary usage.
These words include “jizz”, “skank”, and “smut.”
Given the fact
that many inappropriate websites contain entry pages that require users to
click on enter before proceeding to the site, it was decided that one page of a
website can not properly classify the website itself. As a result, the classification
of a page entailed also classifying its links to degree of two for the training
set. However, for reasons of efficiency, we restricted the classification of
documents to also classifying their links to a degree of one.
The version of
Naïve Bayes used was also an improved version. It implements the
2.2.3 Implementing Naïve Bayes
In order to
fully implement Naïve Bayes, one needed an exhaustive set of training data. To
obtain the training data, the members of we crawled through over a thousand
websites. These websites were ranked as filterable and not filterable. In
ranking the websites, we sought to explore as many links as possible in order
to not solely rank a page of the website. After ranking the websites, we
compiled a list of URLs followed by their ranking of a zero or a one.
In order to
develop the feature space, we compiled a list of words that was used in the
training set along with their frequency of usage in the two different
categories of websites. The feature set excluded two-letter word. Note that
there does not need to exist a one to one mapping between the features in the
feature space and the words in a normal English dictionary. Whereas a normal
English dictionary’s word space will contain words such as ‘to’, ‘be’, and
‘as’, these words will be inconsequential to our design. Popular research has
indicated that most two-letter words are inconsequential in conveying the
meaning of text. Furthermore our feature
space will contain possible combination of letters such as ‘skank’, ‘jizz’, and
‘smut’ because they commonly appear in sites that harmful to minors .[29].
2.3 The Predefined Block List
Every filter
comes with an empty predefined block list. The list should contain a listing of
sites that a librarian has deemed filterable. Librarians can remove or add
sites to the list. The algorithm works by checking to see if any users are
requesting to view a site in the blocked list. This is done by listening to the
outgoing requests that going through port 80. If a user is attempting to view a
site on the blocked list, then the filter will respond with a message stating
that the site has been blocked.
2.4 The Online Community
2.4.1 The Clients
The online
community consists of filtering clients and data storage servers. The libraries the clients and they can
communicate with each other. The data storage servers will be pre-established
center for data collection. All clients must update a number of the servers
when they have chosen to block or unblock a site. Clients can do any of the
following:
(1) choose to be updated or not about other
clients’ actions.
(2) choose to be updated whenever a library
has chosen to block or unblock a site.
(3) choose to be updated when a certain
percentage of clients have blocked a site.
2.4.2 The Data Storage Servers
The data storage
servers serves as training data
aggregation centers. They compile statistics on each client’s behavior. They
systematically present each client with more data to train and improve the
algorithm. They also systematically update the clients with a list of addresses
of all the servers. The storage servers
continually listen for incoming requests from clients, or check to see
if a certain condition has been met to warrant updating a client.
In order to
achieve reliability the data storage servers will replicate the data on the
client’s blocking and unblocking actions among themselves. At midnight, every
day, the servers will update other servers with certain data taken from a
certain interval of time from a certain set of clients. The other servers will
check to see if they already contain such data.
If they do, they will not copy it. If they don’t, they will copy the
data.
2.4.3 Client-Server Interaction
Clients interact
with servers in two ways: (1) by making a request to the servers to be updated
or (2) by receiving update messages from the servers. Request messages are of
the type “please notify me when 50% of libraries have blocked a site.” Update
message will be of the types “Here is the latest training data, train the
algorithm,” or “here is list of addresses of all the servers.
The client to
server ratio will remain at 150 clients per server and each client will be
assigned three servers that it can make requests to. In the event that one of
the servers is down, the client will be able to make a request to another
server. In order to achieve reliability, each server will periodically update
the clients with a complete list of addresses of all the servers. In the event
that all three of a client’s assigned servers are down, the client will be able
to contact another server.
2.5 Simulations
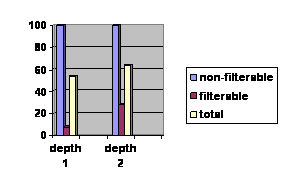
Figure 3: Chart
displaying percentage of correctness.
The chart
indicates the percentage of each category
that was
properly classified.
We classified 50 websites after the first
round of training the algorithm for a depth two and depth one analysis. Half of
those websites should have been filtered and half should not have been
filtered. Figure Three contains the
actual percentages of sites that were properly classified. For the most part
the filter never overblocked sites, but it did underblock a number of sites. After
the algorithm was retrained with added data, fifty more websites, it did not
improve significantly. The only key difference to note was that the algorithm
performed better with a depth of teo analysis. We can attribute such
underblocking to the cleverness of most pornographic sites webmasters. Most of
the pornographic sites that we analyzed contained very little text.
Furthermore, the ones that
Contained text embedded the text in images.
