| Fig. 1. A schematic for the overall system |
 |
| This section is part of Patil, Ramesh S. Causal Representation of Patient Illness for Electrolyte and Acid-Base Diagnosis. MIT Lab for Comp. Sci. TR-267 (1981). |
In a 1970 article reviewing the role of emerging computer technology in medicine, Dr. William B. Schwartz notes
“If conventional remedies will not meet the demands imposed by society's broad commitment to extensions of health care, it is clear that new, even heretical, strategies must be devised. One such strategy will almost certainly involve exploitation of the computer as an “intellectual,” “deductive” instrument—a consultant that is built into the very structure of the medical-care system and that augments or replaces many traditional activities of the physician. Already, several interesting steps have been taken in an attempt to extend the computer's role into this realm. ... Indeed, it seems probable that in the not too distant future the physician and the computer will engage in frequent dialogue, the computer continuously taking note of history, physical findings, laboratory data, and the like, alerting the physician to the most probable diagnoses and suggesting the appropriate, safest course of action. One may hope that the computer, well equipped to store large volumes of information and ingeniously programmed to assist in decision making, will help free the physician to concentrate on the tasks that are uniquely human such as the application of bedside skills, the management of the emotional aspects of diseases, and the exercise of good judgment in the non quantifiable areas of clinical care.”
—Medicine and the Computer [Schwartz70, page 3]
The decade following these predictions saw a rapid growth in the field of Artificial Intelligence in Medicine (AIM) culminating in many promising programs, among which are Internist-I [Pople77], the Present Illness Program (PIP) [Pauker76], CASNET/Glaucoma [Weiss74], MYCIN [Shortliffe76] and Digitalis Therapy Advisor [Pauker76]. These programs represent the first efforts in the use of Al techniques in medical decision making, and can be characterized as the “first generation AIM programs”. They have clearly demonstrated the feasibility and usefulness of Al techniques. Most of these programs have, in some trial, been judged to match expert physicians in their competence—this is indeed an outstanding achievement.
It is natural to question then: “What are the limits of their expertise? Why aren't we implementing these programs in many more areas of medicine and distributing them for clinical use?” To answer these questions we must take a deeper look at the programs and their performance. For example, although they are (on average) outstanding on their core set of anticipated applications, their performance can also be non-uniform; it tends to degrade rather ungracefully just outside their domain of expertise. Furthermore, these programs may be misled on difficult cases involving complex interactions or multiple disorders, even if these cases fall well within their domain of expertise. This leads to the inevitable conclusion that although the models of representation and deduction used in these programs are capable of providing moderate coverage over the area of application, they are nonetheless inadequate.
These observations have led to a re-evaluation of the techniques used in the first generation of AIM programs. The following insights have been gained by this evaluation. Firstly, the notion of causality is inadequately exploited in the first generation AIM programs [Smith79, Patil79, Pople81]. They do not utilize the structure provided by causal relations to organize the patient facts and disease hypotheses. They fail to capture the human notion that explanation should rest on a chain of cause-effect deduction. Secondly, they cannot deal with the effects of more than one disease present in a patient simultaneously, especially when one of the diseases alters the presentation of the others. Thirdly, they do not deal with the knowledge of a disease phenomenon at different levels of detail that a physician clearly has. Finally, the numeric belief measures as used by the first generation AIM programs do not provide adequate criteria for diagnostic reasoning. They are unable to capture notions such as adequacy and parsimony of a diagnostic possibility.
Much of the medical knowledge contained in the first generation AIM programs can be characterized as being phenomenological; that is, it describes the associations among phenomena without the mechanisms underlying the observed associations. Such phenomenological descriptions provide a good first approximation to the way physicians reason, but they fail to capture the physicians' reasoning in recognizing and dealing with the inherent discrepancies in their knowledge and with deduction based on deeper understanding of the phenomena. Contrasting the behavior of the first generation AIM programs and human experts, Szolovits notes:
“Consider what happens when two “rules of thumb” (as we may identify a bit of phenomenological knowledge in medicine) conflict. Every AIM program written so far evaluates that conflict by reducing it to a numerical judgment of likelihood (or certainty, belief, etc.) in the hypotheses it holds: Mycin computes a revised certainty factor, CASNET computes new weights, Internist computes new scores, and the digitalis program often computes a weighted sum of its observations to evaluate their joint effect. Thus, conflict, just as agreement, is reduced to a manipulation of strength of belief. Yet, by contrast, we believe that human experts make a much more powerful use of occasions where they detect conflict. They are not satisfied by a simple revision of their degree of belief in the hypotheses which they have previously held; they seek a deeper, more detailed understanding of the causes of the conflict they have detected. For it is just at such times of conflicting information that interesting new facets of the problem are visible.
Conflicts provide the occasion for contemplating a needed re-interpretation of previously-accepted data, the addition of possible new disorders to the set of hypotheses under consideration, and the reformulation of hypotheses thus far loosely held into a more satisfying, cohesive whole. Much of human experts' ability to do these things depends on their knowledge of the domain in greater depth than what is typically needed to interpret simple cases not involving conflict.”
—Artificial Intelligence and Medicine [Szolovits81a, pages 16-17]
To move beyond the sometimes fragile nature of today's programs, we believe that future AIM programs must contain medical knowledge similar in depth of detail to that used by expert physicians. They must have anatomical, physiological and pathophysiological knowledge sufficiently inclusive in both breadth and detail to allow the expression of any knowledge or hypothesis that usefully arises in medical reasoning.
One of the important areas of medical diagnosis not adequately addressed by the first generation of AIM programs is the evaluation of the effect of more than one disease present in the patient simultaneously, especially when one of the diseases alters the presentation of the others. For example, let us consider a patient with diarrhea and vomiting leading to severe hypokalemia. Let us also suppose that we know about the diarrhea, but we are not aware of the vomiting. The observed hypokalemia is too severe to be properly accounted for by the diarrhea alone and therefore diarrhea cannot be considered as complete explanation for the observed hypokalemia. Given this fact, the diarrhea is either not responsible for hypokalemia or is only partly responsible. If the diarrhea is not responsible, then further reasoning is relatively easy: the problem simplifies to finding the actual cause. However, if diarrhea is partly responsible, a correct partitioning of the total observed hypokalemia between its two suspected causes is required, with a judgment of how well the two separate causes combined in the estimated proportions account for the patient's condition.1 Notice how inadequate the simple assignment of a probability linking diarrhea and hypokalemia (as is commonly done in existing programs) is to capture the problem being described here.
The complexity and depth of medical knowledge is well recognized [Szolovits78]. Our understanding of medical expert reasoning suggests that an expert physician may have an understanding of a difficult case in terms of several levels of detail. At the shallowest level that understanding may be in terms of commonly occurring associations of syndromes and diseases, whereas at the deepest it may include a biochemical and pathophysiological interaction of abnormal findings. While it may be easier for a program to reason succinctly with medical knowledge artificially represented at a uniform level of detail,2 a range of representations are needed to reason at a sophisticated level of competence [Patil8l]. Unfortunately, very little attention has been paid to developing methods for coping with it. We take this as the central issue of this thesis.
