Modeling Knowledge of the Patient in Acid-Base and Electrolyte Disorders(1)
Ramesh S. Patil, Peter Szolovits, William B. Schwartz
Patil, R. S., Szolovits, P. and Schwartz, W. B.
"Modeling Knowledge of the Patient in Acid-Base and Electrolyte
Disorders" Chapter 6 in Szolovits, P. (Ed.)
Artificial
Intelligence in Medicine. Westview Press, Boulder, Colorado.
1982.
Introduction
"To imagine a language means to imagine a form of life," according
to the philosophy of Ludwig Wittgenstein [27, p. 8e] Conversely. without the
appropriate language, that form of life cannot be imagined. Programs that
attempt to reason in ways that simulate the thought processes of human beings
must use a language of thought that is adequate to the task. Inability to
express in a program the facts, hypotheses, strategies, beliefs-the panoply Of
notions arising in human reasoning inevitably diminish such programs' acumen.
Our interest here is in programs intended to advise on difficult medical
decisions. A generation of such programs, many reported on in this volume, have
been designed, implemented, and shown to be capable of expert-level performance
on a limited variety of medical problems. Yet it is clear from an examination
not of the performance but of the internal organization of these programs that
the sophistication of their capacity to represent most of what they deal with is
extremely limited. Almost universally, important notions such as the relations
between alternative hypotheses, degrees of belief, pathophysiological models of
disease, temporal relationships, diagnostic and therapeutic plans, etc., are
either missing altogether or else represented by very simple mechanisms that
miss much of the subtlety of human reasoning. Apparently the inherent redundancy
of information in most medical cases coupled with the relatively great power of
the machine to explore many possibilities, to record and maintain its
"thoughts," and to apply strategies systematically and without error
account for its ability to overcome the seemingly serious disadvantage of its
poor representations.
We have begun to develop new representational techniques for many of the
concepts underlying medical reasoning in the course of implementing a program
for the diagnosis and therapy of electrolyte and acid-base disorders (ABEL).
This chapter is intended to convey the richness of concepts that we believe are
necessary to allow major improvements in the capabilities Of AIM programs and to
lay out a set of ideas we believe will achieve that goal. The program described
here is still under development, and although our implementation already has the
ability to describe its model of the patient's condition in much better detail
than previous programs, extensive work remains in completing the whole
diagnostic program based on these ideas.
In this chapter we describe the overall design of ABEL. We support our choice
of this domain for investigating the conceptual issues we have introduced and
outline the organization of the total program into which the component discussed
here fits. We establish a set of desiderata for ABEL (and other programs).
Concentrating our attention on diagnosis, we introduce a proposed representation
of medical knowledge, discuss structural methods of encoding uncertainty using
our representations, describe the operators that manipulate and build the
representation, and present some ideas on how diagnostic problem-solving
proceeds using these data.
Domain of Expertise
To explore in depth the representations and reasoning strategies needed for
thorough medical reasoning, it is useful to choose carefully some specific
domain of medical application that poses just the right challenges. We have
chosen the domain of acid-base and electrolyte disturbances for the following
reasons.
- It is a relatively narrow area of medicine with a large body of
physiological and clinical knowledge, with a high degree of interaction
between them. The available physiologic data are often very precise, whereas
data obtained from patient's clinical history are often imprecise, yet both
must be accounted for and reconciled for a successful diagnostic solution.
- It is often an important component in the diagnosis and management of the
renal diseases, which has been the major area of medical expertise explored
in our laboratory using the Present Illness Program (PIP) [15, 16, 25].
Thus, the techniques developed in this area can be usefully extended to a
general Present Illness Program.
- The temporal characteristics of acid-base and electrolyte disturbances
challenge us with a variety of issues involved in patient management.
- Lastly, programs in die same medical area but relying on older computer
methodologies have existed for a number of years [1, 2, 6, 20] and can serve
as both a realistic bench-mark of minimum performance requirements for our
eventual program and a point of comparison for investigating the differences
of style dictated by our Al approach.
Our concern is not with acid-base and electrolyte disturbances per se.
Our basic purpose is to use this domain to determine whether it is now possible
to develop an "artificial intelligence" program which is capable of
dealing with all aspects of diagnosis and management at a level comparable to
that of an expert.
Scope of the Project
The objective of a program in the diagnostic and treatment domain is
"the proper management of the patient." That proper management
consists of collecting the relevant information about the patient, identifying
the disease process(es) responsible for the patient's illness, and prescribing a
proper course of action to correct the patient's condition.
One of the complexities of the task is that its subcomponents do not have
well defined boundaries, because a patient may be presented to a clinician at
different stages of a disorder's evolution and treatment. During the course of
management new information about the past history may become necessary as the
diagnostic hypotheses evolve. The diagnosis may also depend on information that
is presently unavailable (e.g., serum electrolytes that have been drawn but not
reported by the laboratory). The disorder itself may evolve through time,
providing additional clues to its identity. Further, at times the response to a
certain treatment itself may be the best clue to the diagnosis. Therefore, the
clinician must choose the next course of action from a large range of
alternatives, which can be broadly classified as gathering more information
(much of which may turn out to be irrelevant in the current clinical
evaluation), ordering further tests (involving possibly expensive time delays
and/or clinical costs), waiting for further development, prescribing therapy or
some combination of the above.
At every stage of expert consultation, the program must be able to choose
between alternative actions available to it with the objective of maximizing the
utility of the action to the patient. This can be achieved in a computer program
only by developing a system capable of both diagnosis and therapy, i.e., of
choosing between the various alternatives available to a physician during
patient care. With this in view we are building ABEL, the Acid-Base and
Electrolyte Consultant system, which will ultimately address each of the above
mentioned aspects of diagnosis and management. Our objective is to separate and
modularize different components of the program's knowledge so that we can
evaluate our understanding of each and study their interactions. This should
also allow us to further experiment with, redesign, and implement any component
of the system without having to reimplement the entire program.
The Acid-Base and Electrolyte Consultant system will therefore consist of
four major components: (i) the Patient-Specific Model (PSM), (ii) the Global
Decision-Making component, (iii) the Diagnostic component, and (iv) the Therapy
component. The PSM describes the physician's understanding of the state of the
patient at any point during diagnosis and management. This PSM is used as a
central data structure with which other components of the system may reason. The
global decision-making component is the top level program which has the
responsibility of calling the other programs with specific tasks.
|
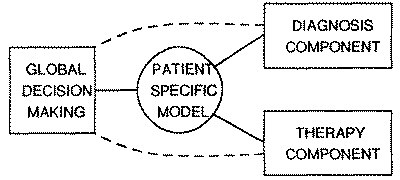
Fig. 1. The ABEL System is organized around knowledge of the Patient
and the program's hypotheses as represented by the Patient-Specific
Model. The global decision-making module invokes specialists for
diagnosis and for planning and execution of treatment.
|
In general the global decision program will instruct the diagnostic program
to carry out a task such as "take the initial history," or
"elaborate a specific diagnosis." The diagnostic component then
performs the specified task and reports the results to the main program. It also
modifies the PSM to reflect the revised state of understanding of the patient.
Similarly if the global decision-making program calls the therapy-selection
program, it attempts to formulate a set of possible therapies for the patient
along with a check-list of items that must be tested before any specific therapy
can be recommended. It also identifies information that will help discriminate
between alternative therapeutic recommendations. This information then is
reformulated and sent to the diagnostic program as the next problem to be
solved.
The approach of separating global decision-making, diagnostic and therapeutic
activities allows us to make explicit the decision-making that goes on in a
physician's reasoning. Is further diagnosis necessary? What treatment should be
selected? Should we wait before prescribing further treatment? Can we choose
some therapeutic action that would also provide diagnostic information, thus
making a further effort directed solely at diagnosis unnecessary at this time.
Although the therapeutic capability of the program is ultimately a key
element of die proposed system, it is the development of the patient-specific
model and the diagnostic subprogram which first claims our attention. Because
diagnosis must encompass past evidence of therapy, most of the conceptual
problems of therapeutic evaluation occur in a diagnostic program even when it is
decoupled from its eventual therapeutic partner. Therefore, we have concentrated
first on die patient-description and diagnostic components of the system, and it
is these that will be discussed here. Our work on therapy and on the problem of
interfacing diagnosis and therapy is still in a rather preliminary state and
will not be considered in this paper.
Desiderata
In this section we present some of the characteristics required of our
program (indeed, any comprehensive medical management program) if it is
ultimately to be useful and effective as an expert consultant.
Making the Proper Diagnosis
The primary responsibility of the program is to make the proper diagnosis.
Without fulfilling this criterion, the program offers little possibility of
being clinically useful. A criterion for deciding when a satisfactory diagnosis
has been reached (and the program should move on to therapy) should weigh the
costs of gathering further information in terms of morbidity, discomfort, time
and money vs. the benefits of better diagnosis in terms of an improved
management plan and a more reliable prognosis. For example, in situations in
which the management plan for each of the diagnostic possibilities is the same,
further attempts to distinguish between alternatives do not have any utility.
Hence, the diagnosis should be considered sufficient. Furthermore, because the
program is able to re-evaluate the diagnosis as the disease evolves, it should
be able to defer further diagnosis in favor of "creative indecision"
[26].
Mode of Interaction
A distinction is often made between two forms of data acquisition in
diagnosis: active and passive [7]. The active approach includes the computer's
asking a question in order to obtain each new piece of information from the
patient. A passive mode is one in which the program is provided with all the
information at one point and must make a diagnosis based on this information.
The active process suffers from the shortcoming that the physician may be aware
of some facts potentially useful to the diagnostic process, but may not be able
to communicate them to the program because each new piece of information must be
requested by the program. The passive approach avoids this problem but places
the responsibility of identifying relevant information on the physician. But, as
the user physician is not expected to be an expert in the medical domain of the
program, this restriction is unacceptable. Therefore, for the purpose of this
program we have chosen a variation of the active process, where the user is
allowed to provide any amount of initial information (called presenting
information), and from then on the program seeks information in the active mode.
At each point in the diagnostic process we allow the user to shift the program
into the passive mode so that he can enter new information which he thinks may
be useful.