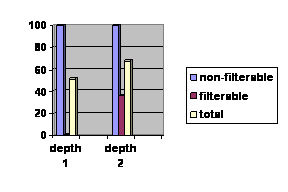
Figure 4: Chart
displaying percentage of correctness.
The chart
indicates the percentage of each category
that was
properly classified after the training data was
modified with
extra data.
3. Feasibility
In designing netwatcher, there were many design
tradeoffs that were made. These tradeoffs range from depth of the websites that
we chose to analyze to what type of blocked list mechanism would be in line
with a liberal filtering policy. This section will elaborate on some of those
tradeoffs.
A primary goal of netwatcher was that it would
improperly classify sites. We wanted it
to reduce the problem of overblocking, but however not overly increase the
problem of underblocking. As a result, out first aim was to fully classify each
website well by analyzing it to a depth of two, meaning that we also classified
the outgoing links of the website and those outgoing links’ respective outgoing
links also. However, we found that this method was rather inefficient and slow;
it did not add much more information from a depth one analysis. As a result, we
decided to go with the depth two analysis.
In training the algorithm, the original goal was to
use as much data as possible; we settled for compiling 2,000 sites along with
human ratings of those sites. This goal was not feasible given the time length
of this project and the fact that analyzing 2,000 sites to a depth two would
have required a considerable amount of human time. Furthermore, this number had to be reduced
due to computer memory limitations and the number of hours it took for a depth
of two analysis. A depth one analysis took quite some time as well, because
most pornographic sites contain a great deal of links. The number of sites was
reduced to a 1,000 with roughly forty percent consisting of material that
should be filtered.
In blocking a
site, it is not as simple as simply blocking the entire URL nor as simple as
simply blocking an entire domain. For example, in blocking the URL “http://web.mit.edu/www/jean/stuff/morestuff/page.html,”
the aim would not be to block simply page.html because that will lead to gross
underblocking. If update.html is in the directory ‘morestuff’, then it will not
be blocked and most likely the content of it will form part of the website
containing page.html. However, blocking the domain web.mit.edu will lead to
gross overblocking. As a result, the compromise that was reached was to block
the entire directory ‘morestuff’. The reasoning is that even though the blocked
list in the control of users, the algorithm implements a liberal filtering policy.
It aims to sacrifice to always sacrifice not overblocking at the risk of
underblocking. In the example, the parent directory might also be a part of the
web site, however it would wrong to block if it is not a part of the website.
4. System Evaluation
This section
analyzes whether a filter based on Naïve Bayes is viable and will be widely
adopted. In particular, this section
will examine the four major forces that have influence behavior in today’s
world: law, architecture, market, and norms.[1]
4.1 Law
In order to be
in compliance with CIPA, a library must install any technology protection
measures that protect against access to material that is obscene, child
pornography, or harmful to minors, and also must enforce the operation of such
technology measures. By its broadest
definition, a filter based on Naïve Bayes achieves these goals: only material
that was patently offensive, child pornography, and harmful to minors was
blocked, and libraries had the ability to update the information on the filter.
If Congress is
able to successfully reenact the CDA, COPA, or any other legislative measure
that places restrictions on what can be published, any filtering technology
obviously becomes obsolete. However,
given Supreme Court has held that filtering is a less restrictive alternative
in both Reno v. ACLU and ACLU v. Ashcroft, and given that we have
shown that filter based on Naïve Bayes can be an extremely effective
alternative, barring any major developments, the burden of protecting children
will continue to be placed on the receiving end rather than the sending
end.
4.2 Architecture
Because it is
designed to automatically block objectionable material, a filter based on Naïve
Bayes has significant advantages over self rating schemes. For instance, self-rating schemes often cause
controversial sites to be censored because if the operators of these sites
choose rate these sites, they will be lumped with ‘pornography’ and therefore
blocked, however if the operators of these sites choose not to rate these
sites, they will be considered ‘unrated’ and also blocked. In contrast, the only sites that a filter
based on Naïve Bayes blocks are those that are obscene, child pornography, and
harmful to minors. In addition,
self-rating schemes also have possibly adverse effect on the democratic nature
of the internet, since commercial speakers will be able to better deal with the
burdens associated with self-rating systems in comparison to non-commercial and
individual speakers. Comparatively, our
filter seeks to preserve the structure of the internet.
Because current
filters are relatively ineffective, self-rating schemes have still enjoyed
immense popularity despite these problems.
By showing that a filter based on Naïve Bayes, the hope is that people will
be inclined to adopt the solution that provides protection to children, but
also does not place an undue burden on publishers.
4.3 Market
As mentioned in
the introduction, CIPA merely provides federal assistance to libraries that
employ filters or other technology protection measures that protect against
access to material that is obscene, child pornography, or harmful to
minors. If libraries choose to implement
filters, they will receive these federal funds.
If they choose not to, their only punishment is that they do not receive
these funds.