Finally, we believe that the numerical (probabilistic or pseudo-probabilistic) belief measures as used by the first generation AIM programs for confirming diagnoses and guiding the diagnostic search do not provide adequate criteria for diagnostic reasoning. We believe that the evaluation methods for confirming a disease hypothesis should be different from the methods used for choosing the most promising disease hypothesis for diagnostic pursuit. A single criterion is almost certain to be inadequate for both these tasks. Furthermore, we believe that the probabilistic model by itself is inherently inadequate. For example, it fails to take into account the causal nature of the disease mechanisms, it fails to capture the notions of parsimony, coherence and adequacy of diagnostic explanation. In a study of problem solving activity of clinicians, Kassirer and Gorry note that
“In parallel with the processes by which the physicians built a case toward a final diagnosis, they assessed each diagnosis for coherence and adequacy. ... (A diagnosis was considered coherent if all the symptoms and diseases contained in it were causally related to each other. A diagnosis was considered adequate when it accounted for all known facts.) ... The physicians strove to attain parsimonious explanations for the findings and to accept a single explanation rather than make two or more diagnoses unless they were forced to do so.”
— Clinical Problem Solving [Kassirer78, pages 249-250]
It is one of the central themes of this thesis that these problems cannot be avoided by relying solely on the numerical scoring mechanism; the programs must be provided with structural criteria to evaluate the disease hypotheses.
It is our belief that modeling the program's understanding of the patient's illness is crucial to capturing the expertise of clinicians. In this thesis, we will explore some of the issues involved in representing diagnosis. We will develop techniques for reconciling physiological reasoning with phenomenological reasoning and explore issues of aggregating all the available knowledge into concise summaries of the patient's illness. We will discuss structural criteria for evaluating parsimony, coherence and adequacy of diagnostic explanations. We will also explore some of the issues involved in information gathering and propose expectation-driven diagnostic planning as a means of improving it. Finally, we will discuss the issues relating to explanation and justification of the program's understanding.
To study these issues, we have chosen the task of providing expert consultation in cases of electrolyte and acid-base disturbances. The research presented in this thesis, the development of a program called ABEL (Acid-Base and Electrolyte program), is a part of this overall effort. We describe a novel mechanism for representing ABEL's understanding of a patient's illness. This understanding is represented using a collection of data-structures called the patient-specific models (PSMs). Each PSM contains a hypothesis ‘structure containing all known data about the patient, all currently held possible interpretations of these data, the causal interconnections among the known data and tenable hypotheses, and some indication of alternative interpretations and their relevant evaluations. We describe the representation of medical knowledge and the processing strategies needed to enable ABEL to construct a PSM from the initial data presented to the program. The same representations and procedures are also used in revising the PSM during the process of diagnosis. Each PSM can be viewed as a partial explanation of the patient's illness.
Diagnostic problems are formulated by identifying the weaknesses and conflicts in the PSMs and by computing a diagnostic closure (DC) for each PSM. A DC associated with a PSM represents a collection of alternative completions of the partial explanation provided by the PSM. It brings together all the dependencies and expectations necessary for diagnostic inquiry, for evaluating real and apparent discrepancies in the incoming information, and for explaining the diagnostic alternatives under consideration. A plan for diagnostic inquiry is generated by decomposing a top level diagnostic problem into simple problems which can be directly solved by a question to the user. Finally, when an inquiry is completed, the new information gathered is assimilated into the PSMs and the diagnostic process is repeated.
This thesis has three main objectives. The first is to develop a representation of causal medical knowledge. The second is to develop a case-specific “understanding” of illness. This understanding should be capable of describing subtle interactions between diseased and normal physiological mechanisms, and therapeutic interventions. The third is to develop a set of reasoning procedures to combine the aggregate phenomenological knowledge of disease associations with the detailed pathophysiological knowledge of disease processes. The first of these, the phenomenological knowledge, is necessary for efficient diagnostic exploration; the second, the pathophysiological knowledge, is necessary for proper understanding of a difficult case. The research reported in this thesis is conducted in the larger context of an Expert Consultant for Electrolyte and Acid-Base Disturbances [Patil79]. This section briefly reviews the organization of the overall system.
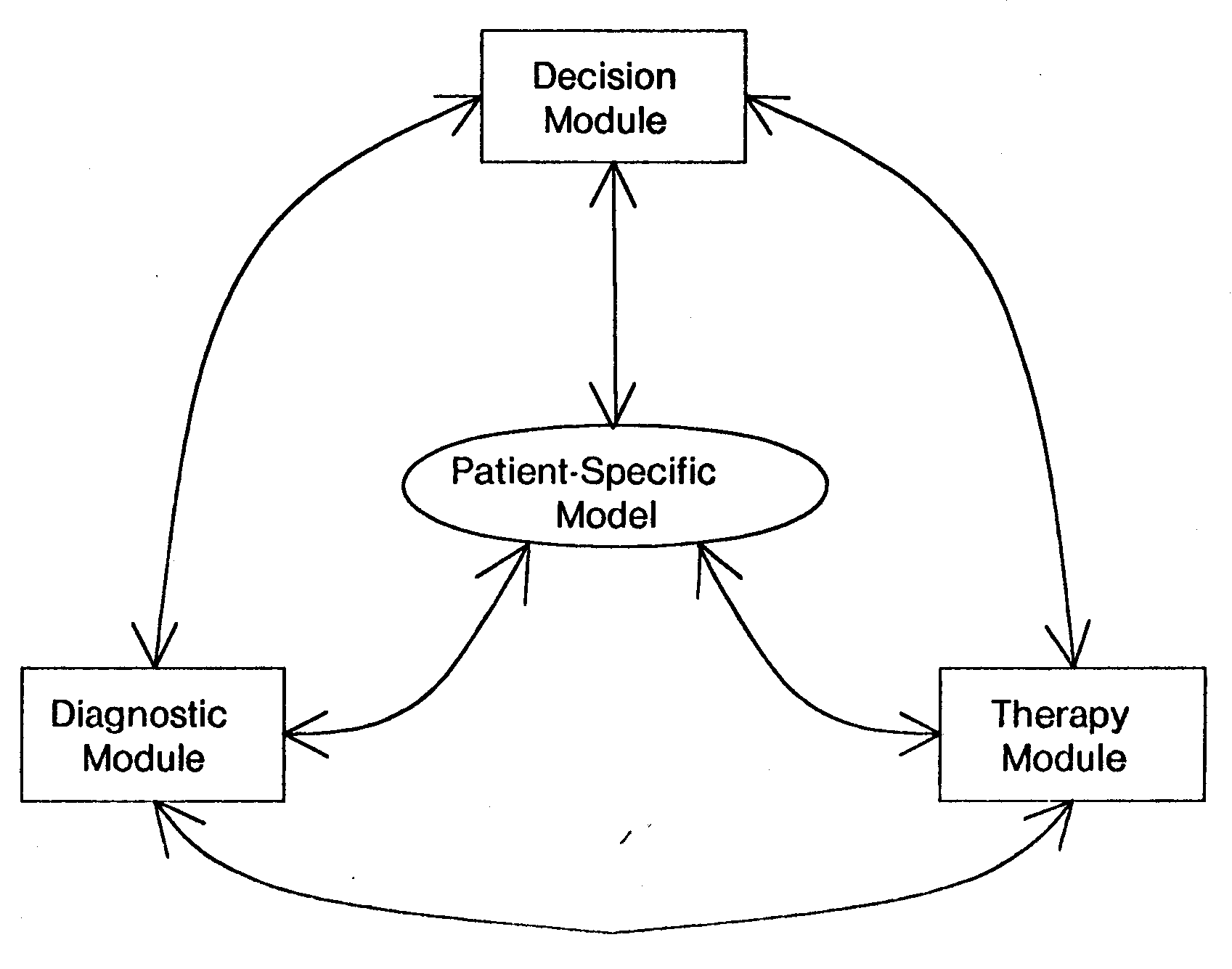
The objective of an expert medical consultant is to advise in the proper management of a patient. Proper management consists of collecting the relevant information about the patient, identifying the disease process(es) responsible for the patient's illness, and prescribing a proper course of action to correct the patient's condition. One of the complexities of this task is due to the fact that these subtasks do not have well defined boundaries. The patient may be presented to a clinician at different stages of a disease's evolution and treatment. During the course of management new information about the past history may become necessary as the diagnostic hypotheses evolve. The current diagnosis may depend on information that is presently unavailable. The disease itself may evolve through time, providing additional clues to its identity, or the response to certain therapeutic interventions may provide valuable diagnostic information. Finally, the patient's condition may require therapeutic intervention even before the diagnostic issues can be reasonably resolved. Therefore, the next course of action must be chosen from a large range of alternatives. These alternatives may be broadly classified as gathering information (much of which may turn out to be irrelevant in the evolving clinical context), ordering tests (possibly involving expensive time delays and/or clinical costs), waiting for further development, prescribing therapy or some combination of the above. At every stage of consultation, the program must be able to choose between the alternative sets of actions with the patient's best interest in view. This can be achieved only by developing a program capable of forming a diagnosis, suggesting a therapy and making decisions. With this perspective we have embarked on the design of the Electrolyte and Acid-Base Consultant system. We have tried to separate and modularize different components of a physician's knowledge and expertise so as to be able to evaluate our understanding about each component and their interactions. This modularization should also allow us to further experiment with any component of the system without having to reimplement the entire program. A top level schematic for the overall system is shown in figure 1.