Diagnostic Style
'Me diagnostic style used by the program is almost as important as reaching
the correct diagnosis. If the program jumps around among different medical
problems under consideration-if its behavior is erratic-the user cannot develop
a good model of the program's reasoning. This makes communication between the
program and its user confusing and annoying. If the program pursues some low
priority diagnostic problem in the face of more important issues, if it ignores
a problem of life-threatening character, or if the stream of questions seem
pointless, (e.g., if the program continues to ask questions when it should have
begun prescribing treatment) it is likely to be rejected by the physician user.
We require that our program exhibit focused, coherent and purposeful behavior
in problem-solving, know when to call a halt to its questioning, and be capable
of making an interim diagnostic judgment.
Handling Discrepant Information
In virtually any diagnostic workup a large amount of discrepant information
must be dealt with. Some of the discrepancies arise because patients are not
always accurate observers of their symptoms and because laboratory tests and
medical records are often in error. In other cases a seeming discrepancy may
arise because of incomplete information, i.e., there may be a valid (but so far
unknown) explanation for the apparent disagreement. In addition, there are many
cases in which the discrepancy only exists in the context of some currently held
but as yet unproven hypothesis. Correct evaluation of each type of discrepancy
is critical if the program is to perform effectively. Obviously the expectations
of the physician play an important part in identifying and locally evaluating
these discrepancies in the incoming information.
Continued Management of the Patient
Typically, a patient is examined by a physician more than once. Thus, the
interaction between the patient and physician can be divided into the initial
interaction and follow-ups. The follow-up sessions are used by physicians in
evaluating their management plans and in refining the diagnosis. In many cases
the follow-up sessions are essential for proper diagnosis and appropriate
management, and the usefulness of a consulting program is grossly diminished if
it cannot follow a given patient over a period of time. Ibis implies a need for
the program to maintain a record of its interactions with each patient's case.
In the case of the ABEL program, the PSM, which is retained from one session to
the next, provides the basis for future interactions.
Explanation
The conclusions reached by the Program should be supportable by a medically
meaningful explanation of how the conclusion was reached. Without the ability to
explain its behavior and knowledge, the program appears as a "black
box"; the theory of its operation is nearly impossible to examine
critically or to correct, and its recommendations are likely to be greeted with
skepticism by the medical community. Therefore, the communication of reasoning
and knowledge used by the program is critical to the credibility and
acceptability of the computer program as a clinical aid and also to its
usefulness as a model for future development of the technology.
Research in the generation of explanations accessible to its users is not one
of the immediate goals of our development Of ABEL, but we have been able to
adapt some of the techniques and programs created by Dr. William Swartout for
explaining the behavior and recommendations of an expert program for digitalis
therapy [24].
Diagnosis
Diagnosis is the process of seeking information and identifying disease
processes causing the patient's illness. It consists of ascertaining what the
facts are and what the facts mean. Both are essential. Identifying the patient's
illness clearly depends on the facts that are already known: less obviously,
however, the process of active information gathering depends on the program's
understanding and analysis of the available facts. From protocol analysis,
researchers have observed that doctors generally use a set of hypotheses
(tentative diagnoses) to organize their beliefs and to search for new
information efficiently [5, 8, 10, 15, 21]. Therefore, it seems reasonable to
organize the program around a problem-solving paradigm using a mechanism for
generation and revision of hypotheses. The use of hypotheses allows the program
to organize sets of patient-specific findings into a small number of chunks. It
also provides the program with a framework to help communicate its "thought
processes" to the clinician.
As we argued in the introduction, powerful facilities for representing
medical knowledge in much of its innate subtlety are needed. From our experience
with existing diagnostic systems and a careful evaluation of the Present Illness
Program [15, 16, 25, 26], we are convinced that the power of existing
representations is inadequate to state what the physician understands about a
patient's illness, and therefore provides an insufficient base on which to build
a program that achieves our desired level of expertise. The patient-description
must unify all the known facts about the patient, their suspected
interrelationships, the hypotheses, and how the hypotheses account for various
known and hypothesized findings. As the physician's knowledge is expressed at
various levels of detail, from deep physiological and causal knowledge to global
knowledge about syndromic and phenomenological correlations, we need a
representational scheme that can unify these descriptions. We also need
mechanisms for moving from one level of description to another. We have
developed a patient-specific model (the PSM) and an associated
knowledge-representation scheme which attempts to construct a hierarchic
description with the above objectives in mind. This is the central
patient-specific data structure of the system.
How is a program to sift through the countless possible hypotheses it could
entertain to find those most useful for furthering the investigation and
ultimately for solving the diagnostic problem? We suggest that the best scheme
is for the program to combine all its evidence into a single expression of its
understanding, to use that expression to suggest new data to be gathered, and to
revise the expression to incorporate the newly-gained information. We assume
that in our medical domain a small set of initial findings will give us the
capability of generating a few most promising key hypotheses. Then we employ the
hypothesize and reformulate method to revise and refine the program's
PSM.
To appreciate the advantages of this approach, consider for the moment an
alternative program structure in which after each newly-discovered bit of
information the program generates de novo a new set of hypotheses. Stich a
process is inherently inefficient because it requires a large amount of
information processing (much of it repetitive) and lacks the continuity of
thought process so essential to human problem-solving and to the human
understanding of program's reasoning,
Uncertainty in our general medical knowledge and in our knowledge of facts
about each individual patient creates the diagnostic problem. 'Me task of
diagnosis ideally involves confirming an hypothesis (or hypotheses) and
eliminating all other competing hypotheses. Multiple possible diagnoses are
initially entertained because several disorders may actually coexist in a
patient and because the diagnostician may not be able to eliminate all but the
right possibility. We note that uncertainty has two distinct components, which
should not be treated equivalently. First, lack of precision in our knowledge of
disease processes and lack of tools that make perfect observations introduce chance
as a source of uncertainty. For example, we cannot predict which of a set of
seemingly- identical patients will respond to some therapy and which will not,
although we may know that in general a certain fraction respond. Second, our lack
of information about a particular patient contributes to uncertainty because
before that information is obtained any of numerous alternatives may have to be
considered possible. The chief difference between these two components is that
chance can only be measured or estimated, whereas gaps in our knowledge of a
patient may often be eliminated at the cost and effort of further investigation.(2)
Uncertainty due to chance is reflected in the patient-description by
hypotheses with a low belief-value (or probability, score, certainty factor,
etc.) whereas lack of information is reflected by a multiplicity of tenable
competing interpretations of the data. The task of the diagnostic problem-solver
is then to identify and (if possible) eliminate the uncertainty due to chance
and to the lack of information in the patient-description.
The only method available to the problem-solver is to seek new information
about the patient. A simple information acquisition strategy would pursue each
piece of needed information independently of its need for other data. For
example, the program could ask questions intended to explore whether each
potential hypothesis is adequately supported. Such a strategy corresponds to
trying to confirm all suggested hypotheses. Alternatively, the program
could consider in groups each set of hypotheses resulting from a lack of
knowledge about the patient and could suggest questions to select one from among
each group. This is a version of differential diagnosis.
The principal drawback of the above information acquisition strategy is that
it is too unfocused and potentially inefficient. It would attempt to confirm
each tenable hypothesis and to differentiate among each set of suggested
alternatives independently, without taking into consideration the other
acquisition tasks it also faces. Let us call each instance of attempted
confirmation and attempted differentiation a problem. Then, instead of
pursuing each separately, we propose to collect them all into a single
problem-set, and then to apply planning techniques to extract a proposed
sequence of questions that most efficiently and systematically reduces
uncertainty in each problem being considered. Fortunately this is possible
because many of the problems being considered hinge on the same set of
observations.
The problem-set will be used to formulate a top-level information-gathering
goal. A plan for problem-solving will be generated by decomposing this goal
successively into subgoals in the context of the patient-description. Each goal
in the plan is associated with the parts of the patient-description relevant to
it and with prior expectations about the outcome of the problem-solving effort.
The association between the goal structure and the patient-description allows us
to separate patient-specific information relevant to the immediate diagnostic
problem from information not directly relevant. The expectations associated with
the goal structure provide us with the context in which to evaluate the incoming
information for discrepancies.
The decomposition of the diagnostic goal into subgoals will be done using
various diagnostic strategies based on the protocol analyses by Miller [101,
Kassirer [81 and Elstein [5]. The strategies are Confirm, Rule-Out,
Differentiate, Group-and-Differentiate, Refine and Explore (the first three
strategies have also been used in INTERNIST-I [18], but their application is
quite different). The choice of an appropriate strategy for a given situation
can be based on the number of hypotheses in the primary goal and their relative
belief values.
Representation of Medical Knowledge
The knowledge used by a diagnostic program can be divided into two classes:
knowledge about disease and its presentation in a patient, and heuristic
problem-solving knowledge. In this section we discuss the representation of
knowledge about disease, both general and patient-specific, leaving
problem-solving knowledge for later. As the representations of general and of
patient-specific knowledge share similar descriptive schemes, we will deal with
them concurrently.
Node
Illness can be described as a change in the normal state or function in a
patient. To describe an illness, we need a formalism to represent die states,
the state changes, die normal and the abnormal functions and their interactions
in a patient in terms of the primitives known to the system. It is also
important to recognize various composite situations in order to get a global
perspective of the patient's illness. Recognition of these situations provides a
diagnostic system with tile important ability to reason at a high level of
abstraction, organizing a large number of seemingly unrelated facts; more
importantly, it may allow the system to use clinical diagnostic knowledge which
is organized around high level concepts. Therefore, die diagnostic system should
allow descriptions to be in terms of both high level concepts such as diseases
and detailed physiological states and processes underlying the presentation of
the illness in a patient.
The program's knowledge of medicine and information and hypotheses about thee
patient are expressed in terms of nodes that represent states and state changes,
and links that express connections between the nodes. Nodes may be primitive if
they contain no internal structure or composite if they may be defined in terms
of other nodes. A node in the system is described by its temporal
characteristics, severity and other aspects relevant to the node. Medically,
nodes represent diseases and clinical and pathophysiological states, and normal
or abnormal values of quantifiable parameters.
