|
Figure 1: A P3P pseudonymous interaction with a service |
A Framework for Privacy Protection
Christian Baekkelund
David Kelman
Ann Lipton
Alexander Macgillivray
Piotr Mitros
Teresa Ou
December 10, 1998
Table of Contents
Executive Summary
Danger
Goals
Proposal
Introduction
Scope
Goals
Current and Proposed Regulatory Frameworks
Technology
Internet Protocol (IP)
IP Logging
The Future of IP Logging
IP Version 6
Anonymizing Routers
Anonymizing Proxies
Hypertext Transfer Protocol (HTTP)
Cookies
An Alternative to Cookies: Client-Side Targeting
Other Web Technologies
Lightweight Directory Access Protocol (LDAP) Databases
JavaScript and VBScript
Java and ActiveX
E-Commerce
Payment
Digital Cash Protocol Type 1
Digital Cash Protocol Type 2
Delivery
P.O. Boxes
Cryptographic Delivery
Trusted Third Party
Case Study: A Technological Solution
Platform for Privacy Preferences (P3P)
P3P Strengths
P3P Problems
Law
Constitutional Law and Common Law
Common Law
Tort Law
Contract Law
Federal Statutes and Common Law
Privacy Act of 1974
Privacy Protection Act (PPA) of 1980
Electronic Communications Privacy Act (ECPA) of 1986
Legislative Outlook
The European Data Directive
Markets and Social Norms
Case Study: A Norms Solution
TRUSTe Strengths
Problems
Proposal
Entitlement to Individuals
Three Exceptions:
Operational and Aggregated Data
Opt-In by Contract
Autonomous Computer Contracting Privacy Technology (ACCPT)
Critique
Technical and Legal Complexity Added by ACCPT
Technical Complexity for the Programmer
Technical Complexity for End-Users
Legal Complexity for Programmers
Legal Complexity for End-Users
Public Access
A Slower Internet
Limitations of ACCPT
International Conflict of Laws
Profiling
Operational Data
"Race to the Bottom"
Philosophical Criticisms of ACCPT
No Data Collection
Less Regulation
Conclusion
Appendix A: Table of Proposed Legislation
Appendix B: Example P3P protocol
The current direction of the information revolution threatens personal privacy. According to the Federal Trade Commission, 92% of websites collect personal information from their users. Add Internet Protocol (IP) address logging and that number nears 100%. However, industry self-regulation has been an unqualified disaster with very few sites providing notice of their data practices and default settings on devices which implicate personal privacy set at their most lenient. Users do not own their personal information and current informational practices point towards more abuse of personal information rather than less.
Most large websites handle advertising through one of several large brokers. To better target advertising, those brokers commonly track what websites a person visits, and what that person does on each site. For instance, the first time a user downloads an ad from DoubleClick (which handles ads for Altavista, Dilbert and many of other popular websites), DoubleClick sets a cookie on the user’s hard drive. This cookie is used to track the sites a user visits, keywords from Altavista searches and other information. If a user makes a purchase on a site subscribing to DoubleClick, DoubleClick can potentially match the user’s name to the cookie, and sell that profile to direct marketers. All of this typically happens without the user’s consent or even knowledge.
Advertising and information brokers are not the only abusers. Individual companies store data on their customers and are free to use that data how they see fit. Amazon.com, for example, keeps a record of all books individuals purchase. With modern data mining techniques, Amazon.com could collaborate with other companies to form a detailed profile of a person. As electronic commerce spreads, the amount of information in these profiles will become increasingly complete, and the business of buying and selling this information will become increasingly profitable. The more comprehensive these profiles become, the greater the potential for misuse of the information they contain.
In the face of these threats to privacy, the current legal framework offers insufficient protections to personal privacy, particularly against private entities. Our proposal attempts to create a legal and technological architecture that addresses this problem while satisfying the following goals:
Our proposal is limited in scope based on several assumptions. We do not consider governmental privacy violations; issues relating to children’s privacy; sniffing, snooping and other transmittal privacy violations. We do not expect to solve related problems dealt with by other subject matter white papers, such as international sovereignty issues, but do hope to identify how those problems affect our proposal. Furthermore, our proposal relies on a number of technological and legal structures. For example, we assume that certification and encryption can make users identifiable and contracts verifiable. These are further detailed in the text of our proposal.
Our proposal entitles individuals to ownership of personal information. We provide a legal and technological framework such that personal information cannot be used by any other entity without permission from the individual. We further propose that "default" settings on computer programs should not reveal personal information and that, for a user to enter into a contract where the user’s information is given to an entity, the user must be aware (either explicitly or through a transparent agent) of the terms of that contract and be able to enforce those terms.
We begin by envisioning a legal framework whereby the use of information, without permission, carries a statutorily determined minimum penalty. A user who feels his or her rights have been violated may sue the offending company. This might be administered through a government agency responsible for investigating the source of the privacy violation -- an individual, for example, might only know that he or she had received a solicitation without knowing which of the several companies with which he or she had interacted had released information. Alternatively, the user could initiate her own suit through a private right of action.
If a company wishes to use personal information about an individual, it is the company’s responsibility to enter into a contract with that individual by asking for permission to use the information and disclosing the intended purposes of the data collection. This can be done either by personal, "manual" interaction, or through the use of a computerized agent. In order for the contract formed by the computerized agent to be legally binding, there must be some evidence that the client was aware of, and authorized, choices made by its agent. If no such evidence exists, then the contract, or certain provisions therein, would not be enforceable and the company would be potentially liable for use of the personal information.
In order to remove some confusion about which autonomous agent contracts will be enforced, we propose the Autonomous Computer Contracting Privacy Technology (ACCPT) guidelines as a framework for enabling users to negotiate privacy preferences with websites. In a basic ACCPT transaction, the client and server negotiate to reach a mutually acceptable set of privacy practices. If no agreement is reached in an ACCPT transaction, the server can log a failed attempt and sample proposals, but no additional information about the transaction (the user’s IP address, etc.).
ACCPT incorporates the elements necessary to ensure that users are aware of the activity of the computerized agents. To the extent that negotiation is governed by a set of preferences entered by the user when the technology is first installed, the ACCPT guidelines require that the agent informs users who choose the default settings of the ramifications of the choice, and requires users to assent to that choice. Any company interacting with an agent that identifies itself as ACCPT compliant can rely on the validity of contracts made with that agent despite potential differences between the user’s personal preferences and the preferences as expressed by the computerized agent. That liability would be shifted to the authors of agents pledging ACCPT compliance (under negligence standards for deviations from the ACCPT guidelines). If a program does not identify itself as ACCPT compliant, the contracting parties retain liability for reliance on invalid contracts. In that way, a company which collects information from an agent that does not pledge ACCPT compliance is at its own peril and authors of agents that falsely pledge ACCPT compliance are also in peril.
Our proposal also encourages the development of other privacy protecting technologies, such as a framework for anonymous browsing and electronic commerce. This includes an addition to IPv6 for connecting to servers without disclosing one’s IP address, an anonymous payment protocol and an anonymous shipping protocol (for delivering goods ordered on-line).
New technology must not reopen the oldest threats to our basic rights: liberty, and privacy. But government should not simply block or regulate all that electronic progress. If we are to move full speed ahead into the Information Age, government must do more to protect your rights - in a way that empowers you more, not less. We need an electronic bill of rights for this electronic age.
-Vice President Al Gore
The World Wide Web has grown exponentially from its proposal in March of 1989 as a way for physicists to keep track information at the European Laboratory for Particle Physics (CERN). More than one hundred and fifty million people now use the Web and any effort to count the number of individual sites is doomed to be outdated before finished. Those sites represent a wide range of interests and ways of using the Web but almost all share at least one characteristic: the collection of information. Ninety-two percent of websites recently surveyed by the United States Federal Trade Commission (FTC) collect information from their users. Add Internet Protocol (IP) address logging and that number nears one hundred percent. The U.S. government believes in industry self-regulation but thus far self-regulation has been an unqualified disaster. Fewer than fourteen percent of the sites surveyed by the FTC even give notice of their privacy policies. The default privacy settings on the two most popular web browsers are set at their most lenient. Users do not own their personal information and current informational practices point toward more abuse of personal information rather than less.
Consider the hypothetical surfer, Alfred. Alfred surfs from home and goes to a wide variety of sites. Alfred checks the performance of his favorite technology stocks on TheStockTickerWeb.Com. Being an older man, Alfred looks for information on the hereditary nature of prostrate cancer at ProstrateInfo.Com and checks out the job listings at a web publishing site called CabledNews.com. He buys a few books on gardening at Books4U.com and has them delivered. Even if Alfred has been careful, a large quantity of personal information has been collected from these sites and others. Alfred may be surprised when he receives an e-mail from TradeEase.com telling him that anyone who invests in tech stocks should subscribe to their insider’s guide. Or, come Monday morning, when he finds the company policy on job-seeking while still employed on his desk. Or when he receives advertisements for a new prostrate cancer wonder drug by mail at his home. Or when his HMO calls him in and talks about raising his rate if prostrate cancer is in his family. However, all of these nightmare scenarios could come true today. Technology enables it, law allows it, the market encourages it, and social norms constrain only the most flagrant privacy violations, and then only as long as the public’s attention affords.
This paper will describe the current privacy framework in the United States and outline why neither technology, nor law, nor the market, nor social norms adequately regulate the privacy practices of data collectors. It will examine two current privacy solutions as case studies of how the current privacy framework is inhospitable to personal privacy. It will propose a new framework for privacy protection and discuss some possible critiques of the proposed framework. But first we must be clear on the scope of the project and the goals we hoped to achieve in crafting this proposal.
This white paper puts forward a privacy framework that would protect the privacy of individuals on the World Wide Web. As such, it has a wide focus but does not attempt to solve every problem of individual privacy. In particular, we do not discuss workplace privacy, as it is a rapidly evolving field with issues specific to the workplace that have already been well commented on by many authors. We do not discuss governmental invasions of privacy because some protection already exists in this area. We likewise do not attempt to provide a framework for the protection of personal data from interception in transit or unauthorized access in storage because these too are covered by existing privacy regulations. We also do not specifically target children’s privacy issues which have received much attention in this Congress, though our proposal is adaptable to their needs. Instead, this paper aims to propose a framework for individual privacy protection from private entities who collect data on the World Wide Web.
Within the scope of individual privacy on the World Wide Web, there are many possible frameworks that would reflect different goals. The current government stance on privacy has allowed the goals of business to be the basis for the privacy framework in this country. Our proposal follows directly from a different set of goals. These goals reflect our biases and are listed below in order of their importance to us in crafting this proposal.
Current and Proposed Regulatory Frameworks
Cyberspace is regulated in a variety of ways. Law obviously can affect behavior, even in cyberspace, as the courts are becoming more familiar with the space. Sites react to lawsuits and courts dictate the ways in which certain sites function. Market forces affect the space too. Popular sites get financial backing and can afford to hire the best graphic designers. Similarly, lucrative content or business models breed many sites. Social norms further affect the space as sites appear to serve different communities and fads dictate website style. Finally, the most important effect on cyberspace is that of its technical architecture. Those characteristics that differentiate the web from chat or a real-space library are functions of its unique architecture.
It is important to realize that all of these forces are fluid, and, in the next section, we propose changes to the legal regime and technical architecture in order to effect changes in the market and social norms. However, we must first understand why the current technical, legal, market and social forces do not offer sufficient protection for individual privacy and that is the subject of this section.
The current state of Internet and World Wide Web technology provides ample opportunity for the collection of personal information about a user. More importantly, the user possesses relatively little control over the flow of this information. One of the most obvious privacy threats comes from information freely handed over by the user – filled-out surveys, purchases with credit cards and mailing addresses, etc. This information, amassed, stored, and traded, can present a significant privacy threat. Other less visible privacy threats, that users may or may not be aware of are embodied in the technical architecture of the Internet and the World Wide Web.
Internet Protocol (IP), as its name suggests, is the fundamental protocol of the Internet. Any computer connected to the Internet, despite the nature and composition of the computer’s local subnet (the local network of which it is a part) has an IP address. A computer on the Internet may have a static IP address, in which case it is always the same unique address. Alternatively, a computer may have a dynamically allocated IP address, which is assigned (usually on a per-session basis) from a pool of addresses available to the computer’s subnet.
IP addresses currently consist of four one-byte (i.e., ranging from 0 to 256) numbers, normally delimited by periods (e.g., "127.0.0.1"). A subnet may use IP addresses that are either Class A, Class B, or Class C addresses. The class of the addresses determines how many total IP addresses a subnet possesses. In a Class A address, the first one-byte number in the address is identical for all machines on the subnet (e.g., all MIT IP addresses start begin with the number 18). In a Class B address, the first two numbers in the address are identical for all machines on the subnet. In a Class C address, the first three numbers are identical.
IP addresses are equivalent to the U.S. Post Office’s ZIP code plus four digits numbering system; at any one time, only one computer should have any one address, and anything sent to that address should not end up anywhere else instead. IP addresses are used to ensure that data on the Internet is sent to the correct computer. For this reason, a computer must indicate its IP address when making a request for data, or the responding computer will not know where to send its reply.