| Fig. 1. A schematic for the overall system |
|
|
The Electrolyte and Acid-Base Consultant system consists of four major components: (1) the Global Decision Making component, (2) the Diagnosis component, (3) the Therapy component and (4) the Patient Specific Model. The patient specific model describes the physician's understanding of the state of the patient at any point during diagnosis and management; it is intended to be the central data structure which other components of the system may reason with. The global decision making component is the top level program which has the responsibility of calling the other programs with specific tasks. In general, the global decision program will call the diagnostic program with a task such as taking the initial history and elaborating some specific diagnosis. The diagnostic component then performs the specified task and reports the results to the main program. It also modifies the patient specific model to reflect the revised state of the patient. Similarly, if the global decision making program calls the therapy selection program, it attempts to formulate a set of alternate therapies for the patient along with a check list of items that must be tested before any specific therapy can be recommended. It also identifies information that will help discriminate between alternate therapy recommendations. Note that at every step the global decision maker can evaluate each of the possible sets of actions and choose the most desirable one. The decision making component will allow the program to make explicit the decision making that goes on in a physicians reasoning: is further diagnosis necessary, what treatment should be selected, should he wait before prescribing further treatment, can he choose some therapeutic action that would also provide diagnostic information making further diagnosis at this point unnecessary?
This thesis deals primarily with the development of the patient specific model which describes the program's understanding about the patient's illness. We have focused here because we believe that the level of expertise achievable by the program is inherently dependent upon the expressive capabilities of the patient specific model. The program can reason about subtle interactions between diseases in a given patient only if it can describe these interactions in the context of the patient. In addition a preliminary implementation of the diagnostic component to demonstrate the use of this patient-specific model is also discussed.
Careful selection of a domain is crucial for developing an application program: The domain chosen must be small enough to allow one to build a knowledge-base in a reasonable amount of time, and yet large enough to allow for realistic testing of the new ideas being implemented. Furthermore, the domain should be well defined and should lead to useful application, so that the program can be field-tested under realistic conditions. We have chosen the domain of electrolyte and acid-base disturbances as the test-bed for our theories of medical diagnosis.
The domain of electrolyte and acid-base disturbances is a well defined and relatively narrow area of medicine. It is an ideal domain for testing our theories about interactions between causal (physiological) reasoning and phenomenological (syndromic) reasoning, as on one hand the / basic pathophysiology of the acid-base disturbances is well developed, and on the other, the pathophysiology of the diseases leading to these disturbances is relatively poorly understood. Thus constantly forcing us to develop reasoning mechanisms that can deal simultaneously with well understood causal knowledge and poorly understood phenomenological knowledge. In addition, the feed-back nature of the electrolyte and acid-base homeostatic mechanism provides us, in a microcosm, with a variety of issues relating to “dynamic” systems that must be addressed in the management of a patient's illness.
Electrolyte and acid-base disturbances are a common complication of a large number of serious illnesses and medical interventions. In spite of their prevalence, this remains an area that most practicing physicians find somewhat difficult to deal with. This makes the field of acid-base disturbances an attractive domain for introducing expert computer consultant programs. One of the earliest programs for medical consultation [Bleich72] was in fact introduced in this very area.
Our primary concern, however is not with electrolyte and acid-base disturbances per Se. Our basic purpose is to use this domain as a vehicle for evaluation of the existing techniques and development of new techniques for diagnosis and management of a patient's illness. In particular, in this thesis we will develop techniques for providing a coherent account of a patient's illness which incorporates the pathophysiological understanding of acid-base disturbances with the aggregate phenomenological understanding of the diseases causing these disturbances.
In this section we briefly describe the electrolyte and acid-base disturbances. This section is not intended as a full review of the subject matter, but is presented here to provide the readers with a framework for understanding the medical examples used in this document. Each example used in the document is accompanied by an explanation of the relevant medical knowledge.
Fluid and electrolyte disturbances usually occur as complications of an underlying illness, therefore these disorders must be viewed not as isolated entities but in the context of the specific clinical settings in which they appear. As general background to the following discussion, it should be remembered that approximately 50 to 60 per cent of the body (by weight) consists of water distributed between the intracellular (within cells) and extracellular (outside cells) compartments. Water moves freely across cell boundaries, maintaining osmotic equilibrium between the different comp8rtments. By contrast, owing to differences in their permeability and active ionic pumps, the electrolytes are distributed in an asymmetric pattern, most of the ions in extracellular fluid consisting of sodium, chloride and bicarbonate and those in intracellular fluid of potassium and organic anions. Regulation of the external environment of cells, that is, the electrolyte concentration and acidity (pH) of the body fluids, is of primary importance. Perturbations in the regulation of this environment is the subject of electrolyte and acid-base disturbances.