One important function of diagnostic reasoning is to relate causally the
diseases and symptoms observed in a patient. These causal relations play a
central role in identifying groups of nodes that can be meaningfully aggregated.
'Me presence or absence of a causal relation between a pair of nodes can change
their diagnostic, prognostic and etiologic interpretations. Therefore, the
system should have the capability of hypothesizing about the presence or absence
of a causal link. We also note that, in a manner similar to node descriptions, a
causal relation can be described at various levels of abstraction.
Link
A link specifies the relation between two nodes. In the past (pip, INTERNIST,
CASNET/Glaucoma), links were used to describe causal relations between nodes.
From our study, we have come to the conclusion that this single representation
of the interaction between nodes is inadequate, because this representation
forces us to assume that every interaction between nodes is causal (or at least
statistical) in nature. We believe that the interaction between nodes occurs at
various qualitatively distinct levels. For example, two nodes may be causally
related to one another, or they may be associated with one another in a
statistical sense, without any known causal relation between them, or the
presence of one of the nodes may alter the interpretation of the other node
without changing the likelihood of the other node in any significant predictable
way. To capture these differences, we use the three types of links described
below. Further, we believe that a link between a pair of nodes may or may not be
present in a given patient (for example, although hypotension and acute tubular
necrosis are causally related in general, they may not be related in a given
patient). Therefore, in order to reason with relations between a pair of nodes
in the patient-specific model, we must instantiate links and incorporate them in
the model.(3)
Causal link. A causal link specifies the "cause-effect"
relation between the cause (the antecedent) and the effect (the
consequent) nodes. In previous programs, causal links were described by noting
die type of causal relation (may-be-caused-by, complication-of, etc.) and a
number representing in some form the likelihood (conditional probability) of
observing the effect given the cause. However, die conditional probability of
observing an effect given the cause (or vice versa) depends upon various aspects
of the cause, such as severity, duration etc., as well as other factors in die
context in which die link is invoked (such as the age, sex, weight, etc., of die
patient and the current hypothesis held by the program). For the effective use
of a causal relation, we need to take these conditions into consideration. To
illustrate this, let us consider (a simplified) causal relation between diarrhea
and metabolic-acidosis. In terms of conditional likelihood, we could state the
relation as
P(Metabolic-Acidosis|Diarrhea) = 0.7
(the probability of observing Metabolic-Acidosis given Diarrhea is 0.7). A
more complete description of the causal relationship might be given in a
rule-like form as follows:
IF DIARRHEA IS SEVERE AND ITS DURATION IS GREATER THAN TWO DAYS
THEN
IF THE PATIENT HAS NOT RECEIVED BICARBONATE-THERAPY RECENTLY
THEN THE PATIENT MAY HAVE MODERATELY SEVERE
METABOLIC-ACIDOSIS WITH NORMAL ANION-GAP
ELSE THE PATIENT MAY HAVE A MILD METABOLIC-ACIDOSIS
WITH NORMAL ANION-GAP.
From the above example it is apparent that the conditional probability of
observing metabolic-acidosis and its severity and duration depend on the
severity and duration of diarrhea and bicarbonate- therapy. Generalizing, it
appears reasonable to expect that causal links between the cause and effect
nodes should contain the information on how an instance of the cause relates to
an instance of effect and on other factors influencing the relation.
To summarize, a causal link in the system is an object denoting the causal
relation between a cause-effect pair. It specifies a multivariate relation
between various aspects of the cause and the effect, taking into account the
context and the assumptions under which the causal relation is being
instantiated. A schematic description of a causal link is presented in Fig.
2.
The mapping relation permits the computation of a value for any of the
attributes of the cause or effect given some (perhaps incomplete) subset of the
values of the other attributes. A common use of this facility is to compute some
aspect of the description of an effect from knowing its cause; e.g., the
severity of the effect from the severity and duration of the cause. The mapping
relation may also be used to infer in the opposite direction, for example
permitting the calculation of the duration of the cause given its severity and
the severity of its effects. Ibis representation of causal relationships and the
associated computations permit only purely local information to be used. We have
found it necessary to allow the computations on a link to depend in addition on
a limited number of non-local factors (the context) and on globally held default
assumptions as well.(4)
|
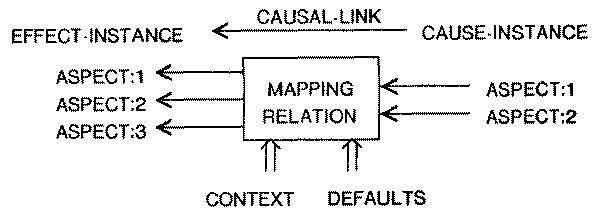
Fig. 2 A causal link in ABEL represents not only a cause and effect but a
multivariate relationship between various aspects of the cause and effect, and
permits incorporation of the effects of the diagnostic context and assumptions.
|
Associational link. This link indicates that the presence of one node
influences the expectation about the presence or absence of the other node. It
suggests that the two nodes are correlated, but does not specify the reason for the correlation or
association between the nodes. For example (Fig. 3), it is well known that
severe hyponatremia is associated with central nervous system disorders such as
coma, stupor and confusion. But the specific physiology for the causation of
these disorders is not well understood.
|
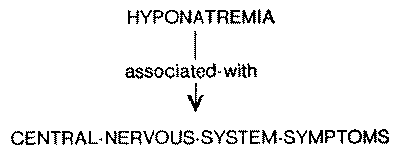
Fig. 3. Associational links specify a known co-occurrence without causal
connection.
|
Grouping link. Grouping links state that the presence of two nodes
simultaneously (in the patient-specific model) represents a situation which is
recognized as a part of some useful abstraction. This link does not imply any
correlation or causal connection between the nodes connected by the link. In
other words this link is used to group together nodes without any commitment to
their mutual cause-effect relation. For example, let us consider the group of
symptoms: severe hyponatremia, low creatinine (less than 0.6) and normal
bicarbonate (Fig. 4). This group of findings is strongly suggestive of die
syndrome of inappropriate secretion of antidiuretic hormone (SIADH). They are
grouped together in the program, which can then use a recognized instance of the
grouping to suggest SIADH at higher levels of aggregation.
|
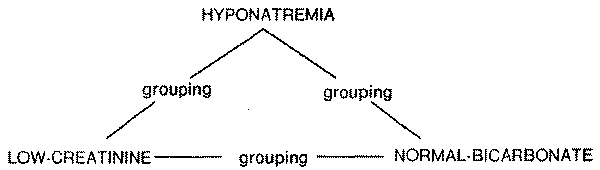
Fig 4. Grouping links suggest constellations of findings whose co-occurrence
should routinely be recognized. in this instance, the grouping is strongly
suggestive of the syndrome of inappropriate secretion of antidiuretic hormone (SIADH).
|
Hierarchic Description of Nodes and Links
In this section we discuss a hierarchic representation scheme for the
description of the program's patient-specific knowledge. In this representation,
the deepest level of the proposed hierarchy describes the knowledge about the
patient in terms of primitive physiological concepts and relations known to the
system. This physiological description is then successively aggregated into
higher level concepts and relations, gradually shifting the emphasis from
physiologic to syndromic description or, in other words, from causal to
phenomenological descriptions. The phenomenological nature of the aggregate
description allows us to use efficiently the hypothesize and match paradigm [111
for global problem-solving. The presence of the aggregated descriptions
increases the efficiency of problern-solving by sometimes casting out a large
class of possible interpretations of the data. For example, no single
disturbance hypothesis about a patient can be consistent with a normal pH.
Because the PSM must be causally and physiologically consistent at every level
of description, its use restricts the number of hypotheses generated to a small
number. We first introduce node and Iink aggregations with the help of examples.
Example 1: Hierarchic description of nodes. To illustrate the concept of a
node aggregation, let us consider the condition of excessive loss of lower
gastrointestinal fluid (Lower-GI-Loss). The compositions of the lower GI fluid
and the plasma are as shown in Fig. 5.
|
|
LOWER GI FLUID |
|
PLASMA |
|
| Na |
|
100 |
- |
110 |
|
138 |
- |
145 |
mEq/l |
| K |
|
30 |
- |
40 |
|
4 |
- |
5 |
mEq/l |
| Cl |
|
60 |
- |
90 |
|
100 |
- |
110 |
mEq/l |
| HCO3 |
|
30 |
- |
60 |
|
24 |
- |
28 |
mEq/l |
Fig. 5. Composition of lower gastro-intestinal fluid and of plasma.
|
In comparison with plasma, the lower GI fluid is rich in bicarbonate and
potassium and is deficient in sodium and chloride (except in the rare disorder
characterized by hyperchloremic diarrhea). This information is represented in
the knowledge-base by decomposing lower GI fluid into its constituents (and
associating appropriate quantitative information with the decomposition) as
shown in Fig. 5. The loss of lower GI fluid thus leads to the loss of
corresponding quantities of its constituents as shown in Fig. 6 (the
quantitative relation is not shown for reasons of clarity).(5) Therefore, lower GI
losses occurring without proper replacement of electrolytes and water will
result in hypobicarbonatemia, hypokalemia, hyperchloremia, hypernatremia, and
volume-loss, as shown in Fig. 7. At the next level of detail we can describe the
causes and consequences of lower GI loss as shown in Fig. 8.
|

Fig. 6. Loss of lower gastro-intestinal fluid is accompanied by loss of the
electrolytes it contains.
|

Fig. 7. Direct results of the loss of lower gastro-intestinal fluids.
|
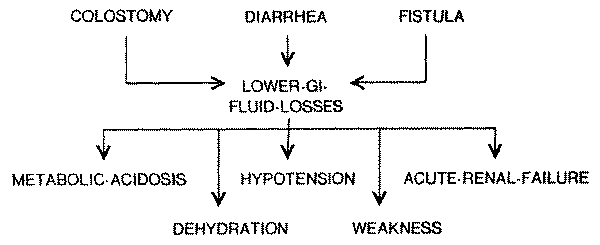
Fig. 8. Causal relations surrounding lower gastro-intestinal fluid loss at a
more aggregate clinical level.
|
Example 2: Hierarchic description of causal relations. To illustrate the
concept of a multi-level description of a causal link, let us consider the
following aggregate causal assertion. The causal mechanism of diarrheal
dehydration can be explained as follows: diarrhea causes lower gastrointestinal
loss which causes dehydration. (Compare Figs. 9 and 10.)
|

Fig. 9. Clinically, diarrhea is known as a possible cause of dehydration.
|
|
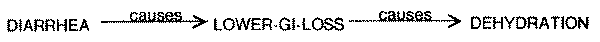
Fig. 10. Diarrhea causes dehydration by causing the loss of lower GI fluid.
|
In greater detail, the lower gastrointestinal fluid loss consists of water
loss along with the loss of electrolytes (electrolyte losses are not shown here
for simplicity of presentation) which results in dehydration if the water loss
is not replaced by fluid intake or administration (Fig. 11). Identifying that it
is the loss of water that leads to dehydration (as opposed to other components
of the GI fluid) is useful because it focuses reasoning on the issues of water
balance.
|

Fig. 11. The link of Fig. 10, expanded to show the detail of water balance.
|
Types of Aggregations
The hierarchic patient-description structure is built by aggregating low
level concepts into higher level concepts or by disaggregating high level
concepts into their constituents at lower levels. Aggregation allows us to
summarize the network of cause and effect nodes describing the patient's illness
by substituting aggregate nodes for large chunks of the causal networks and by
retaining only the important nodes (analogous to landmarks in a conceptual map
[9]). The aggregations and disaggregations can be divided into five classes,
described below.