Computers that users interact with, such as web servers, will obtain the IP addresses of their visitors. In most cases, these IP addresses are written to a log file. The server machine can also easily indicate what IP address queried for what page. More sophisticated IP logging systems might tie this information to other queries and data acquired by other collection technologies, which are discussed below.
An IP address may betray certain information about a computer. At the very least, in a subnet where IP addresses are dynamically allocated, an IP address will indicate the general location of a computer. For instance, an IP address may indicate that a user is from AOL or MIT. In many cases, with static IP address, an IP address alone can indicate the identity of a user and tie him to other data collected about him.
One hypothetical scenario might run as follows: On one day a user with a static IP address goes to Playboy’s website and looks at a playmate pictorial but does not do anything to identify himself in any other way. His IP will still be tied to his picture viewing session later on. If, at another time, he revisits the Playboy site but "only reads it for the articles," and he decides to give his name and mailing address so that he can receive Playboy’s new free "just the articles" mailing, he has really revealed his identity for every visit to the site. Playboy’s server can now associate a certain name and mailing address with the IP address it originated from. Thus, the user’s name can be associated with the pictorial-viewing web session of the previous day. IP correlated profiles are not foolproof, however. Under this method, the IP address only identifies the computer; a different user of the computer may have visited the site for the pictorial query.
The Internet is currently undergoing a major technological change. Many of the protocols designed when the Internet was a fraction of its current size are beginning to show signs of wear. The current version of IP (Internet Protocol Version 4) only has provisions for 32 bit IP numbers. This places an upper limit on the number of computers with unique IP addresses on the Internet at once. Although 232 is a fairly large number, the assignment is fairly inefficient by design. For instance, MIT has more than 16 million IP numbers for less than 16 thousand people. The end result is that there is a severe shortage of IP numbers. IP numbers sell for as much as $150 per year in some areas.
To correct this (and several smaller problems), the Internet will convert to a new version of IP, known as IPv6 (Internet Protocol version 6). IPv6 is a complete revamp of the most fundamental layers of the Internet. IPv6 will increase IP size to 128 bits, giving the astronomical number of 2128 IP addresses. It includes other improvements useful for automatic configuration of machines, better routing of Internet traffic, better multicasting (transmitting the same data to a large number of machines), better machine mobility, maintaining large networks, transmitting encrypted data and a host of other tasks.
With the introduction of IPv6, there will be about 3.4*1038 IP numbers. Within a few years, almost all computers will have unique IP addresses. Businesses like DoubleClick will no longer need cookies (see below) to track individual machines. The proposals below attempt to counter this by allowing users to connect to servers without disclosing their IP addresses.
It has been suggested that the adoption of IPv6 should also include an anonymizing router technology to allow anonymous connections. Each router between the client and the server would mangle the IP by marking what router it came from, adding a few random bits, and encrypting it with a private key. When the web server responded, each router would unmangle the IP, pick out the bits indicating what router it came from, and send it to the previous router. Keys (and their corresponding mangled IP addresses) would expire after a preset amount of time (~24 hours). Alternatively, instead of encrypting, routers could store IP addresses in memory, and replace them with a reference to the IP’s location in memory.
Although mangling and unmangling IP addresses may seem like an unnecessary burden on routers, encryption and decryption is fast, and the actual difference in cost would be marginal. Some Cisco routers can already encrypt packets (although not for the purpose of anonymity), and there are extensions to most operating systems that allow for ordinary computers to do the same. Simple encryption chips easily achieve speeds in excess of 177 Mbits/sec. On the low-end, instead of encryption, IP addresses could easily be stored in random slots in a cheap memory table.
The adoption of anonymizing routers could potentially cause the tracking of "crackers" (individuals that break into other computers) to be significantly more difficult. Right now, IP logs can be used to track many attacks. With anonymizing routers, law enforcement would need to ask (or possibly subpoena) every router between the cracker and the compromised machine to unmangle the IP and figure out where the attack originated. However, experienced crackers already conceal or erase their IP addresses from logs. It does not take long for amateur crackers to pick up techniques from experts.
Anonymizing proxies serve the same purpose as anonymizing routers, but use a different technology. Instead of connecting directly to a web server, the web browser connects to a trusted proxy and asks it to retrieve a web page. The proxy retrieves the web page, and sends it back to the browser. The web server only knows the proxy’s IP, and not the user’s. Since anonymizing proxies are shared by a number of users and do not transmit any individually identifying information, web servers have no way of tracking users going through proxies.
There are a number of disadvantages to anonymizing proxies. A malicious or compromised proxy could log all of its user's transactions. Although there are free anonymizing proxies available on the web, they are not very popular for a number of reasons. To begin with, few people know about them. Of those that do, most opt not to use them because there is a noticeable lag, and making the appropriate configurations on the web browser is a hassle. Further, because there are twice as many requests for every page retrieved when proxies are used, universal adoption could significantly increase traffic on the Internet. And if a significant number of individuals start using them, people will no longer be able to afford to operate proxies for free.
However, proxies are already used in a number of places for other reasons. Filtering proxies censor certain types of web content in libraries, schools, small oppressive countries, and large oppressive businesses. Caching proxies remember pages that were recently accessed by users, and can quickly retrieve them for other users, increasing speed and reducing bandwidth. Firewalls that filter all packets sent to the Internet frequently provide proxies for web content. Converting an existing proxy to remove identifying information is easy, and anonymizing proxies are an excellent option for places where another form of proxy is already in use.
Hypertext Transfer Protocol (HTTP)
Hypertext Transfer Protocol (HTTP) is the protocol used by web servers to fulfill user requests for web pages. One of the distinguishing features of HTTP (as opposed to File Transfer Protocol or Telnet) is its instantaneous nature. There is no real connection between a web server and browser during an HTTP session. The browser makes a request, the server fills it and moves on to its next request. When your browser makes another request, it does so as if it had never made the first. This is a good thing because it reduces server load (the server does not need to keep a connection open with your computer while you browse a page) but it is a bad thing because your browser must make a new connection for every request and the server treats every request as unrelated to any other. So-called "stateless" protocols are a problem for features like shopping carts or password saving because such features require some memory of what happened in previous requests from the same browser.
Cookies were created to add "state" to HTTP. They are bits of information, generally text, that may be stored on either a user’s computer (client-side cookies) or on a web server that the user is visiting (server-side cookies). Client-side cookies may be specified to be readable by only a particular machine (e.g., personal.lycos.com), only machines in a certain domain (e.g., preferences.com), or any computer. The readability scope of server-side cookies depends on the network and architecture of the server site (for instance, data may be stored in a central LDAP database, discussed below).
Users, in general, have very little control over the use of cookies. Some web browsers allow users to completely disable cookies (which prevents the user from taking advantage of a large number of useful sites and services in the web industry), to accept or reject them one by one (which can become very tiresome very quickly), or to accept cookies which may only be read by the specific server which issued them. Users have no control over server-side cookies. Although website providers have more control over server-side cookies, they generally use client-side cookies for several reasons. To begin with, web browsers automatically save client-side cookies between web sessions, and browsers often keep a different set of cookies for each user on a computer. The maintenance of server-side cookies between sessions, by contrast, generally requires a user to log in to the server at the beginning of each session to identify himself, although IP address logging, which may not indicate the same computer across multiple sessions, may eliminate this requirement. Additionally, increasing the scope of readability for a client-side cookie (e.g., for a whole domain) is much easier than for a server-side cookie. Sharing server-side cookies often requires a larger investment in a particular server architecture and intranet.
Because of their persistence, as well as their user-level targetablility, client-side cookies serve as excellent tools to track users and to tie together various pieces of data collected about them. A server may assign a user a unique ID in a cookie. This may serve the same basic identifying function as an IP address, but the ID is more likely to be traceable to a single, unique user – although, unlike an IP address, a technically savvy user may reject or even edit/hack client-side cookies. Once a user has a unique cookie ID, he may be tracked across a site or even multiple sites in a domain. Then, if at any of these sites a user provides other information about himself, such as an address, as in the Playboy scenario, or an interest in a certain book on Amazon.com (by adding it to his "shopping cart"), the new information can be tied together with the user ID and any other information collected.
An Alternative to Cookies: Client-Side Targeting
DoubleClick, Preferences.com, and other targeted web advertisement companies use cookies to direct ads at individuals based on their browsing habits. An alternative to this system would be one in which the web browser would log browsing habits and pick ads itself. Targeted ad companies would no longer need knowledge about individuals to target advertising.
In the simplest version, an ad company would send multiple ads with lists of keywords. The browser would pick the one most appropriate for the user based on browsing habits and tell the ad provider which ad it picked through an anonymous protocol, like the survey protocol described above.
In more advanced versions, an ad company could send a bit of Java bytecode that the browser would run to decide between ads. The browser could also have a profile of the user filled out by the user when the browser initially runs. If connections to the ad provider are properly anonymized, the provider could have a conversation with the browser to pick the best ad.
Guaranteeing that an ad company cannot tie back ad choices to individual browsers is very important; otherwise, this technology could be more dangerous than cookies. An ad company could ask very specific questions, log the results, and build a much more detailed profile.
Lightweight Directory Access Protocol (LDAP) Databases
Lightweight Directory Access Protocol (LDAP) was designed to provide quick access to a directory or database of information over a network. An LDAP database, like any database, can store information in, and look up information based upon, various fields. Thus, an LDAP database might store users, their e-mail addresses, preferences, mailing information, etc. LDAP is useful for collecting personal data on the Internet because multiple servers within a website provider’s intranet may easily and quickly access a central system of LDAP database servers. Because most modern-day, industrial-strength websites, actually involve multiple mirrored front end servers and multiple layers of computers behind the front end in order to handle heavy loads, an LDAP-style system allows users’ personal information to be collected, distributed, and stored more easily.
This technology has important implications for collection of private data. As stated, LDAP databases can store a wealth of information, and the LDAP front end protocol and implementation allows for rapid storage and retrieval of this information. These properties alone greatly reduce the cost of collecting private information. Additionally, because LDAP allows many machines to easily centralize data, collected personal information can be made available to a larger number of server machines and websites. In essence, LDAP is a technology that provides a backbone for large scale collection and sharing of users' private information. Without a technology like LDAP, several servers, on the same site or different sites, might collect a large amount of information about a user, but the machines would unable to easily collate the data. Such a situation would be somewhat like the "fog of war," where many events are observed in many different places, but the communication of information from various battlegrounds to the generals in the army headquarters is difficult. LDAP provides the roads and couriers to bring the information to the headquarters.
JavaScript and VBScript are two similar technologies (the former developed by Netscape, the latter by Microsoft), that direct web browsers to perform certain functions and transfer certain information. When a user downloads a page from a server, that page may contain these technologies, which instruct the browser to perform certain tasks either automatically or upon certain user actions. Most data-collection methods that utilize these technologies rely on bugs in the implementations and specifications of the scripts. Although most or all of these bugs have been corrected in the latest versions of the browsers that support JavaScript and/or VBScript, a large number of people are still using versions that harbor security weaknesses. Thus, a brief discussion of these weaknesses is warranted as part of the current state of technology.
Scripts can obtain information about a user by reading their web caches (pools of recently visited web pages that a browser often keeps for better performance) or reading data about a computer type or the files within it. This data is often sent back to the server through a hidden form similar to a typical HTML form, except that all of the fields are invisible. Needless to say, these methods for collecting personal data are sufficiently shady that most or all mainstream commercial websites do not utilize them. Despite this, the potential risk of privacy violations through script security holes is very high.
Java and ActiveX are two somewhat similar (for our purposes) technologies (the former developed by Sun, the latter by Microsoft) that allow small, contained programs (applets or components), originating from a web server, to be executed on a user’s computer. Java programs are usually restricted by a sandbox or a security manager. The former is a sealed off environment on the user’s computer which contains no personal data or files, and the latter is a more granulated system that allows programs to request -- and be allowed or denied -- access to various personal computer resources to the extent that they cannot collect any useful personal data. However, if the user explicitly grants permissions to the Java programs, they may read or manipulate files and settings on the user's computer, as well as send information to another machine on the Internet. Only the latest versions of Java implementations provide a full security manager as opposed to a sandbox.
ActiveX is based on the all-or-nothing web of trust system. A user downloads an ActiveX component onto his system, and if he allows it to run, it has free reign on his computer. ActiveX components can be signed by a "trusted entity" that vouches for the identity of the original author, and sometimes, the security of the component. It is up to the user to decide whether he trusts the author and the "trusted entity."
Despite the potential for extra security protection in the latest versions of Java and ActiveX, the ability of a site to collect private information is still quite strong. In the end, a user must trust those sites to which he does grant special access to protect the confidentiality of the information they collect. Non-technological standards, such as TRUSTe (see below), help to alleviate this problem to some extent.