The pH of the body fluids is regulated by three mechanisms: (1) the body buffers, (2) pulmonary regulation of the concentration of CO2 in the body, and (3) renal excretion of acids and alkali. They act in a complementary fashion, first to minimize transient changes and then to correct any disturbances in acid-base balance by appropriate retention or excretion of hydrogen ions. To understand the mechanism of acid-base disturbances, it is instructive to consider the way in which the body deals with the normal daily acid load in maintaining a steady-state of acid-base equilibrium.
As food is oxidized to provide metabolic energy, both carbon dioxide (carbonic acid) and acids such as sulfuric and phosphoric acids are added to the extracellular fluid. They are immediately buffered to minimize the change in pH and transferred to the lungs and kidneys for excretion. Carbon dioxide is excreted almost entirely by the lungs while the other acids are excreted solely by the kidney. Bicarbonate is regenerated by the kidney as it excretes the excess acid, replenishing the bicarbonate stores that previously were depleted by the buffering of the dietary acid. From all these considerations it is evident that derangements in either the pulmonary or renal function, or the imposition of stresses that overwhelm normal regulatory mechanisms (such as vomiting, diarrhea, burns, etc.) can be expected to produce disturbances of acid-base equilibrium.
| Fig. 2. Carbonic acid-bicarbonate buffer equation |
|
Acid Base Regulation |
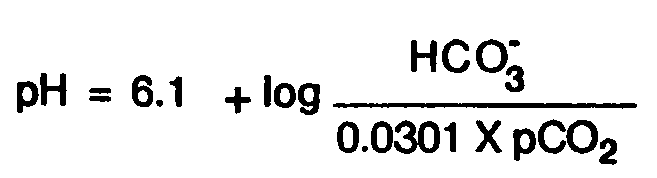 |
|
Henderson-Hasselbalch Equation |
 |
|
Regulation of Carbonic Acid/Bicarbonate buffer pair |
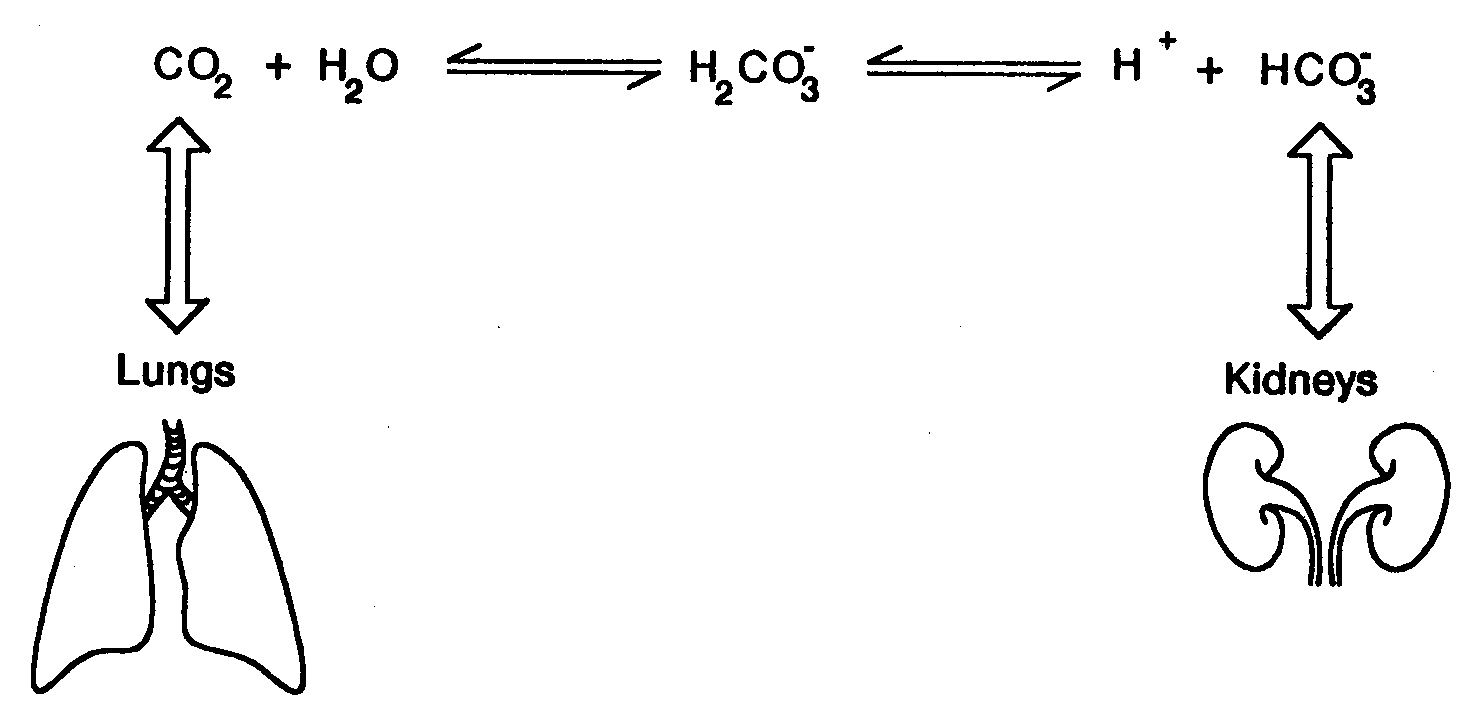
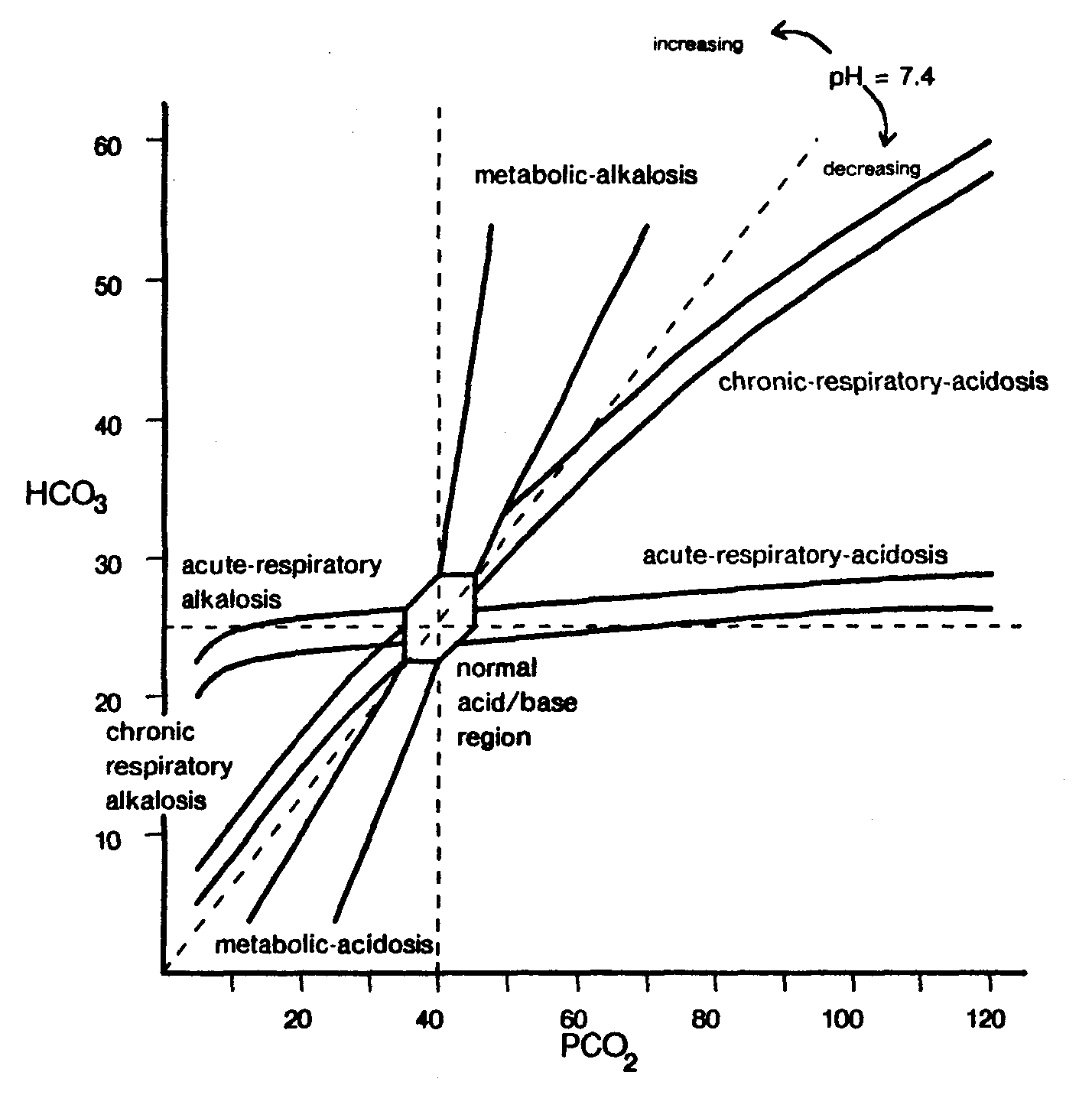
The equilibrium equation of the major buffer system in the extracellular fluid, the carbonic acid–bicarbonate buffer system, is shown in figure 2. This equation allows ready visualization of the directional changes that can be anticipated in both metabolic and respiratory disturbances of the acid-base equilibrium. For example, a primary reduction in bicarbonate concentration (metabolic acidosis) will cause the reaction to shift to the right, thus increasing hydrogen ion concentration, whereas a primary elevation in bicarbonate concentration (metabolic alkalosis) will cause the reaction to shift to the left, thus decreasing hydrogen ion concentration. Similarly, a primary rise in p002 increases the hydrogen ion concentration (respiratory acidosis), and a fall has the reverse effect (respiratory alkalosis). However, the presentation of these disturbances is somewhat more complicated owing to the fact that the body reacts to these changes and attempts to compensate (in part) for the effect of these changes. Furthermore, different compensating mechanisms respond at different rates. A disturbance which has been properly compensated is called compensated, otherwise it is called uncompensated. The actual changes in the bicarbonate–carbonic acid concentrations in these disturbances is shown in figure 3. The nomogram of acid-base disturbances [Schwartz65, Cohen66] shown in figure 3 summarizes the normal physiologic response to the changes in HCO3 and pCO2 for each of the acid-base disturbances described above. For example, the nomogram shows that for a patient with adequately compensated metabolic acidosis and with serum concentration of HCO3 of 15 meq/L the p002 will be approximately 30 mmHg. The use of this nomogram for initial evaluation of a / patient's acid-base state will be discussed later.
The most frequently encountered clinical acid-base disorders occur as single disorders (also called simple disorders). The single disorders are: metabolic acidosis, metabolic alkalosis, respiratory acidosis, and respiratory alkalosis. There are, however, many clinical situations in which combinations of two or three disorders occur simultaneously, giving rise to mixed disorders. The recognition of mixed disorders is predicated upon a clear understanding of the pathophysiologic effects of simple disorders. To diagnose mixed disorders, one must know how each of the four simple disorders named above alter pH, pCO2 and HCO3 and the extent of renal or respiratory compensation that ought to occur for any given degree of primary disorder. However, since each of the disturbances can be caused by a variety of physiological states or diseases, the final differentiation between possible acid-base disorders must be made primarily on the basis of clinical information.