Temporal Aggregation. An observation provides us (clinician or program) with
a snapshot of the state of some process. During the course of evolution of a
patient's illness, a sequence of snap-shots becomes available to the program.
These snap-shots describe the progress of a process through time. Temporal
aggregation allows us to resynthesize the process and describe it as a single
concept in the patient-specific model. Further, temporal aggregation allows us
to summarize a sequence of values of a state variable into a single qualitative
description and allows us to make hypotheses about temporal patterns or
sequences of values we expect to observe. Fig. 12 shows one example of temporal
aggregation.
|
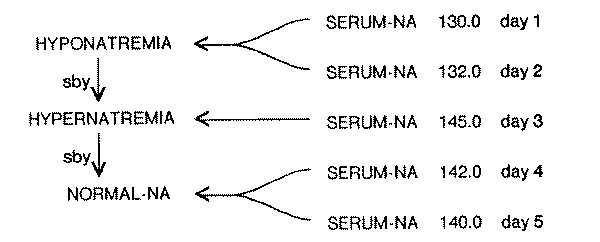
Fig. 12. Temporal aggregation permits the interpretation of a sequence of
values as a more compact sequence of aggregate nodes. (SBY means "succeeded
by.")
|
Component-Summation. Component-summation becomes necessary in our
program because the causal links in the system contain specific quantitative
information on how the various aspects of cause and effect instances (in a given
patient) relate to one another. The matching of cause-effect relations can be
unsuccessful if the program is misled into trying to account for some
jointly-caused effect in terms of an individual cause. In order to prevent this
from happening we must instantiate the effect of each cause individually and
then combine them. Different aspects of the components of a compound node may
combine additively (if they reinforce each other) or one may offset the other. A
component-summation may also be used to compute the magnitude of some aspect of
a contributing component from the knowledge of its compound node and its other components.
The description in Fig. 13 is a superimposition of two relations:
METABOLIC-ACIDOSIS-1 caused by DIARRHEA-1 and METABOLIC-ACIDOSIS-1 caused by
SHOCK-1. The description does not explicitly state that the metabolic-acidosis
(in the patient-specific model) is partly caused by diarrhea and partly by shock.
Therefore while considering the first relation, the program will assume that the entire
metabolic acidosis is being caused by diarrhea. This will result in the
cause-effect relation being mismatched (because the severity of acidosis and
anion-gap associated with it are larger than can possibly be attributed to
diarrhea). A similar mismatch would also occur while considering the relation between the shock and the
metabolic-acidosis. To avoid this problem, consider the description of the
example as shown in Fig. 14.

Fig. 13. Both diarrhea and shock if present in a patient are causes of
metabolic-acidosis.
|
|
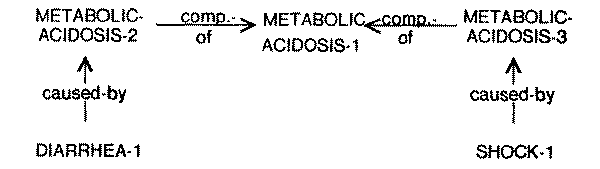
Fig. 14. To permit accurate quantitative reasoning, the components of
metabolic-acidosis due to each of its independent causes are separately
instantiated and explicitly combined.
|
The state description of Fig. 13 can be considered as an abstraction of
Fig. 14, where METABOLIC-ACIDOSIS-2 and METABOLIC - ACIDOSIS-3 are respectively the
components of METABOLIC-ACIDOSIS-1 caused by DIARRHEA-1 and SHOCK-1 The
decomposition of an effect with multiple causes into its causal components
provides us with valuable information in evaluating prognosis and in formulating
therapeutic interventions.
Taking another example, metabolic-acidosis could be considered to be
hypobicarbonatemia causing a reduction in pH, which causes hyperventilation and
reduced PCO2 which in turn causes an increase in pH; this is an example of
negative feedback. The increase is less than the initial reduction, causing a net reduction in
pH. (Fig. 15.)
|
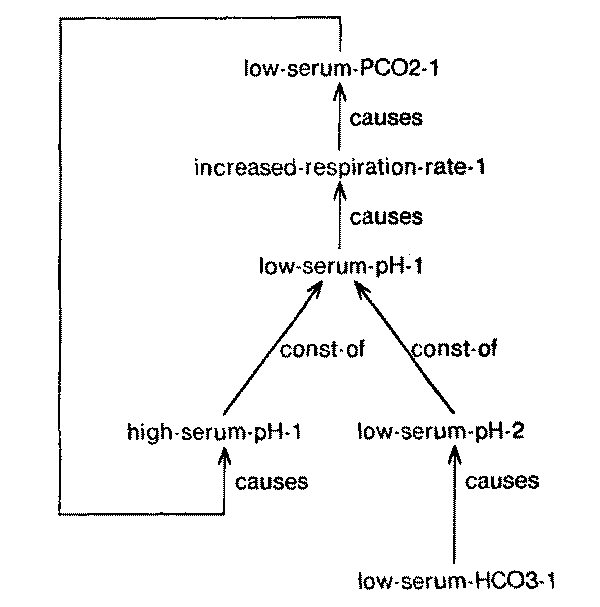
Fig. 15. Feedback loops can also be represented by using component-summation
to add the effects of an initial disturbance and the effects of the homeostatic
mechanism.
|
The component-summation mechanism allows us to separate the primary component
of die change from the secondary feedback components in feedback loops and allows us to fold causal chains in feedback loops that represent continuous
processes. However, decomposition of a node into its contributing factors raises
a new problem, that of how to combine the factors. The combined effect of two
components may not be additive and may depend on their causes and on the
particular physiological mechanisms involved. This problem needs further in-depth study, but here we
assume that there is some local mechanism that allows us to combine the
contributing factors satisfactorily.
Node Aggregation. Some of die possible groups of nodes are conceptualized and have objects. In
some sense, these concepts provide names describing them as conceptual 0
structures for organizing different situations that are commonly encountered
during diagnosis (recall the SIADH example, above). Because of historic evolution in
the recognition of medical situations and their nonstandard use, terms such as
disease, syndrome, physiological states, etc., have overlapping definitions. But
the existence of these different terms signifies the existence of different
types of clusters. We will try to identify the basic structure of these clusters
without differentiating between the specific mechanisms responsible for their
differences, mostly because we do not have sufficient knowledge in the
problem-solving domain to exploit the subtle differences between them. An
example of causal aggregation is shown in Figs. 13 and 14.
Link Aggregation. Links are used to represent causal relations between nodes.
The causal relations are understood and can be described at different degrees of
specificity and detail. This has been illustrated in Example 2, above. The
link-aggregation hierarchy represents an alternate hierarchy to the
node-aggregation hierarchy. It thus provides us with a different viewpoint in
summarizing the patient-description by allowing us to identify and eliminate
intermediate nodes from causal chains of reasoning. The link aggregation
hierarchy also helps us to evaluate the belief in a given causal fink at a
higher level of aggregation.
Representation of Uncertainty
In the previous section we have discussed the representation for describing
an illness using the assumption that the true state of the patient's illness is
known. But in reality the program's knowledge about the patient is uncertain
because its knowledge is incomplete and because of the chance nature of disease.
Its incompleteness gives rise to more than one possible (hypothesized)
diagnosis. Its chance component leads to hypotheses with less than unity
likelihoods. In this section we study the two major ways in which this
uncertainty appears and extend the patient-description using the concept of
hypothesized description to account for the possibility of more than one
hypothesized diagnosis.
As we have described above, uncertainty in the patient-description appears in
two related but distinct ways. First, because of incompleteness in our knowledge
about the true patient-description (ignorance) and second, because of the
inherent chance nature of the disease process. To illustrate the differences
between the two, let us consider a patient with severe diarrhea and vomiting.
This history indicates that the patient almost certainly has some metabolic
disturbance, but does not allow us to specify the type of disturbance (which
depends upon the relative amounts of alkaline fluid lost due to diarrhea and
acidic fluid lost from vomiting). This situation can be represented by
specifying a high level of belief for metabolic disturbance and not specifying
any belief value for metabolic-acidosis or metabolic-alkalosis. Such a situation
prevents the program from drawing any inference about die relative likelihoods
of metabolicacidosis and alkalosis from the given information, but permits it to
conclude that some metabolic disturbance is present. In general, the existence
of a hierarchy of disorders, ranging from very specific states near die bottom
to quite general classes of disturbances at the top allows the selection of some
particular level in the hierarchy to express the program's proper degree of ignorance. Hypotheses formed near
the "bottom" imply a high degree of precision of knowledge, while
those at the other extreme imply very little information.