Credit cards are the most common method of payment on-line, but they have a number of problems associated with their use. Users must disclose their names, card numbers, and card expiration dates. Furthermore, credit cards leave an audit trail; the credit card companies have a log of almost all purchases made on-line. To solve the privacy problem (and more importantly, the potential problems of on-line credit card fraud), cryptographers have come up with a number of secure, on-line payment protocols. The goals of such protocols, as defined by T. Okamoto and K. Ohta, are:
DigiCash, once the dominant player in this field, recently filed for Chapter 11 bankruptcy. Several other companies are currently developing smart cards, and in the process, digital cash. Two proposed payment protocols for protecting privacy under a digital cash regime are outlined below.
In the first protocol, each denomination is tied to a public/private key pair. Owners of that denomination hold the private key and a banking institution holds the public key. When a buyer makes a purchase, the seller creates a private/public key pair, and shows the buyer the public key. The buyer sends an anonymous, encrypted instruction to the financial institution, requesting that the money be transferred to a new public key. He signs the request with the old private key. The financial institution publicly broadcasts a signature of the transaction, so the seller knows the money is available under his private/public key pair.
This protocol meets the needs of independence, security, transferability, divisibility, and privacy. It fails for smart cards and off-line payment.
Most cryptographic protocols designed work with smart cards are based on a physical scheme: Alice prepares 1000 money orders for $100. She puts each, together with a piece of carbon paper, in a different envelope. She hands the 1000 envelopes to the bank. The bank verifies that 999 of the envelopes contain a money order for $100, deducts $100 from Alice's account, and blindly signs the last one. Alice gives the money order to a merchant. The merchant verifies the bank's signature, and accepts the money. The merchant takes the money order to the bank, which verifies its own signature, and gives the merchant the money.
Note that electronically, the bank can sign an "envelope" by signing a one-way hash of the money order -- the "closed envelopes." The bank '"opens" them by requesting that Alice show a money order, and verifying the hash on that order.
This protocol meets five of the six goals. Though Alice can easily copy the money order and use it over, this can be corrected by adding a random uniqueness string to each money order. When the bank receives a money order, it can verify that it has not received a money order with the same uniqueness string before.
Although this protocol prevents Alice and the merchant from cheating the bank, it does not identify whether it was the customer or Alice who tried to cheat the bank. There is an additional protocol that verifies this, although it is impossible to explain in detail without a presenting a stronger cryptographic background. The basic idea is:
Alice, in addition to putting a uniqueness string on the money order, places on it a series of 100 "identity pairs," designed in such a way that any one element of a pair does not reveal her identity, but any matching pair can be combined to give her identity (name, address, etc.). When Alice makes a purchase, the merchant asks Alice to reveal a specific half of each identity string ("Show me the second string from the first pair, the first from the second pair ..."). If Alice tries to cheat and copy her money order, the second time she tried to use the money order, the merchant would ask for a different set of identity strings (the chances of asking for the same set are one in 2100). The bank could match up two identity pairs and confirm that Alice tried to cheat. If a merchant tries to cheat, he would only have one set of identity strings, and the bank could tell it was the merchant.
Perfect digital cash allows for significant abuses. For instance, with any one of the protocols in the second set, consider the perfect crime:
Alice kidnaps a baby. Alice sends the law enforcement authorities an anonymous note with the hashes of 1000 money orders, and a request that a bank sign them and publish the signatures in a newspaper (or else the baby dies). The authorities comply. Alice frees the baby. Unlike physical systems, there is no way to track Alice. She is free to spend the money.
When goods are ordered on-line, they need to be delivered. Traditional delivery methods require the user to disclose his name and address. A number of anonymous delivery methods exist that are designed to circumvent this problem. Notice the similarity in the three methods to status quo, anonymizing proxies, and anonymizing routers for delivering packets on the Internet.
Classically, anonymous delivery has been handled through post office boxes. The user is assigned a unique, untraceable number by the post office. Deliveries can be sent by that number without disclosing the user’s identity.
But post office boxes are a poor solution. They are expensive, and most people cannot afford to have a unique box for each transaction. Eventually, a person's box may be tied back to his identity, and all of the previous transactions are compromised.
The post office publishes a public key every month. When a user gives out his address, he encrypts it, together with an expiration date and a few random bits, with the post office’s public key. The post office can decrypt it and deliver to that address, but the sender cannot trace it down to a specific person. Further, unsolicited mail can only be sent for a short time, because the address expires. The encrypted data could also contain the merchant’s name and address, so the post office would only deliver packages sent by the merchant.
The product is sent to a trusted third party, which forwards the product to the intended recipient. This doubles the cost of shipping, and it is often not possible to find a trusted party offering this sort of service.
Case Study: A Technological Solution
In recent times, the lack of good privacy on the Internet has been spotlighted and examined following the pressure from numerous sources. The general Internet user’s desire for stronger privacy protection as he uses the Internet and the impending possibility of governmental intervention to help create stricter privacy controls have driven many individuals, corporations, and organizations to try to create solutions to the expressed privacy concerns. For example some individuals have created anonymizing remailers for anonymous e-mail, and others have created anonymizing browsers or proxies. Due to the difficulties users encounter trying to find websites’ privacy practices, many individuals and organizations have made proposals to control the release of their personal information.
In June of 1997, Netscape Communications, Inc., FireFly, LLC., and Verisign, Inc., proposed the Open Profiling Standard (OPS) to address concerns about privacy on the web. OPS required that when a user goes to a website, the website may (via HTTP, as was proposed) ask the user’s computer for information about that user. Any piece of information about the user can be marked by the user as something his computer is always allowed to freely distribute (ALLOW), something that should never be distributed (DENY), or something the user should always be prompted to decide upon at the time of request; this information would be kept locally on his/her computer on a "virtual business card" or vCard, which contains certified information about the user as the user chooses.
Platform for Privacy Preferences (P3P)
While OPS has for the most part fallen by the way-side, another proposal under development during and after the wake of OPS, adopting many of its features, is the Platform for Privacy Preferences (P3P). This proposal, sponsored by the World Wide Web Consortium (W3C), has been in development since October of 1997 and is still under development today. The concept behind P3P is that one can set up a flexible software agent to represent the user’s privacy interests that will then interact with websites as user moves around the WWW to create agreements as to what information the user agent, and thus the user, will give to a website, as well as how the website can use this information.
|
Figure 1: A P3P pseudonymous interaction with a service |
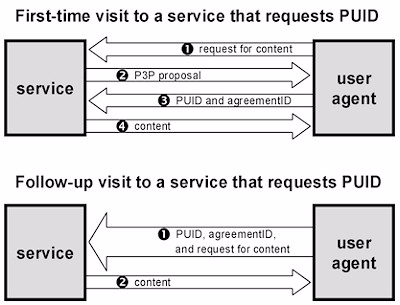
A P3P session begins when a user makes a request for a URL (see Figure 1, above). The contacted server then replies to the user with one or more machine-readable P3P proposals encoded in Extensible Markup Language (XML) as part of the HTTP headers. In this proposal, the organization maintaining the server makes a declaration of its identity and privacy practices. This proposal, applicable only to the requested URL and similar sites, lists what data elements the server would like to collect from the user while the user is connected, how those data elements are to be used, and specifically, whether those data elements will be used in a personally identifying manner.
The proposal is then parsed by the user’s agent, which would most likely be an extension of the user's browser/client software. The agent would compare the proposal to the user’s privacy settings. If the user already has settings that would agree with the proposal, the proposal may be automatically accepted If the user has no settings appropriate to the proposal, the user’s agent may present the user with the proposal and prompt for a response, reject the proposal outright, create an alternative proposal (counter-proposal) and send it to the server, or ask the server for an alternative proposal. Once a mutually acceptable proposal is found between the user’s agent and the server, an agreement/contract is met, and the user will gain access to the service.
P3P has a number of important, inherent strengths. Many of these strengths stem from the fact that P3P was designed with flexibility in mind. In this respect, P3P is very different than many of the other W3C meta-data activities, such as the Platform for Internet Content Selection (PICS). PICS is used in the privacy domain to statically define privacy practices (as well as content), and the only room for control based upon a PICS tag would be a complete accept or a complete reject. P3P allows for far greater freedom to negotiate, for multiple proposals may be sent by the service, and multiple counter-proposals and requests may be made by the user’s agent before an acceptable contract is reached. There are also a number of points in the use of P3P where additions or changes are possible. For example, one important possible addition is for the user agent to store the proposal IDs (also called propIDs) that are transmitted on the agreement of a proposal. The next time the user tries to access the site, the saved propID need merely be sent with the user’s request for the service to show that a previous contract has already been struck between the user and the service and the user desires to use the same contract again.
Another boon brought about through flexibility is the fact that the P3P specification defines a standard set of base data elements that all P3P related software should acknowledge, but provides a mechanism that will let services create new data elements for users to consider. Also, the fact that the W3C is making P3P's design generally available will encourage its adoption and improvement, fostering competition and innovation.
During a P3P negotiation, the creation of Temporary Unique IDs (TUIDs) is a mechanism that allows P3P to keep track of the state of the current negotiation: basic information required to determine the current state of the negotiation, such as who had last "spoken" (the user’s agent, the service, etc.) and the IP address of the user (such that the service knows where to send data), etc. These TUIDs are necessary for the connection and negotiation to occur but are especially useful to websites trying to collect aggregate information on the users that connect to their website. Pairwise Unique IDs, or PUIDs, are an additional mechanism with which to give information to be collected in aggregate to the service. If a user sets up his user agent to use PUIDs, additional information about the agreement that has been reached will be transmitted to the service for collection and aggregation. The combined use of PUIDs and TUIDs are a possible improvement on the current cookies mechanism with which the website can collect information in aggregate about its users. Also, to facilitate the communication of personal information when it is desired by both the website and the user, such as in the process of making an on-line purchase, the P3P user agent will store a base set of user data elements locally that can then be sent easily while connected to a website via P3P. In fact, the combined use of a data repository with PUIDs and TUIDs to replace cookies is actually highly beneficial to businesses desiring to collect information on their users. The cookie structure as it currently exists only allows cookies to exist for three months. The use of these P3P features would offer a website more precise and longer lasting information on the users of their service, and it would do so, unlike cookies, in a manner which the user will find acceptable – or it won't be done at all.
Another positive point in the design of P3P is its use of current existing technological standards. The proposed transport mechanism of the P3P proposal and data elements is an extension of HTTP 1.1, the standard protocol used for WWW information transport. P3P also makes use of XML for "creating elements used to structure data" and thus to communicate the machine-readable P3P proposals and counter-proposals. The Rich Data Format (RDF) is used to provide a "model for structuring data such that it can be used for describing Web resources and their relations to other resources" for the data elements in the proposal. The use of these standards will make the development of servers and user agents capable of making P3P negotiations come about more quickly and easily. Also, the use of a harmonized vocabulary for the proposals means that there will be no misinterpretation between the public and a service about what the privacy practices described in the proposal actually mean, and will also enforce the requirement of certain basic privacy practices to be revealed. Furthermore, the use of P3P does not inhibit the use of other technological privacy solutions, such as anonymized browsing.
P3P has a number of faults as well, however. The design for P3P, now in its third revision, has grown somewhat overly large, complicated, and unwieldy. This excessive verbosity in the definition of the P3P communication syntax will be a burden on the shoulders of developers desiring to write software to be used in P3P transactions, and may even be a deterrent to some developers to begin to write such utilities at all. Also, the extra amount of communication that must occur before a user accesses a website in a "normal" fashion will create a much greater amount of network traffic and load on web servers that will inhibit the overall speed and growth of the Internet. The fact that P3P communications are not encrypted or protected in any other way also leaves the user data transmitted via P3P open to third party interception.
Implementation of P3P servers and agents, and issues regarding the penetration of P3P, trouble the success of P3P. If agents are not easy to use, people will not want to bother with the initial setup of a P3P user agent, nor will they want to deal with proposals that cannot be decided by their agent and that request dialog from them. The authors of popularly used user agents will be in an extremely important position in the creation of the default profile with which the agents are distributed. Currently, Microsoft and Netscape dominate the WWW browser market, and if either was to create a user agent built into their browser, the default profile with which that browser/agent was submitted would drastically change the privacy practices of the entire Internet. Finally, the biggest problem impeding the desired penetration of P3P is the lack of any enforcement of the P3P negotiated contracts for privacy policy. Essentially P3P assumes that after having reached an acceptable contract with a service, the user will then trust the service to abide by that contract – an assumption that simply cannot be made.
On a more basic level, the fact remains that websites currently have no incentive to adopt P3P – the current legal regime allows them to collect information at-will, and so they have no reason to expend time, effort, and resources to form contracts with particular users to obtain their data. As long as websites do not adopt P3P, users will not push for the product – and so long as users do not push for it, websites will not feel pressure to adopt it. This point is discussed in more detail in the Markets and Norms section.
If the market's current resistance to the adoption of P3P can be overcome, P3P has a great chance of achieving its desired goals – to better protect the privacy of users while supplying websites with a clean and fair amount of information on the user. In fact, both Microsoft and Netscape have made numerous public statements as to their "commitment to privacy," and it is widely believe that companies would create user agents for P3P, upon the completion of the P3P specification. The most popular web server being used today, Apache, has made statements affirming its commitment to P3P, as well. With some mechanism in place to encourage these, and other sites, to make good on their commitments, P3P could likely succeed.
