 Isologs are proteins that perform functionally equivalent roles in different species. By emphasizing both sequence similarity and functional similarity, isologs are intended to address some of the shortcomings of traditional sequence-only orthology-prediction approaches.
Isologs are proteins that perform functionally equivalent roles in different species. By emphasizing both sequence similarity and functional similarity, isologs are intended to address some of the shortcomings of traditional sequence-only orthology-prediction approaches.
We evaluated the biological relevance of our results against the Gene
Ontology database (GO).
We first measured the consistency of the predicted network alignment by computing the mean entropy of
the predicted clusters. The entropy of a given cluster S*v is:
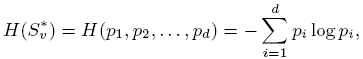
where pi is the fraction of S*v with GO group ID i. Thus a cluster has lower entropy if its GO annotations are more within-cluster consistent. We also measured the fraction of clusters which are exact, i.e. those in which all proteins have the same GO ID. With regards to choosing a set of proper GO annotations, we projected all GO terms to the same level of the GO heirarchy (k=5), removing questions of generality of terms and relatedness of annotations having different IDs. Note that only 60-70% of the proteins in any of the aligned networks have an assigned GO ID, comparable to the fraction of all known proteins included in GO. Additionally the relative performance of this consistency measure does not change when projecting GO terms to GO heirarchy levels of k=4, k=5, or k=6.
| Consistency | IsoRank & IsoRankN | Homologene | OrthoMCL |
|---|---|---|---|
| Mean normalized entropy (all species) | 0.086 | 0.262 | 0.206 |
| Mean normalized entropy (human, fly) | 0.066 | 0.298 | 0.260 |
| Exact cluster ratio* | 0.250 (1752 of 7010) |
0.232 (1805 of 7769) |
0.220 (794 of 3602) |
| Exact protein ratio* | 0.253 (7488 of 29636) |
0.288 (5196 of 18057) |
0.270 (1996 of 7387) |
| *The fraction of predicted clusters which are exact, fraction of proteins in exact clusters. | |||
| Coverage* (# of species) | IsoRank & IsoRankN | Homologene | OrthoMCL |
|---|---|---|---|
| Total | 12848/48978 | 11746/22527 | 10008/27601 |
| 2 | 3844/8739 | 5584/11151 | 2576/5213 |
| 3 | 4022/13533 | 1940/5801 | 638/2016 |
| 4 | 2926/13991 | 1652/6615 | 470/1977 |
| 5 | 2056/12715 | 745/3729 | 366/1931 |
| *The number of predicted clusters containing exactly # species and number of constituent proteins in those clusters (#cluster / #proteins) | |||
| GO/KEGG | IsoRank & IsoRankN |
|---|---|
| p-value* | 1.28 e-90 |
| GO/KEGG category | 712/2490 |
| Human | 632/2200 |
| Mouse | 605/2124 |
| Fly | 574/1787 |
| Worm | 552/1698 |
| Yeast | 368/938 |
The number of GO/KEGG categories enriched by IsoRank & IsoRankN. *As computed by GO TermFinder, we remark that this excludes those proteins tagged IEA (inferred from electronic annotation). |
|