| Fig. 3. Nomogram of acid-base disturbances |
 |
An important test in the diagnosis of electrolyte and acid-base disturbances is the laboratory analysis of a patient's blood sample. Also called the serum electrolytes, this test measures the concentrations of sodium (Na), potassium (K), chloride (Cl), and bicarbonate (HCO3). Very often a test for concentration of creatinine is also made. This test does not, however, measure the concentrations of anions such as phosphate, sulfate, proteins, and organic acids which are normally present in the blood in small amounts. The combined concentrations of these unmeasured anions is called the anion gap. The anion gap can be approximated by subtracting from the combined sodium and potassium concentrations the combined concentration of chloride and bicarbonate, an amount normally approximately 12 meq/L.
Determination of the anion gap is vital to the diagnosis and differentiation of metabolic acidosis. The anion gap differentiates metabolic acidosis into two categories: one with an increased anion gap and other with a normal anion gap. Metabolic acidosis with an increased anion gap is generally caused by increased production or impaired excretion of H + and unmeasured anions by the body. For example, diabetic ketoacidosis, in which the acidosis results from increased production of ketones. On the other hand normal anion gap acidosis is generally caused by loss of HCO3. For example, diarrhea, in which HCO3 rich gastrointestinal fluids are lost.
In this section we discuss some of the characteristics required of the program if it is to be useful and effective as an expert consultant. They also serve as guiding principles for designing and evaluating the program. They are included here to communicate our aspirations. The goals described below have not been fully realized by the research reported here, nor can they all be fully realized by the current state of AIM technology. These characteristics are:
The primary responsibility of the diagnostic program is to make a correct diagnosis. Without fulfilling this criterion, the program offers little possibility of being clinically useful. Although the issues involved in the evaluation of the efficacy of diagnosis by a program (or by a clinician) are difficult and controversial, it is clear that the diagnosis arrived at by the program must be a reasonable and thorough diagnosis in the light of the available information. Furthermore, a distinction must be made between a working diagnosis and the correct diagnosis. In practice, a correct diagnosis is often impossible owing to the high cost (medical and economic) of the information necessary to achieve it. A criterion for deciding when a working diagnosis has been achieved (for the purpose of management of a patient) should weigh the costs of gathering further information in terms of morbidity, time and money vs. the benefits of better diagnosis in terms of an improved management plan and a more reliable prognosis. For example, in situations in which the management plan for each of the diagnostic possibilities is the same, attempts to distinguish between diagnostic alternatives does not have any immediate utility. Hence, the working diagnosis should be considered sufficient. It should, however, re-evaluate the diagnosis as new information becomes available from the evolution of the disease or from the patient's response to therapy.
Typically, a patient is examined by a physician more than once. The interaction between the patient and the physician can be divided into the initial interaction and the follow-ups. The follow, up sessions are used by physicians in evaluating the management plans and in refining the working diagnosis. In the majority of cases, follow-up sessions are essential for the proper practice of medicine. Furthermore, the ability to review the diagnostic decision during follow-up allows a program to revise its erroneous or incomplete conclusions.
