| Fig. 57. The XLMS hierarchy |
 |
| This section is part of Patil, Ramesh S. Causal Representation of Patient Illness for Electrolyte and Acid-Base Diagnosis. MIT Lab for Comp. Sci. TR-267 (1981). |
The ABEL system uses XLMS to represent and manage its knowledge base. The XLMS (eXperimental Linguistic Memory System) was developed primarily by Lowell Hawkinson, William Martin, Peter Szolovits and the members of the Knowledge Based Systems and the Clinical Decision Making groups at MIT [Hawkinson80]. Although the representation of the ABEL system has been substantially influenced by the design philosophy and the details of the implementation of XLMS system, it is not necessary to have a complete understanding of the intricacies of XLMS to understand this document. This section is intended to elucidate only as much of XLMS as is required to comprehend this document. Furthermore, wherever possible, the XLMS notation is supplemented by its graphical representation to reduce the dependence of this document on the notation of the XLMS.
Perhaps the best way to think of XLMS is that it is an extension of LISP that allows one to use unique and canonical expressions and allows one to label these expressions uniquely. In LISP, atoms are used to name variables and functions. In XLMS, variables and procedures can be named by unique expressions (called concepts). Similar to LISP atoms, these concepts can have properties called attachments. They differ from the LISP in the sense that these concepts are structured objects and can have superior and inferior structures. In addition, these concepts have internal structure that can be taken apart and examined, while lisp atoms are indivisible.
In XLMS, every concept is composed of three parts: ilk, tie and cue, and is written as:
[(<ilk>*<tie> <cue>)]
or, to take an actual example from the ABEL data base:
[(concentration*u ecf-na)]
The ilk of a concept is itself a concept. It describes the concept this concept is derived from. Thus the example concept described above, is a kind of “concentration”. The cue of a concept is either a concept or a lisp symbol. It specializes the general concept described by the ilk, or in other words, indicates what it is that makes this concept different from others with the same ilk. The example represents the “concentration of ecf-na”: a particular kind of concentration. The tie of a concept indicates the relationship between the ilk and the cue. In this case, the tie is “u” for unique-role. The role ties are used to indicate slots (attributes or properties) of a concept (furthermore, a unique-role indicates that there is only one role of the kind described by the concept). Thus this concept represents the “concentration” slot in the concept of “ecf-na”. There are several other ties that are used in the system, some of them primitive to the XLMS system and some “user defined” for use in the ABEL system. These are listed in Table 1 together with examples of their use. Finally, any concept in the data-base can be (optionally) labeled using the notation
[<label> = <concept>]
or, to name the concept defined above
[serum-na = (concentration*u ecf-na)]
| Table I. | ||||||||||||||||||||||||||||||
|
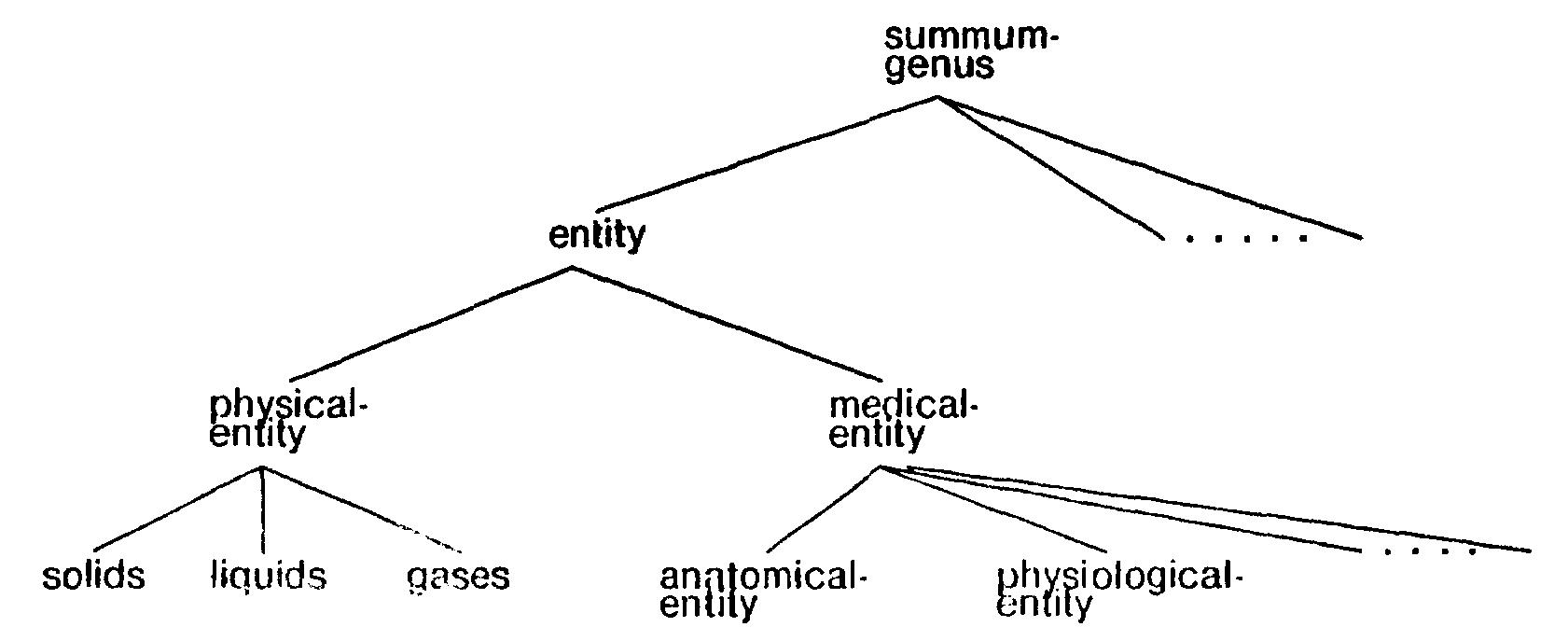
As was indicated above, concepts in XLMS are organized into an AKO hierarchy (see figure 57). The root concept is [summum-genus] and all concepts are defined as specialization of this concept.