The problem of evaluating the measure of belief in a given hypothesis is a
difficult one. Various researchers have worked on this problem [4, 22, 23, 26,
28], but no good practical solution to our problem has been found because the
simplifying assumptions often made in using probability theory (e.g., those of
completeness of the universe of discourse and conditional independence of
events) are not valid here. In addition the issues of incompleteness and
uncertainty of information have often been confused. We wish to separate these
two issues in order to exploit the capabilities of Al techniques, which are much
better at handling incomplete information (by hierarchic description) than
dealing with uncertainty. This would allow us to reduce our dependence on the
less than adequate schemes available for dealing with uncertainty.
Coherent Hypothesis
At any point in the diagnostic process the program has a partial
understanding of the illness of the patient. Uncertainties in that understanding
often lead to the program's having several different PSM's, each of which is a
consistent account of the observed data. Although each PSM therefore serves as a
complete account for everything that is known about the patient, none of them
may be an adequate diagnosis. For an hypothesis to count as a diagnostic
conclusion, it must not only explain all the known data, but it must also be
sufficiently complete that it explains what has caused the patient's current
problems and what additional complications are to be expected. It must also be
specific enough to differentiate between the actual disease and other similar
diseases.
A PSM may fail to be a diagnostic conclusion for several reasons. It may lack
any etiologic explanation of the fragmentary state of the patient it describes
because no data are yet known about the illness' ultimate causes. The PSM may
also lack any predictions concerning expected effects of the current situation,
again because no data concerning these effects are yet known and die PSM simply
accounts for known data-it does not "speculate." Finally, the PSM may
be inadequate as a diagnostic conclusion because it is too non-specific. In the
face of very little information, for example, some very general hypothesis such
as "congenital heart disease" may be the most specific one
justifiable, although additional information would help identify some specific
disease that the patient actually suffers from.
We introduce the notion of a coherent hypothesis (CH), which is an extension
of the PSM to include guesses about the etiologic derivation of the problem
represented by the PSM and about ultimate consequences expected from what is
known. Typically, several CH's may be formed from a single PSM, because the
known facts are insufficient to determine uniquely the way they came about or
their consequences. Each CH provides an alternate explanation for the disease
process in the patient and only one of these CH's can be correct. Thus, we have a set of alternate
hypotheses which are mutually exclusive and competing; therefore, they can be
rank-ordered according to their likelihood.
Alternative explanations for a patient's state may be represented by both the
presence of multiple PSM's and the existence of multiple CH's per PSM. Multiple
PSM's correspond to different interpretations of already known facts, and
multiple CH's associated with a single PSM correspond to different possible
complete pictures of the patient's illness that all fit with the given
interpretation of the facts known so far. During the diagnostic process, as more
facts become known, we expect that both the number of CH's associated with any
PSM and the number of PSM's being entertained will decrease as knowledge of the
actual state of the patient constrains plausible explanations of the facts.
At any point during the diagnostic process there are only a few distinct
explanations for the patient's illness, although each such explanation can have
a substantial number of variations. The number of alternatives to consider can
be limited by selecting an appropriate level of detail for representing the
patient-description. This allows us to represent small differences in the
hypotheses implicitly (by professing ignorance about them) while focusing on the
major differences. Again, during problem-solving we need to compare the
different alternatives (coherent hypotheses) to identify the differences between
them. If each CH is represented separately, this task can become substantial.
This problem can be overcome by allowing different hypotheses to share common
sub-hypothesis structures, thus producing a single structure to represent the
set of alternate CH's in which the important differences move up the structure,
while the smaller differences tend to be buried deep inside the structure.
Description-Building Operations
In the preceding section we have studied the structural organization of the
patient-specific model. Our goal has been to separate the data structures
required for the representation of a patient's description from those required
for efficient problem-solving. This allows us to represent the
patient-description, incorporating all available findings and derived facts
about the patient, independently of the program's problem-solving strategies and
behavior. The separation improves the program's semantic clarity, coherence,
completeness and explainability.
In this section we turn to considering the operations that instantiate the
program's general medical knowledge to create descriptive structures pertinent
to an individual patient. It is worthwhile noting that the program must
distinguish between its general medical knowledge, which is potentially
applicable to all patients, and an individual PSM, which describes the program's
understanding of a particular patient's case. Any PSM must be constructed from
the program's general knowledge and must be consistent with it, for what is
known about an individual should not contradict what is known generally. The
PSM, however, usually embodies much more specific knowledge about the individual
patient than what one would know from a general knowledge of medicine; for
example, if a disorder is generally known to have three possible causes, the PSM may in fact identify just one of those as the likely
cause in the case under consideration.
The operations for constructing the PSM from the Program's general knowledge
and from specific data about the patient are: initial formulation to create an
initial patient-description from the presenting complaints, initial findings and
lab-results; aggregation to combine various findings into causal clusters
representing different disease hypotheses (moving up); disaggregation to
decompose aggregate findings and hypotheses into their components or specific
subclasses (moving down); and projection to hypothesize associated findings and
diseases suggested by nodes in the patient-description at the same level of
abstraction (moving sideways).
Initial Formulation
Observations on the response of physicians to the "presenting clinical
picture" of a new patient (the initial set of complaints and data) suggest
that physicians establish a tentative diagnostic conclusion very early in their
thinking about a case. This cognitive strategy has the significant benefit that
it enables the physician to organize successive elements of his or her
diagnostic behavior (such as what questions to ask, tests to order, observations
to make) around the tentative conclusion. This viewpoint provided the
organizational framework of the Present Illness Program [15], in which such a
tentative diagnosis was established by the triggering of hypotheses strongly
suggested by the chief complaint and other important data. Although the
triggering scheme was successful in raising the possibility of disorders that
should be considered, it was not sufficiently selective [251, and could often
trigger as many as half the program's known set of disorders as possibilities.
In the domain of electrolyte and acid-base disorders, the problem of
formulating an initial description of the patient from data typically available
to the program appears simpler than in the broader diagnostic domain of Pip.
ABEL uses any given initial findings and a set of serum electrolyte and
acid-base values to construct a small number of PSM's as its initial possible
diagnoses, as follows. First it identifies all possible single or multiple
acid-base disturbances consistent with the given electrolyte values and then
retains only those also consistent with the known initial findings. Next the
program generates a possible pathophysiological explanation of the known data
based on each of the proposed acid-base disturbances. This is accomplished by
using the disaggregation and projection operations (described below) to relate
the known clinical information to the known laboratory data. Finally any newly
-discovered relationships at the lowest levels of detail are aggregated through
intermediate levels to provide their summary at the clinical level. After this
process, each PSM contains a plausible formulation of the patient's condition at
every level of detail that is of interest to the program. It is these
descriptions that are later modified by the diagnostic process as more
information becomes available.
Initial formulation of the diagnostic problem could, we believe, be
successfully accomplished by a combination of the triggering ideas of Pip with
the operators used here to insure consistency across various levels of detail in a causally
coherent account of the case. However, the ability to compute the possible sets of acid-base
disturbances from a given set of electrolyte values is an especially powerful
feature of the domain of study Of ABEL and permits us to avoid some of the
issues of initial problem-formulation that would be significant in other domains.
We thus follow the dictates of the "knowledge-based systems" approach
in Al research to exploit whatever powerful organizing principles or facts of
the domain are available. After all, physicians working in the domain also know
and rely on these facts to simplify their initial approach to electrolyte and
acid-base disorders.
Projection
Within any level of detail of the PSM, we require an operator that explores
the diagnostic space. Projection broadens the
cross-section of the model at any given level of abstraction. The basic process of projection can be described as
follows. Suppose we are considering some hypothesis H. If H is present then some
of its antecedents (causes) or consequents (effects) must be present. Therefore,
if hypothesis H is assumed, it is reasonable to assume that at least one of its
antecedents and many of its consequents will also be present in the patient. The
process of projection allows us to suggest new hypotheses about the causes and
the consequences of a given node at the same level of abstraction. These new
hypotheses can then be used to group different nodes into causally
antecedent-consequent pairs, allowing abstraction or disaggregation. Projection
is the most powerful operator for suggesting new diagnostic hypotheses within a
PSM, because it considers extending the set of already-known nodes to those
causally related to them if the new nodes are not inconsistent with what is
already known about the patient.
Aggregation
The aggregation operation is used to combine causally related nodes into
clusters represented by nodes at a higher level of abstraction. When a set of
new findings is entered in the program, they are grouped into causally related
clusters about which the program is fairly certain. The program then tries to
group these clusters in alternate ways that are consistent with the program's
general medical knowledge. If the number of alternate groupings is small
(possibly two or three) the program builds alternate structures describing these
possibilities. If the number of possibilities is large, the program tries to
abstract already formed clusters into semantically larger concepts and tries
again. This process is continued until it reaches a level of abstraction where
most of the objects are connected to one another or when most of the objects are
etiologies or diseases, at which point structural abstraction is no longer
useful. Each abstraction generated by this process provides us with a coherent
partial diagnosis for the patient, and therefore with a new PSM. Within each
PSM, all the diseases, findings, etc., are mutually complementary, while the
alternate PSM's provide us with competing diagnoses. In die initial version of
ABEL, the program's general knowledge permits only a single grouping of
aggregations for any cluster of more detailed nodes: thus, aggregation is used only to summarize detailed information and cannot
currently lead to new hypotheses.
Disaggregation
The process of abstraction by aggregation in the system is complemented by
the Process of disaggregation. When the program is provided with information
about some disease or when it generates some hypothesis at a high level of
abstraction, it must assimilate this information into the patient-description.
This can only be done if sufficient structure exists at lower levels of the
hierarchy to support this hypothesis structurally. If not, the supporting
structure must be constructed by decomposing this hypothesis into a more
detailed presentation. Here again, we are faced with the situation that there
may be many possible disaggregations (presentations) for the same abstract
condition. But as this hypothesis must be consistent with already known facts
about the patient, parts of the disaggregation will already be present in the
patient model and the rest of the disaggregation must be consistent with the
model. This reduces the number of possible disaggregations greatly. Even so, the
lack of information at lower levels of detail can cause a potentially large
number of alternate disaggregations to be possible and thus prevent the program
from disaggregating any abstract hypothesis to the lowest level of detail
without further discriminating information. Disaggregation proceeds as far as
possible without making unsupported assumptions about the lower levels of the
PSM.