The diagnostic style used by a program is almost as important as reaching the correct diagnosis. Although good style is hard to characterize and even harder to embody in a program, certain aspects of diagnostic style are recognizable. For example, if the program pursues some low priority diagnostic problem in the face of more important issues, if it ignores a problem of life-threatening character, or if the stream of questions seem pointless (i.e., if the program continues to ask questions when it should have been prescribing treatment), it is likely to be rejected by the user physician.
We wish to design a program which will exhibit focused, coherent and purposeful behavior in problem solving and will know when to call a halt to its question and make an interim diagnostic judgment. In a later section we will discuss how some of these requirements can be met using notions such as hypothetical reasoning and planning.
A distinction is often made between two forms of data acquisition in diagnosis: active and passive [Gorry68]. A passive mode is one in which the program is provided with all the information at one point and must make a diagnosis based on this information. An active mode is one in which the program must ask a question in order to obtain each new piece of information. The active process suffers from the shortcoming that the physician may be aware of some facts potentially useful in the diagnosis, but may not be able to communicate them to the program because each new piece of information must be requested by the program. The passive approach avoids this problem but places the responsibility of identifying relevant information on the physician. This is an unacceptable demand on a physician who is not an expert in the medical domain of the program.
Therefore, we propose a compromise position involving mixed initiative. In this mode, as in the active mode, the primary responsibility of gathering information still rests with the program. However, at each point in the consultation the user physician is allowed to provide a suggestion. The program must analyze this suggestion,3 even if it chooses to ignore the suggestion as being irrelevant.
In virtually any diagnostic workup a large amount of discrepant information must be dealt with. Some of the discrepancies arise because patients are not always accurate observers of their symptoms and because laboratory tests and medical records are often in error. In other cases a seeming discrepancy may arise because of incomplete information, i.e. there may be a valid (but so far unknown) explanation for the apparent disagreement. Correct evaluation of each type of discrepancy is critical, if the program is to perform effectively. It is necessary for a diagnostic program to be able to identify the discrepant information as it is presented in order to be able to evaluate a discrepancy and choose strategies for dealing with it before incorporating it in the patient model. We have observed that the expectations of the physician play an important role in identifying possible discrepancies in the incoming information. They allows the physician to locally evaluate these discrepancies (with respect to the available evidence, physiological possibilities and the current hypothesis) and act upon them before assimilating the new information into his patient descriptions. A similar mechanism in the program is desirable. Summarizing, the importance of good handling of discrepant information can not be overstated, especially when the system is expected to be used in a normal clinical setting as well as in experimental situations.
To be acceptable in an application domain such as medicine, an AIM program must go beyond providing competent advice; it must be able to explain and justify its conclusions to the user physician—much as the human consultants do today—in a language that the physician is familiar with. After all, it is the physician who provides the medical care and is primarily responsible for the welfare of the patient. It is therefore natural (even desirable) for a physician to balk at accepting advice from a “black-box” program. This reluctance perhaps accounts for much of the reported antipathy of physicians even to the programs that on statistical analysis have been shown to be as good as the expert physicians [Yu79, Kulikowski81, Long80]
We believe that a program's acceptability depends crucially upon its ability to adequately explain its reasoning and justify its conclusions. It depends on the physician being able to challenge some part of the program's conclusions and having the program explore alternatives suggested by the physician. Consultation is a “two way street”; it can be effective only if the consultant (who is an expert in the subject matter) and the physician (who is familiar with the patient) cooperate. If any program is to be successful as an expert consultant it must allow for such an exchange.
The foregoing discussion may suggest that AIM programs be perfect, a requirement that can never be met in a real world of imperfect knowledge, where even the best of the expert physicians differ with one another. The thrust of our argument here is more limited. We are not demanding perfection from AIM programs, only that they be acceptable. Note that a program which is not as good as the best expert may nevertheless be fruitfully applied if it is acceptable and if its use improves the performance of the average clinician (who is not likely to be as good as the best expert in any given area of expertise).
In this thesis we are not extending the methodology of explanation generation. Our main thrust is in applying the available methodology to a much more complex domain than has been hitherto tried. However, since it has been demonstrated that generation of quality explanation can not be achieved by retrofitting a program with explanation capabilities, the program must be designed with the explanation abilities in focus [Swartout80]. Our main interest is in designing explicit representation and reasoning mechanisms in the program which will provide us with the ability to justify the program's diagnoses as well as its reasoning in achieving those diagnoses.
Teaching of diagnostic medicine is often organized around diseases, with an emphasis on associations between the diseases and signs and symptoms typically associated with them. After all, the diagnostic task is to identify the disease hypothesis which represents the true state of the world by using all available data. Based on this observation we can conceive of a simple representation of diagnostic knowledge which draws associations between disease hypotheses and data. Given this “primitive” organization, we may already envision a diagnostic algorithm consisting of the following steps:
Diagnostic Reasoning:
Information Gathering:
The above algorithm, in spite of its simplicity, already captures the essential structure of a number of diagnostic programs. The association between diseases and findings forms its static knowledge about the domain. The set of observed findings and the rank-ordered set of active disease hypotheses are its patient specific model and its understanding of the patient's illness. The process of rank-ordering disease hypotheses is its diagnostic evaluation, and the selection of an appropriate finding for inquiry Is its information gathering strategy.
The algorithm described above suffers from many inadequacies due to its oversimplification. Far more serious, however, are the problems fundamental to the model of the algorithm itself. For example, the above algorithm views diagnosis as the task of identifying that disease hypothesis which provides maximal coverage over the set of findings. Although this view of diagnosis suggests a relatively straightforward and intuitively appealing implementation, we believe this to be inadequate. Disease processes are causal; we believe that diagnosis involves providing an adequate explanation of the observed findings by reconstructing the possible sequence of causal events loading to the observed findings.
The program's information gathering strategy is limited to selecting one question at a time. At the end of this question, the program re-evaluates its diagnostic understanding, reformulates a new diagnostic problem (which may or may not be related to the previous problem) and selects the next question to ask. If after asking one question the diagnostic hypothesis being pursued is not confirmed, it must compete with all other active hypotheses for the attention of the diagnostic problem solver. In other words, the attention span of the program in solving any given problem is exactly one question. This results in diagnostic inefficiencies and incoherent question sequences. This problem is well recognized, and programs such as Internist-I and PIP have attempted to group diagnostic questions into meaningful packages, abating the problem somewhat. The work presented in this thesis is based on our belief that a substantial reformulation of the basic algorithm is needed before the problem can be adequately addressed [Szolovits8l b].
In the remaining part of this section we will briefly review the four major AIM projects dealing with diagnosis, namely Internist-I, the Present Illness Program, CASNET/Glaucoma and Mycin. A detailed description of these programs can be found in [Szolovits8l]. A good review of computer-based decision aids in medicine, using both Al and conventional computer methodologies is to be found in [Shortliffe79]. [Szolovits78] offers suggestions on the issues of choice of methodology and validation for acceptance for AIM programs. [Schwartz70] contains a discussion of acceptability issues from the viewpoint of physicians.