| Fig. 57. The XLMS hierarchy |
|
|
In LISP, a symbol may have a property-list, which can be used to attach properties (lists and other atomic symbols) to a symbol. Similarly, in XLMS, we have attachment which can be used to associate concepts relating to a concept with that concept. The notation for attachment is:
[<concept> #<attachment-relation>
<attached-concept> .... <attached-concept>]
|
or, for example:
[(sex*u patient) #Value male]
The attachment-relation specifies how the concept and the attached concept (called the attachment) are related. The example above states that the slot “sex of the patient” has the “value” of “male”. An alternate way would have been to create a specific concept to describe the same relation. For example, the relation described above could be alternately specified as [((sex*u patient)*f male)] which states that the “sex of the patient” is functionally restricted to being “male”. The built in functions of XLMS tend to make it easier to work with the concept hierarchy than with attachments. Typically, primary characterizations of a concept are placed in the kind hierarchy while secondary ones are indicated by attachments [Martin79]. The commonly used attachments in the ABEL system are: #v (value), #f (function) #c (characterization), #m (meta-characterization) and #s (standard-error). Some additional attachment relations such as #meta-link are also used.
Program fragments in the ABEL system are described using sequences of XLMS concepts. Sequences are described in XLMS notation by a list of concepts separated by commas:
[<concept>,<concept> ,.... <concept>]
The reader may have noticed that the XLMS notation is delimited by square brackets. These brackets identify the concept as a piece of XLMS notation and delimit the scope of its attachments (if any). Any expression delimited by square brackets is called a complex. The first concept to appear after a left bracket is called the head of complex. If an xlms-complex is contained within some piece of XLMS notation, the XLMS reader makes any attachments or builds any structure indicated by the complex, and then replaces the complex by the head of the complex.
Finally, the colon anaphora provide a convenient shorthand for specifying the slots (roles) of a concept. If a concept appears in XLMS notation with a colon (or several colons) immediately following it, then the XLMS reader replaces that concept with a new concept whose ilk is the concept with that notation and whose tie is *r. If the colons are immediately followed by a number (e.g., 1), then the XLMS reader replaces this concept with the first instance of the new concept. If colons are immediately followed by a “u”, the XLMS reader replaces this concept with a new concept whose ilk is the concept with the concept with that notation, whose tie is *u and whose cue is the head of the complex n levels in from the top level complex, where n is the number of colons in the notation. For example:
[table [top:u #c ...]] |
==> |
[table [(top*u table) #c ...]] |
[table [leg: #c ...]] |
==> |
[table [(leg*r table) #c ...]] |
[table [leg:1 #c ...]] |
==> |
[table [((leg*r table)*i 1) #c ...]] |
A similar anaphora mechanism, but counting from the inside, is provided with the use of ^.
A simple XLMS interpreter LINT (Little INTerpreter) was implemented by the author to
execute the mapping relations associated with links and component summation/decomposition
relations associated with primitive links. The evaluation of functions and handling of arguments in
the interpreter is similar to LISP. For example, a function “(compute-ph serum-hco3
serum-pco2)” in LISP is equivalent to “[(compute-ph*c serum-hco3,serum-pco2)]” in LINT.
They differ in the way the variables are evaluated. In LINT a variable (indicated by a role tie) is
evaluated by first binding the concept containing the role (slot associated with the variable) to its
instantiation in the initiating pattern (i.e., a specific link or constituent summation) or the selected
PSM, and then accessing the value associated with the slot in the instance, or by inheriting the
appropriate default value associated with the slot. For example, evaluation of the above LINT
function in context of PSM-1 of example 1 in chapter 6 would result in binding “serum-hco3” to
“serum-hco3-1” with the value of 15.0 and similarly “serum-pco2” to “serum-pco2-1” with the
value of 30.0.
Finally, we note that the program fragments in XLMS are expressed as concepts, they are naturally organized into XLMS hierarchy of concepts allowing the program to inherit the function definition for specific tasks from more general definitions. For example, the function to compute the concentration of serum-Na from the total quantity of Na in the extracellular compartment can be computed using the more general function for computing the concentration of a serum electrolyte from its total store in the extracellular compartment.
... on to Appendix II: Explanation
This section is part of
Patil, Ramesh S. Causal Representation of Patient Illness for Electrolyte and Acid-Base Diagnosis. MIT Lab for Computer Science Technical Report TR-267. October 1981. Also: Ph.D. Thesis, MIT Dept. of Electrical Engineering and Computer Science.
The document was reconstructed for the Web in April 2002 by Peter Szolovits.