There are currently no legal limits on the use of information gathered through the methods described above in the absence of an explicit promise by the website to limit the use of such data. To date, federal governmental response to the possibility of privacy violations on the Internet has been to recommend industry self-regulation. However, a review of the current legal patchwork regarding informational privacy provides some insight as to how privacy is traditionally conceived, and protected, in the United States. Moreover, the erratic development of privacy law in the "real world" may be indicative of future difficulties with protecting privacy in cyberspace.
In the United States, privacy is protected by three mechanisms of law: constitutional law, case or common law, and statutes. As the supreme law of the land, the Constitution provides the framework within which the limits of privacy protection operate. Federal and state statutes, operating within the confines of the Constitution, explicitly regulate behavior and provide protection for privacy as conceived by the vox populi. State and federal courts interpret statutes and apply constitutional principles, generating case or common law, which, by precedent, govern future legal decision-making.
Constitutional Law and Common Law
In 1791, the Bill of Rights was created to protect the people of the United States from the government. Primarily through the First, Third, Fourth, and Fifth Amendments, various "zones of privacy" are protected from federal government intrusion. Although the right to privacy may not have been explicitly stated as a right of U.S. citizens, various courts have interpreted several Amendments to provide important ancillary protections for privacy.
The First Amendment is the authority behind freedom of speech. Although the constitutional prohibition on the regulation of speech usually concerns the freedom to speak, the doctrine also includes the freedom not to speak. Although the right to anonymity -- the right to withhold speech identifying oneself -- has been repeatedly upheld in the context of the print media, it is still unsettled whether this protection will be extended to on-line media. The First Amendment also provides for the right to free assemblage. It has been interpreted to protect the "freedom to associate and privacy in one's associations." For example, this has been extended to privacy in one's marital relations.
The Fourth Amendment protects people from searches based on a "reasonable expectation of privacy" test by excluding from criminal trials evidence obtained by an unconstitutional search. While the vagueness of the term "reasonable expectation" has foreseeably led to much litigation, the translation of the Fourth Amendment to the on-line world adds additional wrinkles to the debate over the meaning of the Fourth Amendment. Harvard Law School Professor Lawrence Lessig has lectured about this problem, pointing out that technology will soon make it possible to conduct "burdenless" searches. The Fourth Amendment prohibits "unreasonable" searches – and the newest advances now bring to light the latent ambiguity behind the term. Does "unreasonable" really refer to expectations of privacy or to the burden upon the individual searched?
The Constitution provides protection for private citizens from the government; for intrusions of privacy from non-state actors, common law has conferred some protection as well. Two basic areas of common law have been invoked to preserve people's right to privacy: tort law and contract law. Tort law involves wrongs committed by one person to another; the courts have long recognized the tort of invasion of privacy. Contract law involves agreements between parties and may govern the level of privacy granted, either explicitly (as in a contract for data that includes privacy provisions) or implicitly (as in an informal employment contract).
William Prosser, the original draftsman of the Restatement (Second) of Torts, delineated the four actions in tort for invasions of privacy as:
1) intrusion upon the plaintiff's seclusion or solitude, or into his private affairs;
2) public disclosure of embarrassing private facts about the plaintiff;
3) publicity which places the plaintiff in a false light in the public eye; and
4) appropriation, for the defendant's advantage, of the plaintiff's name or likeness.
There are many exceptions and defenses to the above claims, and it is often difficult in the privacy realm to specify what damage resulted from the wrong, making these doctrines very difficult to use in court.
According to Joel Reidenberg, most state courts recognize actions for at least one of these privacy invasions and some have codified aspects of the four actions in both civil and criminal statutes. Yet Reidenberg notes that this is not the case in the majority of states. New York, for example, only allows the misappropriation claim, and Minnesota is reputed to disallow all four actions for privacy intrusion.
Whereas tort law awards compensation for intrusions on privacy after the fact, contract law attempts to set the terms of the "intrusions" beforehand. Most of the measures suggested to protect online privacy, either by technology or by statute, inherently rely on contract law – that is, they envision people contracting to "sell" information about themselves in exchange for access. This means that all of these measures are limited by all of the flaws that exist in contract law, like informed consent, unequal bargaining power, and mandatory non-negotiable contracts (also known as contracts of adhesion). For example, some websites offer basic (and superficial) information about their privacy policies and warn the user that use of the site is conditioned upon acceptance of these practices. However, there is no opportunity for the user to bargain over the terms of the contract – the terms are offered on a take-it or leave-it basis. Because most sites have similar policies, or do not delineate their practices at all, the user generally has only the choice between surfing on the terms of website owners or not surfing at all. Further, there is little point to a user rejecting a particular website over its privacy policies, as many other sites – which do not reveal their policies – may use the user's data, and so any particular transaction has little value to the user.
However, in real space, the legal issues involved in cases revolving contract terms with explicit privacy protections are relatively uninteresting. Rather than presenting novel issues of law, the translation of contract law from the real world to the cyberworld would seem to lead to consistency and present little difficulty.
In those cases where terms governing the protection of privacy have not been explicitly delineated in contracts or agreements, the courts have been more divided. Privacy implied in contracts mostly surfaces as an issue in workplace privacy, where employees may or may not have waived their right to privacy implicitly by agreeing to work for an employer. However, the trend appears to be that the courts will allow most monitoring on the theory that there is no "reasonable expectation of privacy" in the workplace. Techniques include video surveillance, keystroke monitoring, and monitoring of e-mail and Internet usage.
Federal Statutes and Common Law
In 1977, recognizing the danger posed by new technology, Congress established the Privacy Protection Study Commission in order to conduct an extensive study of privacy rights in a world with computers. The Commission focused on record-keeping in eight different areas: (1) consumer-credit; (2) the depository relationship; (3) mailing lists; (4) insurance; (5) the employer-employee relationship; (6) medical care; (7) investigative reporting agencies; and (8) education. The study concluded that, even within the limits of law, privacy was not sufficiently protected from government, nor from private industry. Despite this early warning, it is only recently that Congress began to move towards more protection of privacy.
While the substantial number of Internet bills introduced recently in Congress seems promising, very few bills have actually been enacted, suggesting that the government is reluctant to make many changes to its policy on the Internet. Unfortunately, Congress' inaction, particularly in the area of privacy, does not mean that the status quo will prevail. The currently allowed level of "legitimate" access to information allows a great deal of room for the quickly improving methods of collecting, aggregating, organizing, storing and "mining" data. Without a radical move by the legislature, novel cases and controversies will continue to arise, the legal vacuum will have to be filled in "on a piecemeal basis by ad hoc judicial decisions, initiatives by state attorneys general and other state and local regulators, and by restrictions imposed on the United States from abroad" – providing little consistency and even less peace of mind for online participants.
Legislation regarding privacy has been scarce and fairly spotty; legislation regarding privacy online is even rarer. The government deals with particular areas on an ad hoc basis, largely in response to public outrage, or as an afterthought in legislation dealing mainly with other bodies of law. Moreover, most of the legislation has been in reference to the government intruding on an individual's privacy. Very little protection has been added for intrusions by private actors.
Probably the earliest important piece of privacy legislation was the Privacy Act of 1974 (amended). It granted individuals the right to see, copy, and correct their federal agency records, as well as to restrict disclosures of the information without consent. The limitation is that the Privacy Act only applies to government actors.
Privacy Protection Act (PPA) of 1980
The government made another important move with the enactment of the Privacy Protection Act (PPA) of 1980. The PPA prohibits law enforcement from searching or seizing "work product" and "documentary" materials from journalists and publishers unless they have probable cause to believe the person possessing the materials is involved in a crime, and the materials sought are evidence of the crime. Thus, online systems and their users are protected by the PPA "to the extent they act as publishers and maintain publishing-related materials on the system." Again, this was a limitation against government action, yet provided almost no protection from private entities.
Electronic Communications Privacy Act (ECPA) of 1986
With the Electronic Communications Privacy Act (ECPA) of 1986, the government finally took steps to limit the reach of private actors. Enacted to amend Title III of the Omnibus Crime Control and Safe Streets Act of 1968, which limited the use of telephone wiretapping, the ECPA covers all forms of digital communications, including private e-mail. Title I of the ECPA prohibits unauthorized interception and Title II governs unauthorized access to stored communications. The distinction between messages in transmission and stored messages is important because transmitted messages are afforded a much higher level of protection than stored communications; Title II provides for lower fines, higher burdens of proof, and lower requirements for security. Courts, following the foundational case of Steve Jackson Games v. United States Secret Service, have interpreted Title I very narrowly, leaving stored e-mail -- even where a user has not yet accessed it -- only Title II protection. It is questionable whether e-mail packets "stored" on routers en-route between mail servers would get Title I protection, but the courts have not yet discussed this issue.
Courts have been extremely reluctant to find that messages were intercepted during transmission. Moreover, employers may avoid liability under Title I by showing that the employee consented to the interception either expressly or by implication. Under the "ordinary course" exception, an employer may intercept an employee's e-mail communications in the ordinary course of its business if it uses "equipment or [a] facility, or any component thereof" furnished by the provider of the electronic communication service in the ordinary course of its business. However, legitimate purposes may include monitoring to reduce personal use.
A person violates Title II of the ECPA, the Stored Communications Act, if he or she "intentionally accesses without authorization a facility through which an electronic communication service is provided." Such unlawful invasions are more severely sanctioned when the violation was motivated by "commercial advantage, malicious destruction or damage, or private commercial gain." There are, however, two major exceptions. There is no violation of the Stored Communications Act when the conduct is authorized "by the person or entity providing a wire or electronic communications service." Many legal commentators warn that this exception may be interpreted by the courts to mean that private employers who maintain a computer system have the ability to browse employee e-mail communications without violating the ECPA Title II.
Under the user exception or consent exception, the Stored Communications Act does not apply to conduct authorized "by a user of that service with respect to a communication of or intended for that user." Such authorization may be expressly given, and in some cases, reasonably implied from the surrounding situation.
One final exception to the ECPA may be required by the Constitution. Since the jurisdiction of Congress is limited to interstate commerce, the definition of "electronic communications" under the ECPA is limited to communications and systems which "affect interstate or foreign commerce." Therefore, a computer system which does not cross state lines may not be covered by the ECPA. This would seem to exempt company-owned, internal e-mail systems.
These acts and other similar laws protect areas as broad and diverse as the interception and disclosure of electronic communications, protection for government-maintained databases, regulation of credit reports and financial records, telemarketing, and the "Bork law" that protects video rental records. Unfortunately, the industry-specific approach taken thus far by the government has not produced a general protection for personal data online. Moreover, some experts contend that existing provisions are inconsistent if not contradictory.
Unfortunately, it appears that a general protection for online information will not be created any time soon. Except for a few pockets, such as encryption legislation or protection of children, the probability of congressional action on any number of privacy bills is rather low. Echoing the thoughts of other commentators, Nicholas Allard conjectures that:
The immediate impact on Congress of the FTC's decision to give industry (IRSG) self-regulation a chance to work, and the uncertainty over how this approach can be reconciled with the European Union's privacy rules, probably will derail any action on privacy legislation this year.
Regardless of the expectations for enactment, most of the currently proposed legislation concerning privacy, abundant thought it may be, would not create a general protection for online information. Instead it replicates the past governmental pattern of providing industry-specific measures.
The proposed on-line privacy legislation can be divided up into five main categories:
1) Protection of Children
2) Protecting Personal Identification Data
3) Protecting Medical Records
4) Regulating Direct Marketing and Unsolicited E-Mail
For a more complete description of the proposed legislation, please see Appendix, Table of Pending Legislation.
While the U.S. has been moving slowly on the issue of privacy, this is not solely a domestic issue – and the U.S. needs to consider its role in the global information market. The most urgent consideration, the European Union Data Directive, went into effect October 25 of this year. The Directive sets out privacy standards to be observed in the collection, processing, and transmission of personal data (standards that are rarely observed in the US). European countries are also directed to prohibit transfer of personal data to countries that do not "ensure adequate levels of protection." Although the Directive was passed in 1995, it was only this past summer that U.S. government and industry began to seriously entertain the thought that European Union would actually find U.S. practices not up to European standards of data protection, and consequently restrict data flow. In fact, until very recently, the U.S. response had been to lobby European countries to convince them that the current U.S. policies were adequate.
Article 25 of the Directive has caused a stir in the United States because it prohibits transfers to countries that do not have similar privacy regulations giving "adequate protection" to consumers. The most basic provisions of the Directive are quite contrary to the status quo in the United States. For example, the Directive, if enacted into law by an EU member state, would require that data collectors provide advance notice of their intent to collect and use an individual's personal data; in addition they give that individual access to her data, the means to correct it, and the ability to object to its transfer to other organizations. Moreover, the enacted Directive would require that data collectors maintain the security and confidentiality of the personal data and only process personal data for specified, explicit, and legitimate purposes. More particularly, the common use of Internet cookies in the U.S. may be especially troublesome to the European Union Privacy Commission, which has previously stated that "transfers involving the collection of data in a particularly covert or clandestine manner (e.g. Internet cookies) pose particular risks to privacy." In theory, conflicts such as these could keep the United States off the Privacy Commission's White List of countries that provide adequate privacy protection.