The mechanisms for creating and manipulating the PSM are described in much
more detail and illustrated in a recent paper [13].
Diagnostic Problem-Formulation and Information Gathering
Diagnostic Problem-solving is the acquisition of new information needed to
resolve uncertainties in the program's knowledge and the revision of its PSM's
to incorporate new findings. The previous section has introduced the set of
operators used to manipulate and fie together the different levels of
description in the PSM. Here we address die question of the program's method for
problem-formulation and information-gathering.
The patient-description assimilates all available information. For a specific
diagnostic subproblem, however, a large portion of this information may not be
directly relevant. The program must select some subset of its possible
interpretations of the facts about a patient, determine what observations would
be relevant to reducing its uncertainty about how to interpret those facts, and
then take some action to acquire new information relevant to that set. A
diagnostic problem-statement should focus on that part of the
patient-description where the program's understanding is most uncertain. It
should describe alternatives (which can be differentiated), and it should be
easily decomposable into smaller subproblems. In this section we discuss die
process of identification and formulation of the diagnostic problem, its
representation and decomposition into subproblems, the problem-solving strategies, and the use
of expectations in identifying discrepant information and in directing the flow
of control.
Problem Identification and Formulation
Solving the diagnostic problem involves selecting one interpretation of the
information about a patient and assuring that it is sufficiently complete that a
diagnostic conclusion and therapeutic and prognostic decisions can be safely
based on it. At any point during the process of diagnosis the program has a set
of coherent hypotheses (CH's) vying to explain the patient's illness. (Recall
that a CH is an extension of a PSM with possible etiologies and ultimate
consequences of what is already known.) The specific places where critical
information is lacking can be found by identifying points at which, on the basis
of the same set of facts, two or more hypotheses seem reasonable. All the
diagnostic subproblems identified in this manner are collected into a list
called the problem-set.
Every subproblem in this set needs to be solved in order to differentiate
between the competing hypotheses. It is here that the information gathering
process plays its role of finding critically needed information. The
availability of a set of problems to work on simultaneously provides die
problem-solver with the ability to minimize the total effort needed in solving
all the problems by abstracting common aspects of problems and by selecting an
efficient order in which the problems are to be solved. This can be done using
either a rank-ordering heuristic or a problem-abstraction heuristic.
- Rank-Ordering Heuristic: This represents a crude but effective first-cut
heuristic. Here the problem-set is rank ordered according to some criterion such
as the urgency of resolving a particular diagnostic problem, or the therapeutic
importance and global usefulness of the problem in understanding the patient's
illness. The problem having the maximum score is then selected as the focus for
information gathering.
- Problem-Abstraction Heuristic: Quite often, many of the problems in the
problem-set share some common feature, such as the duration and severity of the
illness, the specific organ system or the disease mechanism involved. In such
cases it is useful for die problem-solver to abstract die common aspect of the
problems or to partition the problem-set into different classes and then
differentiate between them, thus attacking a group of alternatives
simultaneously. In short, the problem-abstraction heuristic either reformulates
some subset of die problem-set into a single more abstract problem or selects
one of the problems from the problem-set as representative.
From the revised problem-set left after the application of the above
heuristics, one problem is selected to be investigated, as described next.
Problem-Description and Goal Structure
Once the problem is formulated, its resolution becomes the top-level goal for
diagnostic information-gathering. A diagnostic goal consists of the following
components; a) a primary goal which describes the main problem to be solved by
the problem-solver, b) a context which describes the reason for solving the
problem and c) an expectation which describes the program's prior expectation
about the outcome of the problem-solving activity given the knowledge already
available to it. The expectations are used to determine whether newly offered
information is consistent with the known patient-descriptions. Inconsistencies
are used to modify the flow of control in the information gathering program, as
described in the section on control flow below. An example of a goal statement
is given in Fig. 18.
Once the top level diagnostic goal is identified, the problem-solver sets up
a goal structure (a plan for problem-solving) by decomposing this goal into its
subgoals (and those, in turn, into their subgoals, in the typical manner of
recursive programs) until it reaches subgoals that can be solved using
primitives known to the system. The subgoal generation is accomplished using
disaggregation and projection operations in the context of the
patient-description. Each subgoal is associated with some part of the
patient-description relevant to the the problem being decomposed. Therefore, we
can view the goal structure as a representation of problem-specific information
extracted from the patient-description. This interaction between the goal
structure and the PSM allows us to assimilate the information gathered during
problem-solving into the patient-description efficiently, because the
interpretation and context in which the information is relevant to the patient
model is known a priori. It also allows us to associate expectations with goal
statements and thus to check the incoming information against the
patient-description for apparent and real contradictions.
Problem-solving Strategies
The choice of particular problem-solving strategies is an issue somewhat
independent of the representations used to describe what the program knows about
a patient's case. Even the above-described structure of problem- formulation
allows a variety of methods to be brought to bear on actually solving any one
problem (eliminating all but one alternative).
For a long time one type of strategy has dominated the thinking of the
medical profession-the differential diagnosis. The codification of this approach
in a book such as French's Index of Differential Diagnosis is an example of the
systematic organization of such diagnostic procedures. On the other hand, most
computer programs using the hypothesize and test paradigm for diagnosis have
emphasized the confirmation strategy, in which each hypothesis is considered in
turn and some attempt is made to confirm it. Although confirmation is an
important strategy in itself, its effectiveness is limited to situations where
only one hypothesis is being considered or one hypothesis dominates the
competing hypotheses. In ABEL we extend the strategies identified by Miller [10]
using our experience with INTERNIST [17, 18, 19] and PIP [15, 16, 25] and adapt
them for use in conjunction with the patient-description developed in previous
sections.
These strategies can be broadly classified as follows: Confirm, Rule-Out,
Differentiate, Group-and-Differentiate, Refine and Explore. Selection of an
appropriate strategy is based upon the syntactic structure of the diagnostic
problem (e.g., the number of alternate hypotheses being considered and their
belief measures relative to one another), as described below. As pointed out above, the
confirmation
strategy is used when we have only one hypothesis under consideration, or when among a group
of hypotheses, one hypothesis is much more likely than all other alternatives
under consideration. The rule-out strategy is meant to eliminate some
hypothesis, when one is substantially less likely than the others.
Differentiation is used to discriminate between two hypotheses with similar
belief factors. The group-and-differentiate strategy is used when a large number
of alternate hypotheses are held with similar degrees of belief. Here we need to
discard many hypotheses rapidly in order to focus our attention on a small
number of alternatives. This is done by partitioning the alternatives into a few
groups according to some common characterization and then applying a differentiation strategy to rule-out (or confirm) one of the groups, thus
narrowing the hypothesis set. The refinement strategy is used to split a
hypothesis about a general class of diseases into more specific hypotheses. Note
that the refinement of a hypothesis into more specific hypotheses generally
results in a disjunctive set of hypotheses. Therefore, the refinement strategy
is generally followed by differentiation. Finally, the explore strategy is used when the patient-description does not
have any well-defined diagnostic problems to solve. In such a situation we
explore the findings systematically, to gather sufficient relevant evidence to
formulate a specific diagnostic goal.
An Example
Let us consider a patient who has been ill for 3 to 4 days and is known to
have moderately severe metabolic-acidosis and slight hyponatremia (serum Na of
128 meq/L). Let us also assume that no additional history is available. Two
possible formulations of the patient's problem are shown in Figs. 16 and
17.
|
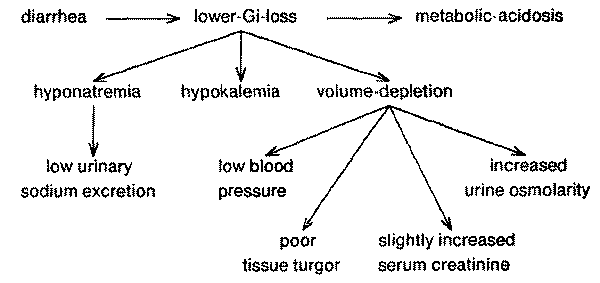
Fig. 16. In one explanation of the example case, diarrhea is lower
gastro-intestinal losses, which result in metabolic-acidosis, volume depletion,
and their consequences.
|
|
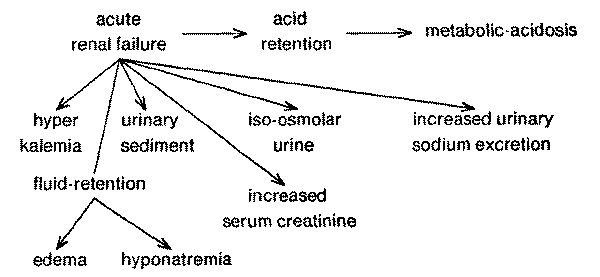
Fig. 17. An alternative explanation to that of Fig. 16 holds acute renal
failure responsible lbr acid retention, which causes metabolic-acidosis and its
consequences.
|
One
hypothesis states that the underlying disorder is diarrhea, the other, that it
is acute renal failure. The program has set as its top level goal, as shown in
Fig. 18, the desire to discriminate between these two possible interpretations.
Goal 1: Differentiate diarrhea, acute renal failure
Context: Cause-of metabolic acidosis
Expectations:
Possible: diarrhea
Severity: moderate
Possible: acute renal failure
Severity: moderate
Duration: a few days
Subgoals: (AND 2 3 8 9 10)
Fig. 18. Top-level goal structure for discriminating between diarrhea and
acute renal failure.
|
|
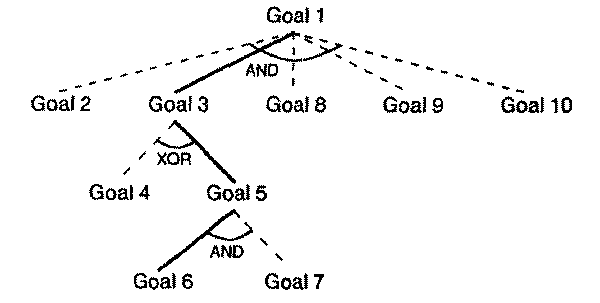
Fig. 19. The complete goal structure. AND indicates goals that must be
simultaneously achieved and XOR indicates goals of which only one can be
achieved. The solid arcs in the goal structure represent the path actually being
taken by the information-gatherer.
|
To accomplish this objective the program compares the two interpretations,
identifying the differences between the states predicted by the two
interpretations, and formulates a set of sub-goals to pursue each difference. For example, the program identifies urinary sodium concentration
as a useful differentiator between diarrhea and acute renal failure, because
diarrhea predicts that the urinary sodium concentration will be low whereas
renal failure predicts a relatively high urinary sodium concentration.