The Internist-I program [Pople75a, PopIe77] is based on a large data base and a relatively simple evaluation and problem-selection strategy. The Internist-I data base is constructed by linking diseases and their manifestations with two subjectively assessed scores; an evocation strength which describes how strongly the manifestation should suggest a disease, and a frequency which describes how commonly the particular manifestation is observed in a patient with a given disease. Both of these are supplied by objective assessment by physicians. All the diseases are arranged into a hierarchy organized around organ-systems. Each non-terminal in this hierarchy is linked to manifestations that are common to all its inferiors. During each cycle of the algorithm, all diseases with at least one reported manifestation are evoked4 and scored. Next, these disease hypotheses are partitioned into competing and complementary sets. This partitioning scheme represents an important contribution of the Internist-I program. It is based on two concepts: the shelf — a list of important manifestations that are not explained either by this diagnosis or any diagnoses previously confirmed, and the dominance relation — a hypothesis A is said to dominate hypothesis B if the shelf of A is a proper subset of the shelf of B. The competing set is then said to contain hypotheses that either dominate or are dominated by the highest-ranking hypothesis. All other hypotheses are considered complementary and are ignored. The competing set is further reduced by considering only those hypotheses whose scores are within a fixed range of the highest-scoring hypothesis. Based on the number and relative scores of the hypotheses under consideration a diagnostic strategy (differentiate, confirm or rule-out) is selected and the next question computed. Finally, this question is asked and the diagnostic cycle is repeated.
The Present Illness Program (PIP) [Pauker76] is a frame based [Minsky75] program for taking the present illness in the domain of renal diseases. The PIP data base is implemented using disease frames, each containing the relation of the given disease to its expected findings and to other diseases, and a scoring criterion for evaluating the disease hypothesis. Some of the findings associated with a disease are specially designated as triggers. The complementary relation between diseases is described using causal, complicational and associational links; the competing relation is expressed using differential links. Each disease frame also contains two types of scoring functions; the logical decision criteria and the numerical likelihood estimator where the first is used for categorical evaluation and the second for probabilistic evaluation of the likelihood of the disease hypothesis under consideration [Szolovits78]. The diagnostic algorithm of PIP is similar to the basic algorithm discussed before. We should note that PIP does not use the disease-hierarchy or multiple diagnostic strategies used by the Internist-I program. On the other hand, PIP uses a substantially richer representation mechanism for describing findings and diseases as compared to Internist-I. For example, PIP allows one to describe the finding of edema observed in a given patient to be “severe”, “worse in evening” and “pedal” (around legs). Finally, it uses categorical as well as probabilistic criteria for confirming diseases.
Internist-I and PIP represent medical knowledge as well as patient specific facts in phenomenological terms. The lack of physiological knowledge results in their weakness in dealing with patient illnesses with multiple interacting etiologies. The lack of physiological knowledge also results in activation of all phenomenologically possible hypotheses, including those that, based on the case-specific knowledge, are physiologically improbable. Thus, increasing the efforts needed in scoring and ruling out these hypotheses explicitly. Furthermore, the diagnostic algorithms in Internist-I and PIP alternate between obtaining a fact and evaluating the hypothesis list, resulting in a lack of focused diagnostic inquiry as discussed before.
The patient-specific model in Internist-I and PIP consists of a collection of patient facts and the list of active hypotheses; it does not relate different findings and hypotheses into causal explanations. As a result these programs have only a fragmentary understanding about the patient's condition and they often change their description of the patient's illness radically without substantial indications to that effect.
The Glaucoma program deals with the diagnosis and treatment of eye diseases. It is implemented using the CASNET [Weiss74] theory of representation of causal knowledge. The medical knowledge in Glaucoma is represented as a network of physiological states. These states are linked together by subjectively assessed transition probabilities, and by support values indicating how strongly certain test results support the presence of a particular condition (state). The transitional probabilities are used primarily as a means of selecting the most appropriate next state to investigate and the support values are used to evaluate the score (fuzzy likelihood [Gaines76, Zadeh65]) of a state, which is used to confirm or deny a state. Finally, the patterns of confirmed and denied states in the network are interpreted using a number of programs which compare the progress of the diseases in the given patient with the diseases known to the individual program.
The use of physiological knowledge gives the glaucoma program a better understanding of the mechanisms of disease evolution and interaction than the other programs discussed above. However, its use of causal knowledge is restricted to the local propagation of likelihood weights to determine the most appropriate next state for investigation. The program cannot use hypothesized diagnoses to guide its diagnostic inquiry: it separates the process of information gathering from that of diagnosis. The information gathering is directed solely towards confirming (or ruling out) states in the causal net.5 Moreover, the program works in a domain where the disease physiology is uniformly well understood and each state can be confirmed directly using some test. Therefore, the techniques developed in this program are not easily extendable to programs working in other domains of medical expertise.
Mycin is a rule-based program [Shortliffe76, Davis77] for diagnosis and treatment of infectious diseases — in particular, bacterial infections in the blood (and recently extended to other infectious diseases). It represents medical knowledge in terms of production rules [Davis77] and uses a collection of associative triples to represent the patient specific knowledge [Shortliffe75, Shortliffe76]. A novel mathematical model of confirmation [Shortliffe76] selects a set of organisms suspected of causing the illness. Diagnosis is carried out using a simple goal-directed control structure with backward chaining. The highest-level goal of Mycin is to determine if the patient is suffering from a significant infection which should be treated, and if he is, to select the appropriate therapy. It retrieves all the rules applicable to this goal and applies them sequentially as follows. It attempts to ascertain whether the “conclusion” of a rule is valid by evaluating each of its premises. If this information is already available in the data base, the /
program retrieves it. If not, determination of this premise becomes the new goal, and the program recurs. If after trying all the relevant rules, the answer still has not been discovered, the program asks the user for the relevant clinical information which will permit it to establish the validity of the premise clause. Thus, the rules “unwind” to produce a succession of goals, and it is this attempt to achieve each goal that drives the consultation.
The rules in Mycin are used to represent the domain knowledge as well as to encode the flow of control of the program. This takes away some of the advantages of modularity of knowledge because one must take into account the possible interactions between rules during problem solving. The goal structure of Mycin allows efficient problem solving and can be used for explaining the problem solving behavior of the program, but the program cannot explain the medical significance of its behavior as this information is compiled out while writing the rules.
The rule-based Mycin methodology is applicable in field~ where the domain specific knowledge can be described using judgmental rules. It appears to require a field which has attained a certain level of formalization with a generally recognized set of primitives and a minimal understanding of basic processes and which does not have a high level of interaction between conceptual primitives [Davis77]. Finally, the rule-based methodology developed by Mycin and its derivative programs can be used effectively in encoding knowledge needed in handling specific well defined situations such as special heuristics for differentiation between two similar diseases which are difficult to differentiate using global differentiation heuristics.
The programs described above can be classified as the “first generation AIM programs”. These programs have contributed immensely by demonstrating the feasibility of using computers (and Al techniques) in medical diagnosis. Some of the significant developments in this regard are summarized here.
The active hypothesis set introduced in PIP and the hierarchic organization of diseases introduced in Internist-I provide useful techniques for organizing programs for efficiency. A heuristic to partition the hypothesis set into competing and complementary sets was introduced in Internist-I. In spite of its shortcomings, the partitioning heuristic is intuitively appealing and empirically effective [Pople75a]. An improved technique for identifying complementary and competing hypotheses, especially for illnesses caused by multiple diseases, is one of the topics of interest in this thesis.