Recognizing these dangers, various U.S. parties have begun to reconsider their privacy policies. The Commerce Department proposed guidelines to help U.S. companies meet the European Union's new privacy rules. The proposed guidelines include: notifications to individuals about the collection and use of personal information; instructions about how to limit or stop the use of that information; being told when information is being sold, rented, or shared with a third party; disclosure about how secure that information is from being stolen or misused, and instructions to individuals about accessing any and all information a company has obtained about them. As of late November, perhaps in recognition of the possible embargo in information, the Direct Marketing Association had agreed to endorse conditionally a series of guidelines proposed by the Commerce Department. What is encouraging is that these changes have come about despite the fact that the European Union had agreed to allow information to flow unimpeded between U.S. marketers and its member nations. How long this state of affairs will last, however, is unknown.
When Secretary of Commerce William Daley admonished businesses earlier this year that protecting privacy was in their best interest, he was talking about the threat of government regulation, not market forces. Businesses interested in collecting and sharing personal information about their site visitors have never had it so good. The collection, storage, analysis and sharing of information is cheap in today’s economy and consumers willingly part with personal data in a market where divulging that data without privacy protection is the norm.
As discussed above, all currently available web server software logs IP addresses and various other pieces of information about every HTTP request it processes. In order to collect additional information from web users, all a site operator needs to do is code an HTML fill out form and CGI script to process its results. Many form examples and tutorials are available on the web but form processing CGI programming used to be an impediment to some users. Since free services now e-mail responses directly to the form author, even that barrier has been eliminated. That means that setting up a website that collects personal information is now no more expensive than setting up a website that doesn’t. "Cookie" processing, as described above, is slightly more complicated but again free scripts are available on the web and the subject is covered in many introductory programming books.
Storage of the collected information is also very cheap and getting cheaper. Storing the name, social security number, address, phone number, income, birthday, and last 100 pages requested by a user would take approximately 5,000 bytes without any compression. Using data compression algorithms, that number could be as low as 500 bytes. Current prices for hard drives mean that the data for approximately 8000 users can be saved for every dollar spent. In short, the collection and sale of data is easy, cheap, and extremely profitable.
Under the current legal regime – or lack thereof – and the current state of the technology, information essentially "belongs" to whatever entity has access to it. The user has little control over what information is revealed or how it is used, and very often has only the choice between handing over information or not using the Internet at all. In this way, the United States' lack of a legal framework has awarded to website owners an "entitlement" to all information that they can obtain – leaving it to users to "buy back" that information, if they can.
In a perfect market, users would, theoretically, be able to "repurchase" their information so long as the users valued the information more than the website did. In the absence of transaction costs, users would be able to negotiate with each website to persuade that site not to use the data it had collected. Unfortunately, the transaction costs in this instance are huge: users cannot easily coordinate their efforts so as to exploit their market power, websites are not actual "people" and so cannot be negotiated with (leaving the users in a flat take-it-or-leave-it position), the costs of investigating the policies of individual websites are high, and even if a user is able to "repurchase" information from a single website, there will still be a myriad of other websites that the user will have to negotiate with in order to truly "own" his or her information – otherwise, the individual contract formed with the single website is valueless, because other websites will still be able to trade the information freely.
Industry self-regulation has been remarkably unsuccessful in large part because of these basic realities. Though the Federal Trade Commission has long advocated a system of self-regulation and has provided guidelines to industry to assist it in this effort, the FTC reports that fewer than 14% of websites surveyed even posted basic information about their privacy practices, and fewer than 2% actually had developed "comprehensive" privacy policies. The Electronic Frontier Foundation has also noted that despite guidelines issued by the Direct Marketing Association regarding web user privacy, most websites are stubbornly noncompliant. Given the profitability of collecting personal information, as well as the costs of implementing a system of privacy protections, these results are hardly surprising. In fact, whenever a particular company does make basic assurances about protecting users' privacy, it is merely opening itself up to liability should these policies be violated. A perfect example can be found in the Geocities case: Geocities, a large provider of free web space, promised its customers that their data would not be sold to any other entity. As it turned out, the data was sold, and the Justice Department forced Geocities to modify its policies in exchange for dropping the lawsuit. However, rather than simply agreeing to abide by its original privacy policy, Geocities chose instead to discontinue its privacy guarantees.
Some attempts have been made to solve these problems and allow for greater user control over personal information. P3P, described above, is one such proposal. Unfortunately, P3P on its own suffers from the fact that the current "free-market" regime is very beneficial to corporate interests. Commercial websites own the information now – this leaves consumers with precious little to bargain with, and it leaves websites with no incentive to adopt P3P technology. Though, in theory, widespread consumer demand for P3P might entice websites to begin to use it, such coordinated demand is unlikely arise given general consumer ignorance, inertia, and the entrenched commercial interests that have a stake in ensuring the system remains unchanged.
In early 1996, Internet privacy concerns became so great and widespread that the U.S. government began to consider possible legislation regulating privacy practices on the Internet. Businesses on the Internet clearly did not think that this was in their best interest, fearing that governmental intervention would not be researched properly, would be too heavy handed, and would be too strict for businesses desires. Instead, efforts to create privacy self-regulation came about in an effort to head off the need for governmental intervention. After hearing a talk at Esther Dyson's PC Forum in March 1996, Lori Fena, Executive Director of the Electronic Frontier Foundation (EFF), and Charles Jennings, founder and CEO of Portland Software, formed TRUSTe.
TRUSTe is an effort to change the norms with regards to privacy on the Internet. The idea is to create a "trustmark" that can be displayed by websites which acts as a certification to the Internet public. TRUSTe is attempting to create a social norm that dictates if a user visits a site with the TRUSTe trustmark, he should feel confidence in the stated privacy practices of that website. This desire to shift the norms to have people feel secure while using the Internet, specifically while accessing a website that is a member of the TRUSTe organization, is even present in TRUSTe’s trademarked motto: "Building a Web you can believe in." The two key principles that TRUSTe is founded on are that "users have a right to informed consent" and "no single privacy principle is adequate for all situations."
This shift of norms must be accomplished on two fronts: websites must join the TRUSTe organization and abide by their rules, and users must understand what TRUSTe is, what the trustmark means, and desire to access websites with the TRUSTe mark. To join TRUSTe, websites must put together an easily-accessible public description of their privacy practices that is linked to a clearly-displayed TRUSTe mark, and they must agree always to abide by those privacy practices. TRUSTe members then pay a fee proportional to their company’s annual revenue to the TRUSTe organization and thus become official TRUSTe sites. TRUSTe sites are periodically audited by TRUSTe to make sure they are in accordance with the TRUSTe rules and regulations, for it is in TRUSTe’s best interest to promote faith in its mark by ensuring that the websites bearing the mark be truthful and honest.
A TRUSTe site’s posted privacy statement must at a minimum describe seven different areas of that website’s privacy policy. The first section explains what information can or will be gathered about the user (e.g., e-mail address, site pages visited), and the second section clearly identifies the entity that is making the collection . The third section explains how any collected information will be used (e.g., for anonymous, aggregate statistics, for personalization, for ad targeting). The fourth section explains with whom the information might be shared (e.g., only divisions of the company running the site, particular outside companies, the highest bidder). The fifth section describes the "opt-out" policy of the site; this policy deals with those services and collection schemes in which the user may not to participate. The sixth section explains how a user may update or correct any information collected about him. The seventh section explains the "delete/delist" policy. This policy deals with how a user may remove his information or registration from a site.
For TRUSTe to be successful, it must make the Internet public aware of, and watchful for, the TRUSTe mark. Through public dissemination of information, such as that easily accessible at the TRUSTe website, Internet users must be made to have faith that websites will be true to their declared privacy practices. TRUSTe is continuously striving to make people aware of what the trustmark means in an effort to have users desire to use websites with the mark. The aforementioned minimum privacy practices are advertised to the Internet public, as well as the fact that if any TRUSTe member website is in breach of their declared privacy policies, the user should contact TRUSTe to seek action against the website’s publishing organization.
A few key strengths exist in TRUSTe’s proposed plan of self-regulation and manipulation of World Wide Web norms. First, the fact that adoption of TRUSTe is technology independent and does preclude other technological solutions. Anonymization, encryption, and similar technological solutions can coexist with TRUSTe. In fact, P3P provides the possibility for "assuring parties" to mark the privacy practices of a particular website to boost users' faith in the value of their contracts. A second advantage is that, unlike P3P, no new technology is needed to be used by the websites and users. Third, as TRUSTe wishes to maintain the credibility of its mark, TRUSTe will engage in extra effort to audit the TRUSTe websites and ensure that they abide by the rules and guidelines. Finally, TRUSTe claims that it will negotiate the settlement of any breaches of stated policy between a website and user, providing the user a path of recourse if a website does not adhere to its promises. A user might otherwise have no easy remedy against a website who had broken its privacy promises.
However, TRUSTe has many problems, current and potential, that are impeding its effect on the privacy norms of the Internet. For one, it is designed primarily as a solution for businesses to self-regulate and thereby ward off governmental intervention, and as such, many of the fundamental principles of TRUSTe do not apply well to small web publishers. TRUSTe’s proposed solution simply does not make it simple and useful for a private individual or small web publisher to register as a TRUSTe website. In fact, TRUSTe may even raise possible anti-trust issues, as TRUSTe's privacy requirements may act as a barrier to entry in the e-commerce market for smaller companies. An additional detriment to smaller organizations trying to adopt TRUSTe is that it increases the liability of the company. A company would not necessarily wish to subject itself to possibly having to pay fines via TRUSTe for a breach of privacy for actions that, but for its adoption of the TRUSTe mark, are perfectly legal and without penalty.
Another serious problem is that the TRUSTe mark does not mean anything other than that the website adheres to its stated policies – it is not an endorsement of the policies themselves, and the mark itself does not alert the user as to what those policies might be. There is the potential for confusion among users, who might easily understand the mark to signal the presence of a certain level of privacy protection, and who might therefore willingly hand over information to a site with practices abhorrent to the user. When TRUSTe was first launched, it issued three different types of marks signaling associations to standardized TRUSTe privacy policies. However, many websites did not like the codifying scheme, and it was switched to a single mark.
For TRUSTe to be effective, the user must examine the privacy policy of every website visited and determine, case-by-case, whether each website's practices are tolerable. This process is cumbersome and complicated, and most users will not want to be bothered to do it (though such manual checking and rechecking would be greatly reduced through the use of a technology such as P3P). Also, TRUSTe does not allow for any negotiation – users must either accept a site's policies or leave the site. Again, the addition of a technological solution such as P3P would provide some help in this regard.
Though TRUSTe is still largely unknown to Internet users, it recently signed on some very visible sites. Many of the large commercial Internet sites have joined TRUSTe, including America OnLine, IBM, Yahoo!, CNET, and Infoseek. In October 1998, TRUSTe started a special children’s related trustmark, and further dealings with the Federal Trade Commission helped TRUSTe reaffirm its significance. These steps, however, are relatively small and simply not enough. Of the many millions of Internet sites that collect information about their users, only 215 are currently TRUSTe certified.
It is interesting to note that a very similar approach to TRUSTe’s is about to be launched in early 1999 by the Better Business Bureau (BBB). The BBB is attempting to accomplish the same goals as TRUSTe with its own mark, the BBBOnline Privacy Seal. The BBBOnline programs have almost all the requirements and stipulations of TRUSTe, with a few more base level of privacy requirements to join, such that the user has a little bit more reassurance upon seeing the Privacy Seal. BBBOnline, however, will probably be subject to many of the faults of TRUSTe’s attempt at shifting public norms regarding privacy on the Internet.
The future of TRUSTe is bleak. Plagued with numerous problems that inhibit its mass adoption, it is not likely that TRUSTe will have the penetration that is necessary to shift social norms and effect personal privacy on the web. Ultimately, both TRUSTe and P3P suffer from the same problem – the lack of incentive by website owners to adopt strict privacy policies. Both are measures to improve contracting – P3P lowers transaction costs while TRUSTe distributes information – but, as was stated above, web users currently have no assets to contract with. Any information they can offer to a site is generally available to that site without a contract at all, and the web's exponential growth demonstrates that, despite fears about lack of privacy protections, users are willing to risk their personal information for Internet access. Until this state of affairs has changed, there is no reason to expect any proposal that depends on industry initiative, will be widely accepted.
As discussed in the previous section, the current privacy protection framework does not protect individual privacy. In this section we outline a radically different privacy framework where individuals own their personal information and data collectors must contract with users for access to it. We impose sanctions on most uses of an individual's personal information not explicitly authorized by the individual and we suggest a technical solution to the high transaction costs of getting authorization.