Similarly, the program can differentiate between diarrhea and acute renal
failure by determining the state of hydration of the patient; this goal can be
achieved by confirming either volume depletion or edema. Diarrhea predicts the loss of fluid and therefore volume depletion. Volume
depletion, however, can not be directly observed: therefore, the program further
decomposes the goal for confirming volume depletion into sub-goals for confirming poor
tissue turgor and low blood pressure. Acute renal failure, on the other hand,
predicts accumulation of body fluids if normal intake of fluid has continued
during the period of oliguria. If a sufficient accumulation occurs, it will
manifest itself as edema. A graphic representation of the complete goal structure is shown in
Fig.19, and the goals
are listed below:
Goal 2: explore urinary sodium concentration
Context: differentiate diarrhea, acute renal failure
Expectations:
Possible: low (loss than 10 meq/l)
Cause: diarrhea
Possible: high (greater than 40 meq/l)
Cause: acute renal failure
Goal 3: explore state of hydration
Context: differentiate diarrhea, acute renal failure Expectations:
Possible: volume depletion
Cause: diarrhea
Severity: moderate
Possible: fluid retention
Cause: acute renal failure
Default: continued normal fluid intake
Severity: mild to moderate
Subgoals: (xor 4 6)
Goal 4: confirm fluid retention
Context: caused by acute renal failure
Expectations:
Possible: edema
Severity: mild to moderate
Possible: no edema
Goal 5: confirm volume depletion
Context: caused by diarrhea
Expectations:
Possible: present
Severity: mild to moderate
Possible: absent
Subgoals: (AND 6 7)
Goal 6: confirm poor tissue turgor
Context: explore state of hydration
Expectations:
Possible: mild
Cause: volume depletion
Possible: absent
Cause: fluid retention
Goal 7: explore blood pressure
Context: explore state of hydration
Expectations:
Possible: slightly low
Cause: volume depletion
Possible: normal
Cause: fluid retention
Goal 8: confirm hemoglobin and tubular cell casts in urine
Context: differentiate diarrhea, acute renal failure
Expectations:
Possible: present
Cause: acute renal failure
Possible: absent
Cause: diarrhea
Goal 9: explore serum creatinine
Context: differentiate diarrhea, acute renal failure
Expectations:
Possible: slightly to moderately elevated
Cause: acute renal failure
Possible: slightly elevated
Cause: diarrhea
Goal 10: explore serum K
Context: differentiate diarrhea, acute renal failure
Expectations:
Possible: increased
Cause: acute renal failure
Possible: low
Cause: diarrhea
The program has now completed planning its information-gathering strategy for
differentiating between diarrhea and acute renal failure. The following is a
summary of the information gathered by the program in pursuing this goal
structure.
Urinary sodium concentration: 50 meq/l
Edema: absent
Tissue turgor: slightly reduced
Blood pressure: normal
Urine sediment: negative
Serum Creatinine concentration: 2.5 mg per cent
Serum K concentration: 3.5 meq/l
After successfully achieving each of the sub-goals the program evaluates the
top-level goal of differentiating between diarrhea and acute renal failure.
During this evaluation the program realizes that the overall set of findings are
not consistent with one another. In particular, the finding of high urinary
sodium concentration suggests acute renal failure, whereas the low serum K
concentration is inconsistent with acute renal failure. On the other hand, low
serum K concentration is consistent with diarrhea, whereas high urinary sodium
concentration is not. This conflict activates the program's excuse mechanism
(see below). To resolve the contradiction, the program sets up two goals so that
one of the two diagnoses can be confirmed. The two goals are:
Goal 11: Find excuse for high urinary sodium concentration
context: diarrhea
expectation:
possible: diuretic use
possible: Addison's disease
Goal 12: Find excuse for low serum k
context: acute renal failure
expectation:
possible: diuretic use
possible: vomiting
Upon pursuing these goals the program finds that the patient has been
vomiting, which explains the slightly low serum K concentration and a slight
volume depletion. The high urinary sodium excretion argues strongly in favor of
acute renal failure.
After completing a cycle of information gathering the program enters this
information into the patient-specific models and revises its CH's for the
patient and continues the diagnosis.
Control Flow
We have noted that at the time some information is requested, the information
gatherer has a hierarchy of goals or a goal stack representing the downward
locus of control flow. We have also noted that each subgoal in the goal stack is
associated with expectations. The expectations associated with a goal can be
viewed as a set of conditions (a predicate) which must be satisfied if the goal
is to be attained. 'Me assessment of how well the goal has been achieved is
evaluated in terms of one of four values; (i) Success, (ii) Partial Success,
(iii) Failure or (iv) Contradiction.
After every question the expectation of the immediate goal is evaluated. If
the result is a success, then control is returned to the superior of the
immediate goal, with an indication of success. The evaluation results in partial
success if the information gathered is not certain enough to satisfy the expectations
but can be interpreted in a way that lends support to the immediate goal. On the
other hand if the evaluation results in a failure, the problem-solver tries to
look for an excuse that can cause the particular goal to be negated without
contradiction. This mechanism allows us to distinguish apparent contradiction
from real contradiction, providing for a robust process of information
acquisition. More importantly, it prevents apparently contradictory information
from corrupting the patient-description and thereby compromising the evaluation
of hypotheses.
For example, let us consider a patient suffering from the syndrome of
inappropriate secretion of antidiuretic hormone (SIADH) who is on a
salt-restricted diet due to premenstrual edema of her ankles. Now let us look at
the program at a point where SIADH is its leading hypothesis, it has requested
information about the urine electrolyte values and is told that the sodium
content of the urine is 5 meq/l. Let us also assume that the program is not
aware of the salt-restricted diet. If the program now evaluates the SIADH
hypothesis, the absence of excessive salt loss in the urine would weigh strongly
against the hypothesis and may cause it to drop to a lower rank in the list of
hypotheses.(6) Because SIADH is no longer the program's leading hypothesis, the
next question, about a salt restricted diet, which could explain the negative
finding, will not be asked. To avoid such situations, the program should delay
the scoring of the current hypothesis whenever an unexpected finding is
encountered and should explore the finding in greater detail. If an excuse is
found, the current goal may result in success or partial success and the program
may continue pursuing its goal. However if no excuse is found the pursuit of
this goal fails. If the discrepancy is serious, then a mechanism for dealing
with contradictions is invoked. In other cases of failure, the expectations of
the immediate superior goal are evaluated to determine if the superior goal is
still viable or not, and the above-described process is repeated.
If a major discrepancy is found, there is some serious error in the program's
patient-description or problem -formulation. This situation is handled with the
help of a special contradiction-handler, consisting of two components: a goal
structure contradiction-handler and a PSM debugger. The contradiction-handler
identifies the scope of the discrepancy. If the contradiction is local to some
goal in the problem, the program identifies that goal at which the contradiction
does not affect the formulation of superior goals. It then reformulates the
problem from there on and continues with information gathering. If on the other
hand the contradiction is found in the patient-description, the program must
modify the patient-description in light of the new finding and start a new
problem-solving cycle. If no reformulation of goals and no revision of the PSM's
can resolve the contradiction (a rare event, we presume), then either the
recently-introduced fact or some previously-reported fact that it contradicts
must be retracted by the user.
The process of back-tracking is computationally expensive. Therefore,
commonly occurring contradictions and heuristics for dealing with them Should be
pre-compiled in the knowledge-base of the program. Availability of this information will
allow the program to resolve commonly occurring contradictory situations
efficiently without resorting to explicit back-tracking. The new information
gathered during problem solving must continually be added to the patient-description. This process is
considerably simplified when the incoming information is consistent with the
patient profile and its context is well defined. The use of the goal structure
provides a strong focus to the question-asking behavior of the program and
provides us with a mechanism to shift from "global" to
"local" problem-solving (a shift observed in the behavior of
clinicians [21, 10, 81). It also makes explicit the reason for question-asking,
and the context in which die question is asked, allowing us to explain why a
particular question is asked and the effects of various answers to die question.
Conclusion
in the above sections we have outlined what we believe are a set of needed
representations and program mechanisms to enable a "second generation" of AIM
programs to improve significantly on the competence of existing programs. We
have defined the structure of the ABEL consulting program for acid-base and
electrolyte disorders, have introduced the representation with which it builds
its understanding of a patient's illness, and have given a sketch of how it can
use those structures to plan and carry out its diagnostic reasoning. We have
also set forth the arguments that led us to choose this medical domain for our
work and summarized a set of desiderata for our program (and others in AIM) to
fulfill.
Perhaps the most striking observation as we look back on the years we have
already spent developing ABEL is the great complexity of its design and
implementation as compared with earlier programs we have developed and examined.
To capture the variety and depth of knowledge of expert clinicians requires a
major investment. Studies must be made of how physicians reason, and a large
body of factual information relating to the specific medical domain must also be
gathered. Finally, a set of computational structures must be created to express
the accumulated knowledge and to simulate the reasoning strategies. Thus,
judging from our experience and that reported by Pople in Chapter 5 of this
volume, the size and sophistication of the newer AIM programs will considerably
exceed that of the previous generation.
The patient-description component of ABEL has been completely implemented. We
are able to perform the initial formulation of the PSM given the basic facts of
a case. The description building operators that create and maintain the PSM
(aggregation, disaggregation and projection) all function, and we do now have
the multi-level causal model of the patient available as the underlying data
structure for the program's knowledge. In addition, we have coupled the
techniques of English generation described above to the PSM and can now produce
reasonably good English explanations of die program's understanding of a case.