Despite the
financial difficulties facing libraries, many libraries have still continued to
resist the use of filters because filters block Constitutionally-protected
speech and because libraries do not have control over the sites that filters
block. By addressing these concerns
through the creation of a filter based on Naïve Bayes, many libraries in dire
need of funding may reconsider the use of filters.
4.4 Norms
Even though it
is designed to automatically only blocks material that is patently offensive
child pornography, and harmful to minors, the filter implemented in this paper
also takes into consideration community standards through the predefined block
list which is shared with other libraries.
For one thing, certain libraries might believe that hate speech should
be censored. Not only does our
particular filter allow hate speech to be censored, it also allows all libraries
who are against hate speech to assist each other in blocking sites with hate
speech. At the same time, when a library
blocks a sites that many others would not believe should be blocked, other
libraries will become aware that a site that probably should not be blocked is
being blocked.
Obviously, the
filter implemented in this paper is not perfect in the sense that a library in
an isolated community could theoretically block a site that nobody else would
block. However, the ability for
libraries to individually tailor their block list in a relatively efficient
manner is still compelling reason for libraries to implement our particular
filter.
5.Conclusion and Future
Recommendations
Netwatcher has
established its goal of reducing overblocking, however on the other hand
underblocking is also drastically increased. Part of the reason for this is the
fact that most pornographic sites contain very little text and that the ones
that contain text embeds it in the images. We should also say that a little
refining of our feature space would have probably helped also. Nonetheless,
netwatcher contains its strengths and weaknesses. It is only through the improvement of the
weaknesses that the overall filter will improve.
Netwatcher’s
weaknesses include its inability of being able to automatically block mirrors
of websites that are on its predefined list of blocked sites. It is
particularly hard to determine whether or not a site is a mirror of another
site. One possible way might be with the introduction of a threshold percentage
of similarity. One could say that website A abd website B are if mirrors if and
only if their contents match up 85% correctly. Content matching would entail
similarity of directory structures and file to file content matching and dates
of modifications. However, this solution exacerbates the lag that users will
experience in retrieving information from the world wide web.
Netwatcher can
also be improved through the use of image classification instead of text
classification. Webmasters of pornographic sites can easily update their site
to include text only images, which would defeat the entire purpose of
netwatcher as a text classifier. In the future, it might be good to implement
the filter a a complete image classification tool given CIPA’s constraints.
6.References
1.
2. Communications Decency Act (47 U.S.C. 231 (2000))
3. Child Online Privacy Act (47
U.S.C. 231 (2000))
4. Children Internet Protection
Act (20 U.S.C. 9134(f) (2000))
5.
6. ACLU v. Ashcroft (322 F. 3d 24 (2003))
7.
8. E-rate funding is adversely affected. (47 U.S.C.
254(h) (2003))
9. LSTA funding is also inversely
affected. (20 U.S.C. 9101 (2003))
10. Miller v.
11. 18. U.S.C. 1460 (2003)
12. 18 U.S.C. 2256 (2003)
13. Ashcroft v. Free Speech
Coalition, 122 S.Ct. 1389 (2002),
14. The Electronic Frontier Foundation,
2003. “Internet Blocking in Public
Schools” [online].
15 Beeson, Ann and Hansen, Chris,
2003. “ACLU White Paper: Fahrenheit
451.2: Is Cyberspace Burning?” [online].
Available from World Wide Web: (http://archive.aclu.org/issues/cyber/burning.html).
16 Internet-filters.net, 2002. “Internet Filter Feature Guide”
[online]. Internet-filters.net [updated
2002, cited
17 The Electronic Frontier Foundation, 2003. “Internet Blocking in Public Schools”.
18 Ibid.
19 Edelman, Ben, 2001. “Sites Blocked ” [online].
20 The Electronic Frontier Foundation,
2003. “Internet Blocking in Public
Schools”.
21 Knox, Robert, 2003. Libraries Seek
Balance on Computer Filters [online].
22 Internet-filters.net, 2002. “Internet Filter Feature Guide”.
23 Buote, Brenda, 2003. “Many
Library Shun Funds Say they Won’t Filter Internet” [online].
24 Ibid.
25 Ibid.
26 United States v.
American Library Association, 123
27 [Marketing
Pornography On the Information Superhighway]
http://www-swiss.ai.mit.edu/6805/articles/pornscare/rimm-study/mrtext.html
28 Text Classification
using a Naïve Bayes Approach]. Jyotishman Pathak. www.cs.iastate.edu/~jpathak/courses/finalreport.pdf
29.
see 27
7.0 Appendix
Appendix A:
Description of Naïve Bayes
Excerpt taken
from 6.034 (Introduction to Artificial Intelligence) lecture note.






Appendix B: List of Sites Used for
Training Data
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|