We start with the assertion that the current set of entitlements is wrong, from a distributional and efficiency standpoint. From distributional and moral standpoint, we do not believe that there is any justification for allowing personal information to "belong" to a commercial entity merely because that entity has access to it – such a rule, in fact, is analogous to a real-space rule that allows anyone to break into an apartment and steal the television set so long as the homeowner left the door unlocked. Though, given the ease of locking one's door, we might have little sympathy for the homeowner careless enough to fail to take precautions, this does not mean that we have handed over the property rights in the homeowner's possessions to all passers-by. The case for refusing to hand over property rights to information gatherers in cyberspace is even stronger, as, given today's technology, it is virtually impossible for a user to "lock" his or her doors against invasion in the first place. There are also unpleasant distributional effects to awarding commercial websites, rather than individuals, the right to gather information – users, who may be composed of individuals of widely varying economic resources, may, as a group, be less able to afford to make the purchase than would be commercial entities which are, by and large, a better organized and wealthier group.
From an efficiency standpoint, the current set of entitlements is unsatisfactory, for all of the reasons set forth in the previous section. If users are too disparate and widespread a group to effectively coordinate with each other, they cannot easily buy back their information even if they desire to do so and even if such an ultimate allocation of resources would be efficient. Industry, with its superior resources, organization, and information, can most easily initiate requests, determine appropriate "price levels," and generally prevent the harm that comes from unconstrained use of personal information. It is therefore better to grant the entitlement to the user and thus force industry to "reveal" its superior information through the process of contracting.
We propose, therefore, a new legal framework awarding the entitlement of information to the individual, rather than the current system which awards the entitlement to the party which can build the better locks. This framework would set the default rule at privacy for users, with three basic exceptions.
Operational and Aggregated Data
The first exception would be to allow websites to collect that information that is functionally necessary for the communication to occur (in the form of TUIDs) – for instance, the user's IP address for the time it takes to transmit data. The second exception would allow the collection of information held in the aggregate (which would be recorded in the history of TUIDs and also transferred in the form of PUIDs if the user so desires). Because websites often want information about the demographic characteristics of their own users, and because such information represents no privacy threat to individuals so long as all data that would connect the information to a particular person is erased, websites will be permitted to gather this information without users' permission. However, websites would bear the burden of proving that use for aggregation was not individually identifiable.
The final exception would be to allow parties to "opt in" to a less-restrictive system through the use of contract. Our new standard would require that to gather information beyond the exceptions mentioned above, websites first gain the explicit permission of an individual. Further, if the website wants to do more than simply use the data internally – that is, if the website wishes to sell the data to other businesses – permission would also need to be obtained.
Autonomous Computer Contracting Privacy Technology (ACCPT)
The granting of such permission on a case-by-case basis, though legal, would, of course, be extremely unwieldy. Therefore, given this new legal regime forbidding websites to collect information without permission, a technological and legal solution must now be created to allow websites to easily contract into an agreement with a user as to the privacy policy to be used. We call our proposed guidelines for these agreements the Autonomous Computer Contracting Privacy Technology (ACCPT). The Platform for Privacy Preferences (P3P) proposal being developed at the W3C provides an excellent basis for what ACCPT is to try to accomplish and is adopted as the sample technological foundation for ACCPT; the technological structure of ACCPT is simply to be a P3P framework extended and revised with an eye to the legal concerns inherent in agency contracting in order to ensure fair and enforceable contracts. It is worth noting at the outset that for ACCPT to be adopted and work successfully, it must be both very simple for the none-too-savvy user, as well as have a large range of configureability for the power user. This range of ease of use and flexibility will hopefully come about in the research and development of user agents by businesses, independent organizations, and private individuals, as is the intended goal with P3P.
One of the major difficulties, from a legal standpoint, of allowing computerized agents to contract away real users' privacy is the possibility of a disjunction between a user's preferences and the "deals" made by the agent. Where there is no meaningful assent on the part of the user, there is no contract. With no contract, under our proposal, the website is potentially in violation of the law for having used the information without permission. In order, then, to make sure that ACCPT transactions are legally binding – and that they provide protection from liability for websites – we propose that all ACCPT programs operate with a certain degree of transparency. Novice users may not wish to delve into the bowels of the program in order to set their particular preferences, and default settings may be devised for them; however, the ACCPT program must require that the user affirmatively assent to basic aspects of these default profiles, using clear and easily-understood explanations of what the settings actually mean. It is only by this sort of transparency that a user can be said to have truly assented to the contract formed by the agent.
Websites negotiating with agents identifying themselves as ACCPT compliant could, therefore, rely on those contracts as representing the will of the user, whereas they would enter into contracts with non-ACCPT technology at their peril. If the ACCPT agent employed by a particular user then turned out to be faulty in some way – say it was not transparent about its defaults, or did not properly "follow" user instructions – liability for the resulting privacy violations would lie on the maker of the faulty ACCPT technology, using a negligence standard. In this way, websites would have an incentive only to bargain with agents that truly do express the preferences of the user, while programmers would have an incentive to ensure that their products are accessible, and comprehensible, to less-skilled consumers.
P3P contains a number of beneficial characteristics that it would be wise for ACCPT to adopt. ACCPT utilizes P3P's entire flexible negotiation between user and service to contract as to privacy practices. As it is designed for P3P, this flexible negotiation, with possibilities for multiple proposals sent by the service and counter-proposals sent by the user, allows for a good and appropriate agreement to be readily and easily found. P3P's adoption of already defined and used technological standards such as HTTP, XML, and RDF is another benefit worth noting; it is important to use popular standards to promote the adoption of ACCPT solutions by businesses. The use of a harmonized vocabulary is an advantageous step towards universal acceptance and understanding of P3P, and ACCPT proposes to use the same technique, and in fact retain the original vocabulary. Additionally, the open and non-proprietary nature of the development of P3P by the W3C is another important point to maintain in ACCPT, for not only does open development engage well with the developmental nature of the Internet, it helps foster better and more secure technologies as well as further enable and encourage market adoption.
The actual technical differences between the adopted ACCPT base protocol, P3P, and ACCPT itself are small, but important. First, as stated above, ACCPT requires that a certain degree of transparency in its operation to ensure that users do not object to the activities of the agent . Second, ACCPT requires that the individual have some basic digital certification verifying at least key characteristics such as age and relevant geographical location. This is necessary because ACCPT envisions that sovereigns – national governments, local governments, and even parents – may wish to restrict an individual's ability to reveal certain pieces of information. In an effort to enable this possibility, ACCPT will transmit in the TUID of an ACCPT negotiation the location of the user making the negotiation as it is represented in their digital certificate. Upon the beginning of a P3P negotiation, the server would collect the profiles from the necessary sources according to the location of the user. For example, if a user in Pompano Beach, Florida, makes a request from an ACCPT server, the server may be required to retrieve the privacy requirements of the city of Pompano Beach, Broward county, Florida state, and the United States before continuing with the negotiation with the user’s agent. Which profiles the server must retrieve would be dependent upon the location of the user and applicable laws. These profiles would then be used in conjunction with the server’s privacy desires in the continuation of the ACCPT negotiation. The actual ACCPT negotiation would then proceed in the same method as it would under P3P. Ultimately, if the user failed to authorize the release of the geographical (or age-related) data, the website would be required to erase it from its files.
ACCPT would also adopt many of the optional P3P related features. To enable the aggregate collection of information by websites even in the event of failed negotiations, the use of PUIDs and TUIDs as described in P3P will be used by ACCPT in the manner mentioned earlier in the proposal. The creators of user agents will be heavily recommended to make use of propIDs and PUIDs as well as the necessary TUIDs; the use of a storage of a base set of information on the user on the user’s computer such as is possible with P3P will be encouraged as well. The use of propIDs will increase accountability of past formed contracts as well as provide a network to the overall structure, and the use of PUIDs combined with data repositories on the users computers will be very beneficial to businesses due to the desire to collect data on user preferences, in a manner to somewhat similar to, but as a replacement for, cookies. Also, in ACCPT, all propIDs would be digitally signed upon creation to "provide irrefutable evidence of an agreement." Unlike P3P, there would be no fear on the part of the user of unenforceability of the web agreement, for with ACCPT, the trust would lie in the fact that the user knows there are hard legal backings to the ACCPT agreement.
Although the legal and technical framework that we propose as ACCPT has many advantages and benefits, in this section we identify and discuss some of the potential problems with the proposal.
Technical and Legal Complexity Added by ACCPT
Technical Complexity for the Programmer
First of all, although relatively simple, ACCPT does add an additional level of complexity. On the technical side, for example, ACCPT adds considerable technical complexity to the HTTP protocol. Unfortunately, the additional technical complexity could lock out smaller programmers, which, if history is any indication, would probably slow down the rate of development and advancing innovations of the web. Right now, the web is powered by software, written by smaller programmers and academics, and released for free public use and modification. According to a December 1998 Netcraft survey, over half of all web servers are powered by Apache, a free web server written by an ad-hoc group of volunteers.
Complicated protocols can lock out small programming teams from being able to innovate. This might mean that large corporations will dominate the ACCPT compliant agent software market. As the infamous Halloween Memo, an internal Microsoft document, stated:
OSS [free software] projects have been able to gain a foothold in many server applications because of the wide utility of highly commoditized, simple protocols. By extending these protocols and developing new protocols, we can deny OSS projects entry into the market.
ACCPT is an extension of the HTTP protocol and one with complex legal issues at that. Currently HTTP is trivial to implement. Even law student hackers can write HTTP clients without much trouble, particularly with the wealth of free software libraries available to help. Incorporating ACCPT will be more complicated but we expect that similar libraries would be developed following the ACCPT guidelines and that the extra complexity of the ACCPT protocol would eventually be masked from most programmers.
Technical Complexity for End-Users
In addition to the added intricacy on the programming end, ACCPT agents are will require installation, either as part of a browser or separately. Users may be reluctant to set (or even read and accept) their ACCPT preferences.
In counterpoint, however, it would only be fair to recognize that the ACCPT proposal only requires certain settings for installations in order for a website to be certain that a computerized agent is authorized by the user. The installation of most computer programs requires an initial time commitment to set up preferences and the like. Moreover, the protocol could make the process of installing the browser as easy and efficient as possible. Just as the additional technology required by ACCPT can add complications, technology can also eliminate those complications, as we expect it will.
Legal Complexity for Programmers
ACCPT places legal liability for buggy software on small programmers. Although the legal framework is not excessively complicated, it may still discourage small programmers from entering the space for fear of suit. The use of a "negligence standard" may mitigate that effect but application of that standard is unlikely to be easily understood by programmers. The negligence standard is not a standard that is delineated by law or statute, but one that is given its force by the courts, as cases and controversies with concrete facts are decided. Thus, it is really only as problems come up that the standard is fleshed out. Given the importance of the free software movement, it is possible that such an ambiguous standard, with the accompanying penalties, will be highly discouraging to programmers. It is unlikely that they are willing to be guinea pigs for the legal system when they often receive little benefit for making their programs available to the public gratis.
However, such an argument ignores the fact that the ACCPT legal framework proposed is actually simpler than the legal framework that now exists. The current legal framework is a patchwork of industry-specific statutes and difficult-to-follow common law which varies by state. The main innovation of ACCPT is the "flipping" of the entitlement to information. Rather than the automatic disclosure of information, with the burden on the user of the site to negotiate with the site in order to regain his or her information, ACCPT would help the user to "own" his or her information, requiring the site to negotiate with the user for access to the information. Rather than adding a layer of legal complexity, ACCPT may be better analogized to an inversion of the current framework. Moreover, the complexity of the "legalese" can be minimized by those who write the law. Given the alternative mosaic of common law rights and industry specific statutes, of which it is unlikely that programmers are any more aware, the more comprehensive and general legal backdrop proposed by this paper is preferable.
Legal Complexity for End-Users
Aside from the legal complexity presented by ACCPT to programmers, there may also be residual effects on end-users. Under ACCPT, users are allowed to customize privacy preferences in extreme detail. Upon installation, the user may feel overwhelmed by "legalese," and may be discouraged from participating in on-line transactions altogether. In an analysis of P3P, this same problem was cited. Citibank expressed their opinion that:
>From a consumer standpoint using P3P may be quite confusing, as the user may feel inundated with "legalese" and too many choices. . . . The user may feel inundated with too many choices about too many pieces of information when configuring P3P. If the user does not choose to fill in the information beforehand, there will be a point when the user is transacting with a website operator, that he/she would need to fill in that information. The user would then have to decide under what sort of conditions he/she would like to have personal information given out. . . . Nevertheless, there is a possibility that P3P will discourage neophytes from transacting or interacting online altogether.
In reality, we believe that proper user interface implementation can avert this problem. Most browsers will probably lump privacy settings into large, easily understandable groups, and only advanced users will engage in further customizations. Furthermore, the facilitation of collective privacy choices through the APPEL-like functionality of a well designed ACCPT agent will allow users to use settings constructed by groups instead laboriously constructing their own.
Also important to note is that fact that the technical complexity added by ACCPT may have unintended secondary effects on public access. For instance, many schools and libraries have public access web terminals. It would be unwieldy for each user to customize the ACCPT preferences on these machines. At the same time, without ACCPT, users may not be able to view a potentially large part of the content on the Internet. ACCPT may make be sacrificing some amount of public access for the sake of flexibility.