Recognizing that pathognomonic and important evocative findings help to focus the diagnostician's attention sharply, mechanisms to flag such findings and their use in focusing the programs' attention were developed in Internist-I and PIP. Heuristics to help confirm or eliminate hypotheses categorically (without resorting to revising probabilities and thresholds) and explicit differential diagnosis links to indicate well-known points of diagnostic confusion were also added in PIP.
Causality as a major mechanism for tying together independent hypothesized disorders was identified as a fundamental mechanism in the CASNET/Glaucoma program, Internist-I and PIP. The Glaucoma program went a step beyond the others in the use of causality by defining disease as a progression of causally connected states. However, in all three programs, the use of causality is limited to propagating probability-like estimates of likelihood which remain the primary criterion for their clinical decisions.
The need for explanation and justification capabilities in an AIM programs was first recognized by and implemented in MYCIN. In this chapter we have argued that these capabilities are essential for the success of any consulting program. In this thesis we take this capability to be an essential component of the design of ABEL program.
This thesis contains seven chapters and two appendices. Chapter 2 previews the capabilities of the program with the help of two simple examples. Chapter 3 describes the representation of ABEL's medical knowledge. The medical knowledge consists of a hierarchic representation of anatomical, physiological, etiological and temporal knowledge. This forms the groundwork for an efficient representation of diseases and their pathophysiology in the domain of electrolyte and acid-base disturbances. The diseases are defined in terms of their loci along these four dimensions, providing a natural hierarchic organization to the disease definitions. This framework of basic medical knowledge provides us with a vocabulary for expressing phenomenological and pathophysiological knowledge.
An expert physician may have an understanding of a difficult case in terms of several levels of detail. As noted earlier, at the shallowest level that understanding may be in terms of commonly occurring associations of syndromes and diseases, whereas at the deepest it may include the biochemical and pathophysiological interaction of abnormal findings. Chapter 3 describes a multi-level description of pathophysiology, where each level of description can be viewed as a semantic net of relations between diseases and findings. Each node in the net represents a normal or abnormal state and each link represents a relation (causal, associational, etc.) between these states. Each node is associated with a set of attributes describing the temporal characteristics, severity or value, and other relevant attributes. Each link describes a causal relation between a cause node and an effect node by specifying a multivariate relation between attributes of the cause and the effect. Additional information to support mapping knowledge at one level to an adjacent level is also described.
In Chapter 4, we propose the use of a coherent hypothesis as the logical unit of hypothesis representation. This captures our notion, expressed above, that the reasoner's hypothesis structure must account for the total state of mind of the reasoner including its current uncertainties. In the program, each coherent hypothesis is represented using a patient specific model (PSM). Each PSM represents a causal explanation of all the observed findings and their interrelationships at various levels of detail. Note that within each PSM all the diseases, findings, etc., are mutually complementary, while the alternate PSM's are mutually exclusive and competing.
The PSM is created by instantiating portions of ABEL's general medical knowledge and filling in its details from the specific case being considered. The instantiation of the PSM is very strongly guided by initially given data, because the PSM includes only those disorders and connections that are needed to explain the current case. Instantiation is accomplished by five major operators. Initial formulation creates an initial patient description from the presenting complaints and laboratory results. Aggregation and elaboration make connections between the levels of detail in the PSM by filling in the structure above and below a selected part of the network, respectively. In a domain such as ABEL's, multiple disorders in a single patient and the presence of homeostatic mechanisms require the program to reason about the joint effects of several mechanisms which collectively influence a single quantity or state. Component decomposition and summation relate disorders at the same level of detail by mutually constraining a total phenomenon and its components; the net change in any quantity must be consistent with the sum of individual changes in its parts. The final operator, projection, forges the causal links within a single level of detail in the search for causal explanations. The operators all interact because the complete PSM must be self-consistent both within each level and across all its levels. Therefore, each operation typically requires the invocation of others to complete or verify the creation of related parts of the PSM. Furthermore, PSM's are organized in a context tree allowing different PSM's to share structures common to them. The root of the PSM-tree also contains all the observed findings and diseases which have been concluded to be true so that they may be shared by all PSM's.
Locality is a desirable property for the reasoning and description schemes. It imposes modularity in the organization of knowledge, making acquisition and representation of knowledge tractable. Furthermore, it makes possible efficient reasoning schemes whose resource requirements do not grow with increasing size of the data-base.6 To exploit the locality constraint in reasoning with causal networks, a program should be able to reason based only on the information locally available from the neighborhood of the mechanism under consideration. Although it is always possible to choose a level of abstraction at which the interaction between a given pair of states can be described locally, for a given level of detail it is not possible to impose the locality constraint on every interaction. The multiple-level causal model and the abstraction/elaboration process presented in this thesis allow us to overcome this problem. For example, if at some level of detail two distant states interact, we can aggregate the description of intervening causal network to a level where the two states are adjacent to one another. The interaction between the two can now be computed locally.
Chapter 5 discusses the diagnostic problem solving activity. The diagnostic problems are formulated by identifying the weaknesses and conflicts in the PSM's. The task of the diagnostic problem solver is to resolve these conflicts and weaknesses by gathering new information. We note that the medical knowledge in the program consists of prototypes of the disease entities. However, this prototypical knowledge can be substantially constrained because the hypothesized disease entities must be consistent with the known facts and explanations. We introduce the notion of a diagnostic closure which extracts and tailors that part of medical knowledge that is directly relevant to the diagnostic task at hand. The diagnostic closure brings together all the dependencies and expectations necessary for planning a diagnostic inquiry, for evaluating real and apparent discrepancies in the incoming information, and provides a framework for explaining the alternatives under consideration and for justifying the selection of questions. Although we envision using recent advances in the planning paradigm [Fikes72, Sacerdoti75, Stefik81], the current implementation of the program generates a simple tree-structured plan for information gathering by decomposing the problem by successive applications of confirm, rule-out, differentiate, and group-and-differentiate strategies. Finally, when a sufficient amount of new information is available the program assimilates this information into the PSMs and the diagnostic process is repeated. The process terminates when an adequate explanation for the patient's illness is found or when all the information necessary for such an explanation is exhausted.
In chapter 6 we revisit the example described in chapter 2 in greater detail. Chapter 7 summarizes the experience gained and lessons learned in this enterprise and indicates pointers to future research. Finally, appendix 1 briefly summarizes the XLMS system (a knowledge representation system built on top of LISP) used by ABEL. Appendix 2 summarizes the techniques for translating the internal data structures of the program into English developed recently by Swartout [Swartout80] and discusses algorithms for organizing the concepts encoded in causal networks into a linear sequence of sentence level objects that can then be translated using the above-mentioned methodology.
This section is part of
The document was reconstructed for the Web in April 2002 by Peter Szolovits.Patil, Ramesh S. Causal Representation of Patient Illness for Electrolyte and Acid-Base Diagnosis. MIT Lab for Computer Science Technical Report TR-267. October 1981. Also: Ph.D. Thesis, MIT Dept. of Electrical Engineering and Computer Science.