Figure 20 shows the program's account of the example case used earlier at the
final stage where all outstanding questions have been resolved. Compare the
concise explanation generated in terms of the clinical, phenomenological level
of reasoning in the first part of the figure with the greater level of detail in
the second part.
|
Clinical Level Explanation
This is a 40 year old 70.0 kg male patient. His electrolytes are:
Na: 140.0 HC03: 15.0 Agap: 13.0
K: 3.0 pCO2: 30.0
Cl: 115.0 pH: 7.32
The patient has moderate metabolic acidosis and mild hypokalemia.
The metabolic acidosis causes mild acidemia. The acidemia partly
compensates the suspected moderate hypokalemia leading to the
observed hypokalemia. The metabolic acidosis remains to be
accounted for. The hypokalemia has only been partially accounted
for.
Intermediate Level Explanation
This is a 40 year old 70.0 kg male patient. His electrolytes
are: ...
The patient has moderate metabolic acidosis, mild hypokalemia and
moderate hypobicarbonatemia. The metabolic acidosis along with
moderate hypocapnia causes hypobicarbonatemia. The
hypobicarbonatemia along with hypocapnia causes mild acidemia.
The acidemia partly compensates the suspected moderate hypokalemia
leading to the observed hypokalemia. The metabolic acidosis
remains to be accounted for. The hypokalemia has only been
partially accounted for.
Fig. 20. English language descriptions of the patient-specific model
generated by ABEL at two of its five levels of detail for a patient with
diarrhea.
|
Thus far, the implemented diagnostic program is only a simplified
approximation to die design presented here. Computer memory limitations have
made it difficult to create all coherent hypothesis structures as envisioned in
the design, and efforts to combine them into more compact representations have
thus far restricted us to using only the explore, confirm and differentiate
strategies, and delayed the use of control strategies more complex than simple
backtracking. Solving these problems and completing the envisioned diagnosis
component is our current focus of effort. As mentioned earlier, the therapy
module is only partly designed and awaits further work on die diagnosis module.
How can we put our current status into perspective? We began with a
frustration shared by a number of our colleagues after we had built our first
programs for medical applications. Although our programs' performance in their
domains of expertise was often quite good, even by human standards, we were
concerned that we faced fundamental limitations. Our methodology suggests that
expert programs should be built to simulate human experts' understanding of and
reasoning about problems of the domain. Yet our initial programs clearly lacked
machinery to express much of what we knew that our model human experts knew and
used. Therefore we set out to envision and build representational structures and
reasoning mechanisms that more closely approximated our models. Although
completing this work and demonstrating the validity of our underlying
assumptions is an extended task whose end is not in sight, the ability Of ABEL
to capture and use the kind of rich description of the patient's state that we
have shown here is a very encouraging sign.
References
1. Bleich, H. L., "Computer-Based Consultation:
Electrolyte and Acid-Base Disorders," Amer. J. Med. 53,
(1972), 285.
2. Carlos, V, Pevny, E., and McMath, F., "Computer
Analysis of Blood Gases and Acid-Base States," Comp. Biomed. Res. 4,
(1971), 623-633.
3. Doyle, J., "A Truth Maintenance System," Artificial
Intelligence 12, (1979), 231-272.
4. Duda, R. O., Hart, P. E., and Nilsson, N. J.,
"Subjective Bayesean methods for rule-based inference systems," Proceedings
of the 1976 National Computer Conference, AMPS Press, (June 1976).
5. Elstein, A. S., Shulman, L. A., and Sprafka, S. A., Medical
Problem Solving. An Analysis of Clinical Reasoning, Harvard University
Press, Cambridge, Mass., (1978).
6. Goldberg, M., Green S., Moss, M. L., Marbach, C. B., and
Garfinkel, D., "Computer-based Instruction and Diagnosis of Acid-Base
Disorders," Jour. Amer. Med. Assn. 223, (3) (1973), 269-275.
7. Gorry, G. A., and Barnett, G. 0., "Sequential
Diagnosis by Computer," Jour. Amer. Med. Assn. 205, (12)
(1968), 141-146.
8. Kassirer, J. P., and Gorry, G. A., "Clinical Problem
Solving: A Behavioral Analysis," Ann. Int. Med. 89, (1978),
245.
9. Kuipers, B. J., Representing Knowledge of Large-Scale
Space, AI TR-418, MIT Artificial Intelligence Lab., Cambridge, Mass.,
(1978).
10. Miller, P. B., Strategy Selection in Medical Diagnosis;
Technical Report TR-153, Project MAC, Massachusetts Institute of Technology.
(September 1975).
11. Newell, A., and Simon, H. A., Human Problem Solving,
Prentice Hall, (1972).
12. Patil, R. S., Design of a Program for Expert Diagnosis
of Acid Base and Electrolyte Disturbances, TM-132, MIT Lab. for Comp. Sci.,
Cambridge, Mass., (May, 1979).
13. Patil, R. S., Szolovits, P. and Schwartz, W. B.,
"Causal Understanding of Patient Illness in Medical Diagnosis," Proc. Seventh
Intl. Joint Conf on Artificial Intelligence, Yale University, New Haven, CT,
(1981).
14. Patil, R. S., Causal Representation of Patient Illness
for Electrolyte and Acid-Base Diagnosis, Ph.D. thesis, Dept. of Electrical
Engineering and Computer Science, MIT Lab. for Comp. Sci., Cambridge, Mass.,
(Oct. 1981).
15. Pauker, S. G., Gorry, G. A., Kassirer, J. P., and
Schwartz, W. B., "Toward the Simulation of Clinical Cognition: Taking a
Present Illness by Computer," Amer. J. Med. 60, (June 1976),
981-995.
16. Pauker, S. G., and Szolovits. P.. "Analyzing and
Simulating Taking the History of the Present Illness: Context Formation,"
in Schneider/Sagvall Hein (Eds.), Computational Linguistics in Medicine,
North-Holland, (1977), 109-118.
17. Pople, H. E., Jr., "Artificial-Intelligence
Approaches to Computer-Based Medical Consultation," IEEE Intercon
Conference, (1975).
18. Pople, H. E.. Jr., Myers, J. D., and Miller, R. A.,
"The DIALOG Model of Diagnostic Logic and Its Use in Internal
Medicine," Advance Papers Fourth Intl Joint Conf. on Artificial
Intelligence, MIT Artificial Intelligence Lab., Cambridge, Mass., (1975).
19. Pople, H. E., Jr.. "The Formation of Composite
Hypotheses in Diagnostic Problem Solving: an Exercise in Synthetic
Reasoning," Proc. Fifth Intl. Joint Conf on Artificial Intelligence,
Carnegie-Mellon U., Pittsburgh, Pa., (1977).
20. Richards, B., and Goh, A. E. S., "Computer Assistance
in the Treatment of Patients with Acid-Base and Electrolyte Disturbances,"
in Shires/Wolf, (Eds.), MEDINFO 77, IFIP, NorthHolland Publ. Co., (1977).
21. Rubin, A. D., Hypothesis Formation and Evaluation in
Medical Diagnosis, S.M. thesis, Technical Report Al-TR-316, MIT Artificial
Intelligence Lab., Cambridge, Mass., (January 1975).
22. Shafer, G., A Mathematical Theory of Evidence,
Princeton University Press, (1976),
23. Shortliffe, E. H., and Buchanan, B. G., "A Model of
inexact reasoning in medicine," Mathematical Biosciences 23,
(1975), 351-379.
24. Swartout, W., Producing Explanations and Justifications
of Expert Consulting Programs, Ph.D. thesis, Dept. of Electrical Engineering
and Computer Science, TR-251, MIT Lab. for Comp. Sci., Cambridge, Ma., (January
1981).
25. Szolovits, P., and Pauker. S. G., "Research on a
Medical Consultation System for Taking the Present Illness," Proceedings
of the Third Illinois Conference on Medical Information Systems, University
of Illinois at Chicago Circle, (November 1976).
26. Szolovits. P., Pauker, S. G., "Categorical and
Probabilistic Reasoning in Medical Diagnosis," Artificial Intelligence
11, (1978), 115-144.
27. Wittgenstein, L., Philosophical Investigations,
MacMillan, New York. (1953).
28. Zadeh, L. A.. "Fuzzy sets," Information and
Control 8, (1965), 338-353.
Notes
(1) The research reported here has been supported in part by
the National Institutes of Health under Grant No. 1 P01 LM 03374 from the
National Library of Medicine and Grant No. 1 P41 RR 01096 front the Division of
Research Resources. Dr. Schwartz's research is also supported by the Robert wood
Johnson Foundation. Princeton, NJ The program described here is being
constructed as part of Mr. Ramesh Patil's doctoral research, with the guidance
and assistance of the other authors. Much of the chapter is drawn from Mr.
Patil's thesis proposal, which has appeared as a technical memo [12]. This
material is also discussed in much greater detail in that thesis [14].
(2) Some may object that the lack of general medical
knowledge that leads to a theory admitting chance could also be ameliorated, for
example by a research project elucidating the biochemical nature of the therapy
under consideration. For our purposes, when considering the diagnosis and
therapy of individual cases, this luxury is precluded and the distinction
between chance and lack of information remains useful.
(3) By instantiate we mean to create a concrete instance of
a general concept to represent that general concept in the particular hypothesis
at band.
(4) In computation, a default is a value one may assume in
the absence of evidence to the contrary. It is a common rule of thumb, for
example, that in hearing a description of a patient one may assume that those
aspects of the patient that are not specifically mentioned are normal. Reasoning
based on such default assumptions may have to be retracted if real evidence
contradicts the default assumptions. [3]
(5) The following abbreviations are used: CONST-OF (constituent of) and
COMP-OF
(component of).
(6) This reasoning is based on the program's assumption that the patient is on
a normal-salt diet, which is reasonable in the absence of knowledge to the
contrary. The program must make many such assumptions when working with partial
information.
This is part of a Web-based reconstruction of the book
originally published as
Szolovits, P. (Ed.). Artificial
Intelligence in Medicine. Westview Press, Boulder, Colorado. 1982.
The text was scanned, OCR'd, and re-set in HTML by Peter
Szolovits in 2000.