Services for the remote storage of ACCPT profiles should arise to solve this problem in much the same way Yahoo currently stores many people’s calendars. This would again make use of our proposal for APPEL-like language for transferring privacy preferences.
An additional problem with the use of ACCPT is the network traffic that it would create. Due to the necessary negotiation that must occur before a user can access data from a website, more data must be transmitted back and forth to a website before a user can gain access to it creating both a noticeable delay in the time it takes to initially receive information from a website, as well as an over all increase in the amount of data that it will create in general. This overall increase in data transmission will in fact slow down other users on the Internet as well especially at points of low bandwidth. This problem would be further exacerbated by ACCPT's use of regional profiles to enforce legal standards due to the even further elevated level of necessary network traffic. This problem, however, may become moot in the future as the average Internet user's bandwidth increases at the same rate it has in the past.
While the above criticisms constitute commentary about the problems with the implementation of our proposal for ACCPT, legitimate objections may be made in that perhaps ACCPT does not go quite "far enough." Though ACCPT has addressed many of the problems in government policy towards the protection of information, other areas of concern also exist which we have not fully addressed.
International Conflict of Laws
A major limitation of our proposal is its domestic nature, when the problem with information privacy is a global one. Most likely, not all nations will pass laws requiring or even supporting ACCPT. Since the ACCPT proposal does not require its international adoption – though we would welcome it –international websites could lie about the level of privacy they provide without there being an easy recourse for consumers. Some nations could provide safe haven for websites that wished to collect information without accepting limitations on its use. As long as other countries can break ACCPT contracts without repercussions, then the proposal may be adding very little in the way of protection of privacy. The U.S. government can "forbid" users to contract away data without particular guarantees if it so chooses, but if the other end of the party breaks the deal, there is no recourse. Some argue that a completely technical solution may be the only way to deal with this problem.
However, a "complete technical solution" cannot be the only answer to the question. As with our proposal, the problem is that technology doesn't exist in a vacuum -- there must be legal standards in place to encourage the adoption of the technology. This is particularly true on the international level, where other countries might actively pass laws preventing its adoption. On the other side, this is also a question of sovereignty – treaties, conflicts of law principles, and the like step into the gaps, just as in "real world" conflicts. Granted, technology may provide a partial solution. If the United States adopts a code-based solution, it is likely that Europe will follow. Since packets go through several routers in the U.S., it will guarantee at least partial privacy for U.S. citizens.
If TCP/IP is modified in such a way that websites cannot collect IP addresses, electronic payment is completely anonymous and shipping is completely anonymous, no companies could collect personal information. If anonymizing routers were implemented as part of IPv6, countries would have to adopt it to avoid being cut off from the rest of the Internet. Regardless, ACCPT does not preclude the additional protection of a code-based framework to protect privacy.
Another criticism of ACCPT is that it does not address the collection of "public" information into detailed profiles. Currently, much information is available for legal collection. There is no current U.S. provision, nor is there any provision in ACCPT, to prevent the selling of this information. An individual or organization is legally allowed to collect information from the United States postal system, phone directories, tax information, family lineages/geneologies, real estate records, as well as collecting all posts, web pages, or any other on-line "traces" made by individuals.
This problem is one that should definitely be considered by the legislature and courts. Even if ACCPT becomes widely accepted, it is indisputable that such endeavors would be still technically be legal, yet may be a more serious violation of privacy than a website keeping a record of IP addresses. Surely ACCPT will slow the collection and use of this data as ownership would have to be established and the information collected without any help from the individual being profiled. However, ACCPT does not retrieve information currently public nor regulate the collection of information about users in the real world.
Another problem with a legal structure that prevents collecting any information without permission is that of data that needs to be collected for normal server operations. Although the law includes provisions the collection of operational data for use in fulfilling transactions (IP addresses used to send requested pages), frequently, servers need or want to collect additional operational data for security purposes. Currently, the operational use exception does not include security use under our proposal. Indeed what would constitute a legitimate security use is unclear. Presumably, an officer with a warrant could obtain the operational logs in spite of a user’s privacy interest in them. However, though there was significant discussion over the tradeoff between privacy and accountability, our proposal errs on the side of privacy and does not provide a specific security use exception.
If introduced, anonymous browsing, shipping, and payment technologies may make a potential security use exception much less important as much operational data could be revealed with minimal privacy loss. Our proposal encourages further work in these areas.
Finally, a potential problem unaddressed by our proposal is that ACCPT may not result in a diversity of privacy policies if various websites collude. This may become especially problematic if the websites only allow access to their pages upon the disclosure of information; if a "floor" develops, such that all pages require a minimum of information, then the privacy of users may not be significantly protected by ACCPT. This is an issue which we recommend government closely monitor. In the event that a floor on information does develop, Congress may reanalyze the issue, perhaps distinguishing between information which can be exchanged and information that is inalienable.
Philosophical Criticisms of ACCPT
In addition to the various criticisms thus far discussed, there are several debates which occur at a more basic level. ACCPT is based upon the acceptance of several assumptions and basic beliefs about privacy. Yet, there are various other frameworks within which alternative proposals could be suggested.
An even more extreme view is that there is no need at all for data collection. Despite the initial impressions, there are a fair number of arguments made in its favor. First, while data collection may bring in a significant amount of revenues, e-commerce may actually increase with a prohibition against collection of data. Second, the argument maintains that most respectable websites do not engage in privacy violations; thus, the only sites it would potentially harm provide minimal positive value to society. Moreover, larger revenues do not necessarily lead to good content. Many websites with quality content are created by people interested in more than money, such as public interest organizations, musicians, academics, etc., more so than content from overcommercialized sites. Rather than simply encouraging growth and more content on the Web, perhaps we should be encouraging better quality or discouraging the minimally beneficial websites. Finally, marketing and data collection uses resources, but contributes little of substance back to society. In the long run, if human resources are reallocated from data collection or marketing to productive work, the output and average standard of living for society as a whole may rise. Although in the short run, this may hurt e-commerce, it may help other industries just as much in the long run.
An Internet where data collection was prohibited is some people’s view of a Utopian cyberspace. However, our proposal took a different stance because we believe that the technology is not mature enough for this to be practical goal. Furthermore, we recognize that different people have different privacy concerns and would be best served by different privacy policies. Thus in fulfilling our goals of protecting individual privacy but also enabling electronic commerce and encouraging a diversity of privacy policies, we took a more moderate approach.
On the opposite side of the spectrum, there are advocates for the philosophy that there should be little to no regulation of data collection and storage. The argument assumes that as long as the information is obtained legally, i.e. no trespass or fraud is involved, then the user has no more power over what is done with that information. The basic assumption underlying this theory is about entitlements – if a website has the technological ability to obtain information about the user, then the website owns that information.
For the advocates of this argument, the force comes from the First Amendment. In support of the theory that collectors of legally obtained data can do whatever they like with that data, some have argued that the primary constitutional issue is free speech, rather than privacy; once information is freely released, any restrictions on corporate speech, such as customer lists, should be disfavored. However, the ACCPT proposal does not present an absolute ban on the speech. Instead, it suggests that the government implement constitutionally permissible "time, place, and manner restrictions" – that the government simply regulate the manner in which this "speech" is conducted.
More importantly, this seems to be a misleading application of the First Amendment. Rather than the right to free speech, it seems more closely analogized to the limited right to appropriate or use other people's speech – in this case, an individual’s private information. Copyright, trademark, and patents are all examples of instances where the government has legitimately stepped in to protect the rights of the original "speaker." Alternatively, ACCPT can be seen as an extension of the government's right to regulate interstate commerce. Given that the most vocal proponents of this structure of "less regulation" are from the direct marketing camp, it is unlikely that they would deny that interstate commerce is involved.
Moreover, a world with this structure would degenerate into a cat-and-mouse game, with the user trying to technologically stay one step ahead of commercial websites. And this is a game that most users of the web are likely to lose, given their lesser resources and access to technological innovations, as well as problems with collective action.
The introduction of this paper discussed Alfred, the hypothetical web surfer. In the sections that explained the current technical, legal, market and social norm frameworks we saw how Alfred’s privacy could be violated in surprising ways. We saw that Alfred could be tracked by IP address or cookie and information given to one site could be easily correlated with his name and address given to another. In the market and social norms section, we saw that the technology to collect, store, analyze and share Alfred’s information was cheap. We also saw that although people are concerned about their personal privacy online, Alfred was likely to give up his information anyway. Finally, in the legal section explained that Alfred’s video rental receipts are likely to receive more privacy protection than his concerns over prostrate cancer. We discussed P3P and TRUSTe as potential solutions to Alfred’s privacy problems but saw that the background legal and technical regimes prohibit the success of both of these potential solutions.
In response, we proposed the ACCPT legal framework and technical guidelines. These would ensure that Alfred would be aware of the way in which his private information might be used before he agreed to divulge it. If Alfred didn’t want his visit to ProstrateInfo.Com to be logged or given to other entities, he could either come to that agreement with ProstrateInfo.Com, or find another site that would agree to those terms. However, as discussed in the critique section, Alfred’s privacy comes at a price. Companies will need to be more careful about how they handle information. Individuals will need to install agents and assent to their defaults. Web sites will open themselves to liability for the using information in ways that currently do not carry any potential penalty. Computer programmers wanting to write browsers with ACCPT compliant agents will find it technically more challenging and also open themselves up to potential liability which is not present under the current framework. Furthermore, our proposal does not solve thorny internationalization issues or completely eliminate profiling.
Privacy regulation is a balancing act. This proposal strikes that balance in favor of the individual. ACCPT protects individual privacy while enabling electronic commerce and providing a new market for information where the players are on more even ground. ACCPT attempts to enfranchise everyone, not only the rich or tech-savvy. Furthermore, ACCPT is flexible enough to encourage diversity in implementation and privacy policies while still allowing collective action.
As the Information Revolution chugs on its course, the United States has demonstrated an extreme reluctance to offer legislative guidance as to how it should proceed. Other than pledging protection for its own records, and enacting a few stop-gap protection measures that correspond to the day's headlines, the federal government has adhered to its rosy view of industry whereby a few fierce words from an extremely pro-business administration will prompt businesses to forego an extremely easy and profitable activity. If it was not clear before now that such an approach had little likelihood of success, the FTC's report to Congress should have been the final nail in the coffin of the idea of self-regulation.
America's reluctance to take drastic action may not be entirely predicated on the influence of moneyed interests in Washington. The United States has a very long tradition of freedom of information, and that norm might be one that legislators are reluctant to disturb. It is a shocking thing to say in America, "You have access to the knowledge, but you cannot use it." Though it would not be the first time such a thing was done – as was mentioned earlier, we have protection for copyrights, for trade secrets, and a host of other intellectual properties – ultimately what we are proposing to protect here is information that an individual parts with in the real world on a daily basis, without any expectation that that such information will be controlled. Our names, our addresses, our phone numbers, our favorite television shows, our buying habits – we simply are not used to thinking about these things as "private." When we see, however, the potential harm caused by the unrestricted flow of this information in vast databanks, it becomes clear that our traditional ideas about privacy must be radically altered to fit this new world.
Our proposal is the first step in this process – it is intended to function as a redefinition of what information is private. This is a context-sensitive redefinition: if the man at the newspaper stand on the corner remembers that Alice buy the Washington Post every morning, that is not a privacy violation – but if Altavista "remembers" this information without her consent when Alice searches for the Post online, or DoubleClick remembers it because DoubleClick hears through Altavista, or Barnes & Noble remembers it because Alice followed a link to its website – these are, indeed, violations of her privacy. The problem certainly extends beyond the web – we are living in an age where vast stores of data about every person in this country are freely available, by going down to the courthouse, or a Hall of Records. Without a workable, context-sensitive definition of privacy, our willingness to make those records available publicly on paper will translate to a willingness to make those records available publicly in electronic form – which, because of the ease with which electronic records can be accessed and searched, may very well have a qualitatively different meaning of "public" than was present in the case of a public record in a file in a cabinet in the basement of City Hall. Our proposal lays the groundwork for this new understanding variations of "public" and "private" depending on who has access to the information, how it is used, and how much control the individual has over it, but there is still much to be done. We must alter our understanding of "public" and "private" from how these terms were meant 200 years ago, when basic decisions about the structure of our legal architecture were made, to what those terms mean now, when our technological architecture has reached a place that no one could have envisioned when the rules were created. As the web and use of computers continues to grow, the importance of this process cannot be underestimated – and it requires more direction from our government than a simple hope that ultimately, everything will work itself out. Our proposal has the courage to take a stand and suggest ways that the government can help to protect personal privacy. We answer Al Gore’s challenge for an electronic bill of privacy rights – the only question now is whether government will have the courage to follow.
Appendix A: Table of Proposed Legislation
During the 105th Congress
Protection of Children
|
H.R. 1972 Children's Privacy Protection and Parental Empowerment Act of 1997 Prohibits "list brokers" from selling, purchasing info about children without written consent of parent. Requires marketers to give access about child to parent, prohibits using prison inmate labor to process children's' information. Requires marketers to give lists to National for Missing and Exploited Children for data matching purposes. The bill has 52 cosponsors. |
|
H.R. 2368 Data Privacy Act of 1997 Interactive computer services may not collect any information about a child or disclose this information without notifying the child, in advance of collection or use, that the child should not provide any information without the consent of his or her parent. No person shall solicit or collect information from a child regarding his or her parents. Part of a more comprehensively conceived protection. |
|
H.R. 2815 Protecting Children From Internet Predators Act of 1997 Criminalizes sending sexually explicit messages to people under 16, even if sender is under that age. |
|
H.R. 3494 Child Protection and Sexual Predator Punishment Act of 1998 Criminalizes sending sexual material to a minor. Minimum prison term for using computer is 3 years. Allows use of subpoenas to obtain evidence instead of warrants. |
|
S. 504 Children's Privacy Protection and Parental Empowerment Act of1997 Prohibits the sale of personal information about children without their parents' consent. |
|
S. 1965 Internet Predator Prevention Act of 1998 Prohibits the publication of identifying information relating to a minor for criminal sexual purposes. |
|
S.1987 Child Protection and Sexual Predator Punishment Act of 1998 Increases penalties for transmitting obscene materials to minors, contacting minors using net "for the purpose of engaging in any sexual activity". |
Protecting Personal Identification Data
|
H.R. 98 Consumer Internet Privacy Protection Act of 1997 Interactive computer services may not disclose personally identifiable information provided by their subscribers to third parties without subscriber's written consent, which may be revoked at any time. Upon subscriber's request, service must provide the subscriber's personally identifiable information maintained by the service to the subscriber for verification and correction purposes. Upon subscriber's request, service must inform the subscriber of the identity of the third party recipients of the subscriber's personally identifiable information. Additionally, this act would prohibit knowing disclosure of falsified information. |
|
H.R. 1287 Social Security On-line Privacy Protection Act of 1996 Interactive computer services may not disclose Social Security account numbers or personal information that is identifiable to an individual by means of his or her Social Security number without the individual's written consent, which may be revoked at any time. See "Regulating On-Line Databases." |
|
HR 1330 American Family Privacy Act of 1997 Prohibits Federal officers and employees from providing access to social security account statement information, personal earnings and benefits estimate statement information, or tax return information of an individual through the Internet or without the written consent of the individual, and to establish a commission to investigate the protection and privacy afforded to certain Government records. |
|
HR 1331 Social Security Information Safeguards Act of 1997 Requires the Commissioner of Social Security to assemble a panel of experts to assist the Commissioner in developing appropriate mechanisms and safeguards to ensure confidentiality and integrity of personal Social Security records made accessible to the public. |
|
H.R. 1367 Federal Internet Privacy Protection Act of 1997 Federal agencies may not make available through the Internet any record with respect to an individual. For the purposes of this act, records include information with respect to education, financial transactions, medical history, or employment history that contains the name or identifier assigned to the individual. |
|
H.R. 1813/S. 600 Personal Information Privacy Act of 1997 Persons may not buy, sell, or trade Social Security account numbers or use social security account numbers for identification without written consent of the individual. Individual must be informed of all purposes for which the number will be used and all persons to whom the number will be known. |
|
H.R. 2368 Data Privacy Act of 1997 This act creates an industry working group to establish guidelines to limit the collection and commercial use of personally identifiable information obtained from individuals through any interactive computer services. The guidelines shall apply to those Providers or persons who voluntarily agree to such applicability. These guidelines shall require interactive computer services to inform subscribers of the nature of the information collected and allow subscribers to prevent disclosure of this information. Upon subscriber's request, service must provide the subscriber's personally identifiable information maintained by the service to the subscriber for verification and correction purposes. Part of a more comprehensively conceived protection. |
|
H.R. 2581 Social Security Privacy Act of 1997 Limits use of Social Security number. Requires disclosure of uses of SSN by businesses. |
Protecting Medical Records
|
H.R.1815 Medical Privacy in the Age of New Technologies Act of 1997 Protects the privacy of health information in the age of genetic and other new technologies. |
|
H.R.2198 Genetic Privacy and Nondiscrimination Act of 1997 Would limit use and disclosure of genetic information by health insurance companies; prohibit employers from attempting to acquire, or to use, genetic information, or "to require a genetic test of an employee or applicant for employment" or to disclose the information. |
|
HR 2215 Genetic Nondiscrimination in the Workplace Act Amends Fair Labor Standards Act to restrict employers in obtaining, disclosing, and using of genetic information. |
|
HR 2216 Genetic Protection in Insurance Coverage Act Limits the disclosure and use of genetic information by life and disability insurers. Prohibits insurers from requiring genetic tests, denying coverage, setting rates based on genetics, using or maintain genetic info. |
|
H.R. 2368 Data Privacy Act of 1997 No person may use, for commercial marketing purposes, any personal health or medical information obtained through an interactive computer service without prior consent of the individual. No person may display the social security account number of an individual, through the use of an interactive computer services, except when part of a government record available to the general public or pursuant to industry guidelines. Part of a more comprehensively conceived protection. |
|
H.R. 3755 Prescription Privacy Protection Act of 1998 Restricts disclosure of pharmacy records. |
|
H.R.3900 Consumer Health and Research Technology (CHART) Protection Act A bill to establish Federal penalties for prohibited uses and disclosures of individually identifiable health information, to establish a right in an individual to inspect and copy their own health information, and for other purposes. Allows disclosure to government without warrant and researchers with little need. |
|
H.R. 4250 Patient Protection Act of 1998 Republican Health Care bill. Sets weak standards for privacy, prohibits states from passing stronger protections. Approved by the House 216-210 on July 24. |
|
S. 89 Genetic Information Nondiscrimination in Health Insurance Act of 1997 Prohibits denial of insurance based on genetic information. Prohibits insurance companies from requesting genetic information. Prohibits disclosing genetic information without written consent. |
|
S. 1368 Medical Information Privacy and Security Act General medical privacy bill. |
|
S. 2352 The Patient Privacy Rights Act Repeals the "unique medical identifiers" requirement of the Health Insurance Portability Law of 1996 (HIPAA). |
Regulating Direct Marketing and Unsolicited E-Mail
|
HR 1748 Netizens Protection Act of 1997 Persons may not send unsolicited advertisements to an electronic mail address of an individual with whom they lack a pre-existing or ongoing business or personal relationship, unless the individual provides express invitation or permission. Persons may not send unsolicited advertisements without providing the identity and the return electronic mail address of the business or individual sending the message at the beginning of the unsolicited ad. |
|
H.R. 2368 Data Privacy Act of 1997 Persons may not send unsolicited advertisements without providing the identity, the physical address, the electronic mail address, and the phone number of the initiator of the message. The business or trade name must appear in the subject line of the message. The guideline must provide a method by which an individual may choose to prohibit the delivery of unsolicited commercial electronic mail. Part of a more comprehensively conceived protection. |
|
H.R. 4124 E-Mail User Protection Act of 1998 Anti-Spam bill |
|
H.R. 4176 Digital Jamming Act of 1998 Anti-spam bill. |
|
S. 771 Unsolicited Commercial Electronic Mail Choice Act of 1997 Persons sending unsolicited electronic mail advertisements must include the word "advertisement" in the subject line of the message and include the sender's electronic mail address, physical address, and telephone number in the body of the message. Interactive computer services must provide a system for blocking any electronic mail that contains the word "advertisement" in its subject line and inform its subscribers of this service. Once such a blocking system is in place, interactive computer services must block unsolicited advertisements at the request of the individual subscriber and may block these advertisements upon its own initiative. |
|
S. 875 Electronic Mailbox Protection Act of 1997 Persons may not transmit unsolicited electronic mail messages from an unregistered electronic mail address or disguise the source of unsolicited electronic mail messages. Persons may not send unsolicited electronic mail to individuals who have requested no further messages and may not distribute that individual's electronic mail address to others who intend to use the address for sending unsolicited electronic mail. Persons may not send unsolicited electronic mail messages in contravention of the rules of an interactive computer service or access the server of such a service to collect the electronic mail addresses of its subscribers for the purpose of sending unsolicited electronic mail advertisements. |
Regulating On-Line Databases
|
H.R. 1226 Taxpayer Browsing Protection Act Criminalizes "browsing" of taxpayer files by IRS employees. Passed by the House April 15, 1997. Placed on the Calendar in the Senate (CR S3346) on 4/17/97. Signed August 7, 1997 (PL 105-35). |
|
HR 1287 Social Security On-line Privacy Protection Act of 1996 Prohibits computer service (such as Lexis-Nexis) from disclosing person's SSN without permission. See "Protecting Personal Information." |
|
H.R.2652 Collections of Information Anti-Piracy Act Creates property right in databases of information, even if public domain information. Approved by House on voice vote on May 19. Referred to Senate Judiciary Committee. |
|
S.2291 Collections of Information Anti-Piracy Act Creates new form of intellectual property for databases. Unfortunately, does not protect individuals from whom information is collected, except from 3rd parties who would misappropriate database from collector. |
Appendix B: Example P3P Proposal
The following code should be placed in your default Web site page. This HTML proposal will allow your visitors' browsers to read and understand the human readable proposal which follows it.
<PROP
agreeID="d273e4b4dc86577621ad58feaea0704e"
realm="http://web.mit.edu/draco/www/group3/"
entity="Group3-privacy">
<USES>
<STATEMENT
VOC:purp="0,1,2,3"
VOC:recpnt="0"
VOC:id="0"
consq="It will help us better serve your interests as you browse our website.">
<DATA:REF
category="1"/>
<WITH>
<PREFIX name="User.">
<DATA:REF name="Home.Online.Email"
category="1"/>
<DATA:REF name="Home.Online.URI"
category="1"/>
<DATA:REF name="Business.Online.Email"
category="1"/>
<DATA:REF name="Business.Online.URI"
category="1"/>
</PREFIX>
</WITH>
</USES>
<USES>
<STATEMENT
VOC:purp="0,1,2,3"
VOC:recpnt="0"
VOC:id="1">
<DATA:REF
category="4"/>
</USES>
<USES>
<STATEMENT
VOC:purp="0,1,2,3"
VOC:recpnt="0"
VOC:id="0">
<WITH>
<PREFIX name="ClickStream.">
<DATA:REF
name="Client_"
category="5"/>
</PREFIX>
</WITH>
<WITH>
<PREFIX name="Form.">
<DATA:REF
name="StoreNegotiation_"
category="6"/>
<DATA:REF
name="SearchText_"
category="6"/>
</PREFIX>
</WITH>
<DATA:REF
category="9"/>
</USES>
<VOC:DISCLOSURE
discuri="http://web.mit.edu/draco/www/group3/privacy-policy.html"
access="3"
other-disclosure="0,1">
<ASSURANCE org=""/>
</PROP>
Group3-privacy's Privacy Statement
Group3-privacy makes the following statement for the Web pages at <http://web.mit.edu/draco/www/group3/>. This is the human readable version of the above P3P proposal.
Online Contact Information
Group3-privacy may collect the following data regarding a user's home:
an e-mail address or a URI.
Group3-privacy could collect information regarding a user's business:
an e-mail address or a URI.
Group3-privacy makes a statement regarding how a user might benefit by providing this information:
"It will help us better serve your interests as you browse our website."
Group3-privacy uses this information for the purposes of completion and support of current activity, Web site and system administration, customization of a Web site to an individual and research and development.
This information may be distributed to ourselves and our agents.
Computer Information
We collect information about a users computer system and associate this information with other identifiable information collected from the user. Group3-privacy uses this information for the purposes of completion and support of current activity, Web site and system administration, customization of a Web site to an individual and research and development.
This information may be distributed to ourselves and our agents. Moreover, this information could be used in such a way as to personally identify a user.
Clickstream and Navigation Data Information
Group3-privacy may collect the following types of passively gathered data: click stream data collected on the server. Group3-privacy uses this information for the purposes of completion and support of current activity, Web site and system administration, customization of a Web site to an individual and research and development.
This information may be distributed to ourselves and our agents.
Transaction Data
Group3-privacy may collect the following types of information generated through explicit transactions (i.e. search queries): stored negotiation history data or search query data. Group3-privacy uses this information for the purposes of completion and support of current activity, Web site and system administration, customization of a Web site to an individual and research and development.
This information may be distributed to ourselves and our agents.
Content Data
Our Web site contains elements that would allow a user to communicate with another user or to post information so that others may access it at http://web.mit.edu/draco/www/group3/. Group3-privacy uses this information for the purposes of completion and support of current activity, Web site and system administration, customization of a Web site to an individual and research and development.
This information may be distributed to ourselves and our agents.
General Disclosure
No user access to identifiable information is given.
Group3-privacy makes a disclosure in our policy posted at http://web.mit.edu/draco/www/group3/ regarding the capability for a user to cancel or renegotiate an existing agreement at a future time.
Group3-privacy makes a disclosure in our policy posted at http://web.mit.edu/draco/www/group3/ regarding how long data is retained.